最近有些小伙伴在使用 Nebula 导入数据的时候遇到了一些问题,这里官方整理了数据导入的相关事项,以供以后的大家导入数据参考。
本帖目录
-
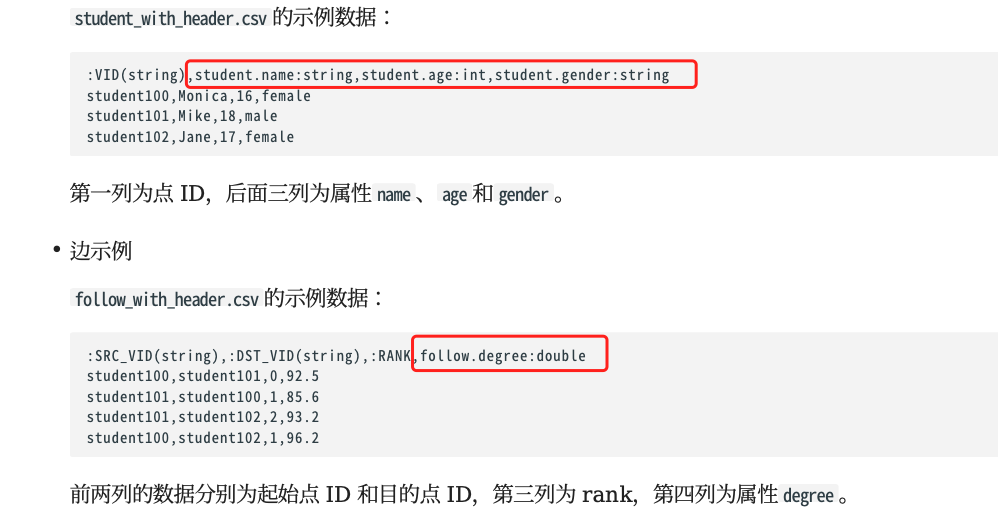
导入数据报错:ErrMsg: SyntaxError: syntax error near xx,不支持这种类型的顶点 ID
-
没有 header 的情况下如何导入数据
-
string 通过 hash 转化为 int 的耗时问题
-
数据导入是并行的吗?
-
graph client 数据设置问题
-
查看导入数据的有多少个顶点或边
-
导入的时候,Latency AVG、Batches Req AVG、Rows AVG 这三个参数的意思
-
导入数据的时间及机器配置问题
-
storaged 配置文件更改生效问题
-
导入 shell 关闭数据,导入会停止吗?
-
如何查看导入进度
-
导入点边数据有先后顺序吗,还是随机的?
-
导入工具支持断点续传吗?
导入数据报错:ErrMsg: SyntaxError: syntax error near xx,不支持这种类型的顶点 ID
Question:导入的时候报错:ErrMsg: SyntaxError: syntax error near xx,是不支持这种类型的顶点 ID,只支持 int 型?

Answer:是的,顶点类型只支持 int64。如果 vid 的那列是 string,可以在 vid 的配置中指定 function: hash 或者 uuid,导入时会自动使用对应的函数来转换成 int64 的 vid
没有 header 的情况下如何导入数据
Question:如果要导入的数据没有 header,怎么忽略其中某列数据不导进去?只在官网看到有header情况下的说明
Answer:对每个 tag 的 props 指定数据文件中的列 index,没有用到的那些列自然就被忽略掉了
string 通过 hash 转化为 int 的耗时问题
Question:VID 列为 string,这个 string 通过 hash 转化为 int64 的耗时,是算在整个导入耗时里面吗?
Answer:嗯。 你可以这么理解,就是把 INSERT VERTEX v() VALUES 234: () 变成 INSERT VERTEX v() VALUES hash("234"):() 语句
数据导入是并行的吗?
Question:数据导入是并行导入的吗,是不是这个 graph client 决定并行度呀
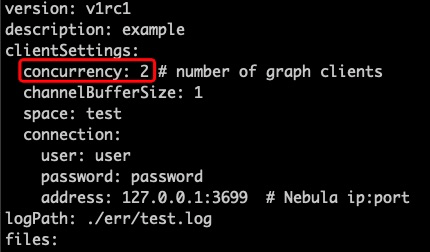
Answer:数据导入是并行的,这个 concurrency 指定为你的 cpu cores 就可以。表示的是起多少个 graph client 去连接 nebula server。
graph client 数据设置问题
Question:graph client 按理说设大一些就导入更快一些,是吧
Answer:是,但是也不是越大越好,根据你本地机器的 cpu 核数一样就行。
查看导入数据的有多少个顶点或边
Question:有接口能获取图里有多少个顶点或边吗?
Answer:没有直接的命令,但是有工具:https://github.com/vesoft-inc/nebula/blob/master/docs/manual-CN/3.build-develop-and-administration/3.deploy-and-administrations/server-administration/storage-service-administration/data-export/dump-tool.md 。它也可以只是做统计,有不同的选项。
--mode=stat #只做统计
导入的时候,Latency AVG、Batches Req AVG、Rows AVG 这三个参数的意思
Question:导入的时候,Latency AVG、Batches Req AVG、Rows AVG 这三个参数的意思

Answer:这里的 latency 是每条 insert 返回的 latency 的平均,类似于你在 console 中执行时返回的 latency。Finished 表示总共完成的条数, Batches Req AVG 表示设置的 Batch 数据导入的时间,比如,你设定 batch 为 100 条,即,导入 importer 执行一条插入命令会有 100 条数,这 100 条数据插入花费的时间就是这个 Batches Req AVG,Rows AVG 表示每秒导入的条数。
导入数据的时间及机器配置问题
Question:总共 2.3 亿点,50 亿边,从昨天到现在 15 个小时,单机,这个速度是正常的吗?
Answer:不太正常。贴下你的机器的配置,nebula 的配置文件,go-impoter 配置,还有是否使用索引了。这里帮你更改下默认的 storage.conf 配置,参考下面
########## storage ##########
# Root data path, multiple paths should be splitted by comma.
# One path per instance, if --engine_type is `rocksdb'
--data_path=/mnt/ssd1/storage,/mnt/ssd2/storage,/mnt/ssd3/storage
# The default block cache size used in BlockBasedTable.
# The unit is MB.
--rocksdb_block_cache=65536 # 这里改成大约总内存的1/3
# rocksdb ColumnFamilyOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
--rocksdb_column_family_options={"write_buffer_size":"67108864","max_write_buffer_number":"6","max_bytes_for_level_base":"268435456"}
更改了 nebula-storage.conf 三个地方,数据导入的 yaml 文件可以不作更改。
--data_path=/mnt/ssd1/storage,/mnt/ssd2/storage,/mnt/ssd3/storage #这里为 3 个硬盘
上面你要使用几个硬盘,可自行更改参数配置
storaged 配置文件更改生效问题
Question:storage 配置文件改完之后我是把全部重启还是只重启那个 store 服务
Answer:storaged 关闭,等一下(30s),然后重启,因为数据要刷到硬盘去。
导入 shell 关闭数据,导入会停止吗?
Question:正在导入数据的 shell 窗口关闭,数据导入是否停止?
Answer:是的,数据导入就终止了
如何查看导入进度
Question:怎么能知道导入到哪一步了,导入文件完成多少?
Answer:数据导入的时候有 Finished 字段,可查看到已经写入了多少了。
导入点边数据有先后顺序吗,还是随机的?
Question:导入点边数据有先后顺序吗,还是随机的?
Answer:点边导入顺序是按照文件顺序读,然后分给不同的 graph client 并行的插入,所以不一定按照文件的存储顺序插入。实现上是每个文件起一个线程读,然后同时分发给多个线程去插入 nebula,所以在多文件的情况下每个插入线程可能同时插入不同文件的数据。
导入工具支持断点续传吗?
Question:这个导入工具支持断点续传吗?比如说我中途导入停止了,后面又导入
Answer:不支持,作为本地 csv 导入,意义不大。当然其实自己想实现下并不难的。
最后,感谢小辉及其他小伙伴对这些 Tips 做出的贡献 ![]()