- nebula 版本:nebula 2.0 GA
- 部署方式(分布式 / 单机 / Docker / DBaaS):单机
- 硬件信息
- 磁盘( 推荐使用 SSD)500G
- CPU、内存信息 40C 126G
- 问题的具体描述
你好,我们公司使用nebula图数据库存储我们的业务数据,使用了多个导入程序来向nebula导入数据,为了维护这些导入程序的导入状态的一致,选择在nebula上新建了一个space和tage用来存储各个导入程序的导入状态,每个导入状态对应一个vertex,各个导入程序周期性更新导入状态vertex的ttl,当前ttl过期时间是10s,更新频率是2s一次,但是在开启导入程序后近两个小时左右,导入状态vertex还是过期了,导致继续更新ttl报错( response error code: E_EXECUTION_ERROR, message: Storage Error: Vertex or edge not found),这个现象有点让人迷惑,烦请帮忙定位下原因。
除了会有个独立线程周期更新ttl外,还有业务线程会去update导入状态vertex的其他字段,并发update同一个点会存在某个update失败的问题吗?
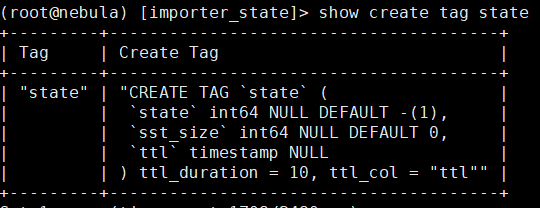
导入状态的space和vertex schema:

更新ttl使用的update语句:
UPDATE VERTEX ‘global_state’ SET state.ttl = now();
