nebula 版本:v2 nightly
studio 版本:v2.1.5-beta
部署方式 :单机
硬件信息
磁盘: 2T SSD
CPU、内存信息:32Core 64G
请问下大佬,这样的情况,配置文件要怎样修改?几天没数据进入了
nebula 版本:v2 nightly
studio 版本:v2.1.5-beta
部署方式 :单机
硬件信息
磁盘: 2T SSD
CPU、内存信息:32Core 64G
你贴一下数据导入所用的配置文件吧。
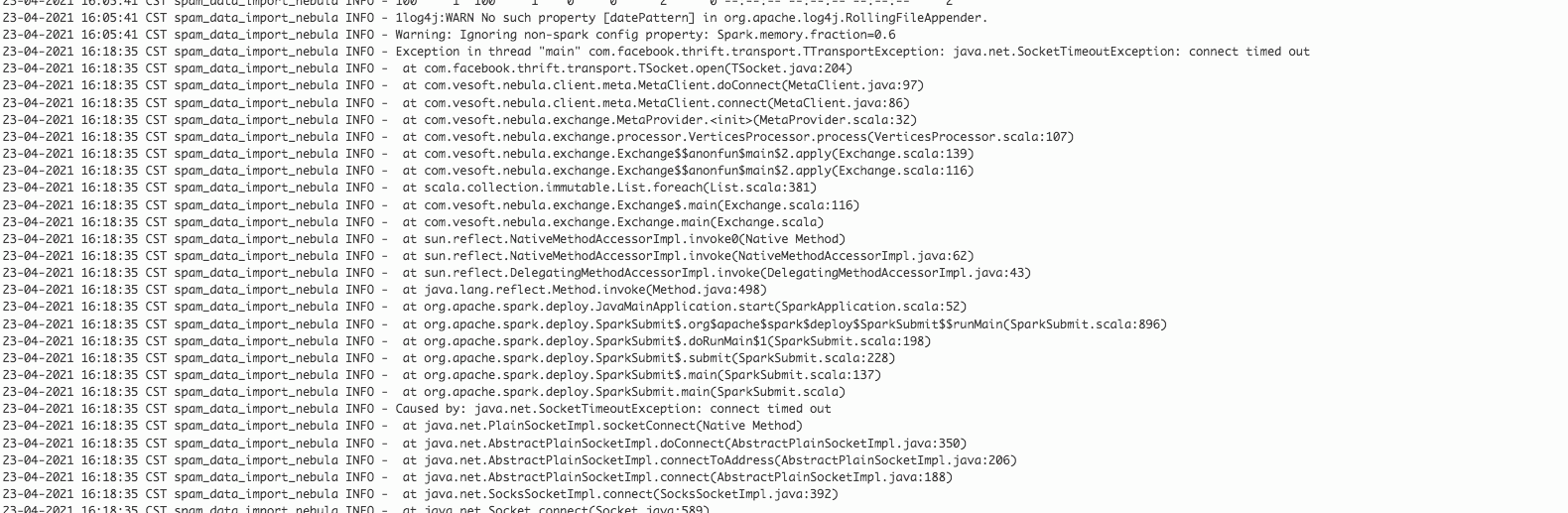
报错信息是metaClient连接超时
version: '3.4'
services:
metad0:
image: vesoft/nebula-metad:v2-nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
- --local_ip=metad0
- --ws_ip=metad0
- --port=9559
- --ws_http_port=19559
- --data_path=/data/meta
- --log_dir=/logs
- --v=0
- --minloglevel=0
healthcheck:
test: ["CMD", "curl", "-sf", "http://metad0:19559/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- 34006:9559
- 19559
- 19560
volumes:
- ./data/meta0:/data/meta
- ./logs/meta0:/logs
networks:
- nebula-net
restart: on-failure
cap_add:
- SYS_PTRACE
metad1:
image: vesoft/nebula-metad:v2-nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
- --local_ip=metad1
- --ws_ip=metad1
- --port=9559
- --ws_http_port=19559
- --data_path=/data/meta
- --log_dir=/logs
- --v=0
- --minloglevel=0
healthcheck:
test: ["CMD", "curl", "-sf", "http://metad1:19559/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- 34003:9559
- 19559
- 19560
volumes:
- ./data/meta1:/data/meta
- ./logs/meta1:/logs
networks:
- nebula-net
restart: on-failure
cap_add:
- SYS_PTRACE
metad2:
image: vesoft/nebula-metad:v2-nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
- --local_ip=metad2
- --ws_ip=metad2
- --port=9559
- --ws_http_port=19559
- --data_path=/data/meta
- --log_dir=/logs
- --v=0
- --minloglevel=0
healthcheck:
test: ["CMD", "curl", "-sf", "http://metad2:19559/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- 34001:9559
- 19559
- 19560
volumes:
- ./data/meta2:/data/meta
- ./logs/meta2:/logs
networks:
- nebula-net
restart: on-failure
cap_add:
- SYS_PTRACE
storaged0:
image: vesoft/nebula-storaged:v2-nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
- --local_ip=storaged0
- --ws_ip=storaged0
- --port=9779
- --ws_http_port=19779
- --data_path=/data/storage
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-sf", "http://storaged0:19779/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- 9779
- 19779
- 19780
volumes:
- ./data/storage0:/data/storage
- ./logs/storage0:/logs
networks:
- nebula-net
restart: on-failure
cap_add:
- SYS_PTRACE
storaged1:
image: vesoft/nebula-storaged:v2-nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
- --local_ip=storaged1
- --ws_ip=storaged1
- --port=9779
- --ws_http_port=19779
- --data_path=/data/storage
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-sf", "http://storaged1:19779/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- 9779
- 19779
- 19780
volumes:
- ./data/storage1:/data/storage
- ./logs/storage1:/logs
networks:
- nebula-net
restart: on-failure
cap_add:
- SYS_PTRACE
storaged2:
image: vesoft/nebula-storaged:v2-nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
- --local_ip=storaged2
- --ws_ip=storaged2
- --port=9779
- --ws_http_port=19779
- --data_path=/data/storage
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-sf", "http://storaged2:19779/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- 9779
- 19779
- 19780
volumes:
- ./data/storage2:/data/storage
- ./logs/storage2:/logs
networks:
- nebula-net
restart: on-failure
cap_add:
- SYS_PTRACE
graphd:
image: vesoft/nebula-graphd:v2-nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
- --port=9669
- --ws_ip=graphd
- --ws_http_port=19669
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-sf", "http://graphd:19669/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- "9669:9669"
- 19669
- 19670
volumes:
- ./logs/graph:/logs
networks:
- nebula-net
restart: on-failure
cap_add:
- SYS_PTRACE
graphd1:
image: vesoft/nebula-graphd:v2-nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
- --port=9669
- --ws_ip=graphd1
- --ws_http_port=19669
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-sf", "http://graphd1:19669/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- 9669
- 19669
- 19670
volumes:
- ./logs/graph1:/logs
networks:
- nebula-net
restart: on-failure
cap_add:
- SYS_PTRACE
graphd2:
image: vesoft/nebula-graphd:v2-nightly
environment:
USER: root
TZ: "${TZ}"
command:
- --meta_server_addrs=metad0:9559,metad1:9559,metad2:9559
- --port=9669
- --ws_ip=graphd2
- --ws_http_port=19669
- --log_dir=/logs
- --v=0
- --minloglevel=0
depends_on:
- metad0
- metad1
- metad2
healthcheck:
test: ["CMD", "curl", "-sf", "http://graphd2:19669/status"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
ports:
- 9669
- 19669
- 19670
volumes:
- ./logs/graph2:/logs
networks:
- nebula-net
restart: on-failure
cap_add:
- SYS_PTRACE
networks:
nebula-net:
docker-compose.yaml (6.9 KB)
请大佬帮忙看下哈
{
#park 相关配置
spark: {
app: {
name: Spark Writer
}
driver: {
cores: 16
maxResultSize: 32G
}
cores {
max: 128
}
}
# Nebula Graph 相关配置
nebula: {
address:{
# 以下为 Nebula Graph 的 Graph 服务和 Meta 服务所在机器的 IP 地址及端口
# 如果有多个地址,格式为 "ip1:port","ip2:port","ip3:port"
# 不同地址之间以英文逗号 (,) 隔开
graph:["172.16.113.127:9669"]
meta:["172.16.113.127:33837"]
}
# 填写的账号必须拥有 Nebula Graph 相应图空间的写数据权限
user: user
pswd: password
# 填写 Nebula Graph 中需要写入数据的图空间名称
space: TestGraph
connection {
timeout: 3000
retry: 3
}
execution {
retry: 3
}
error: {
max: 32
output: /tmp/errors
}
rate: {
limit: 1024
timeout: 1000
}
}
# 处理标签
tags: [
]
}
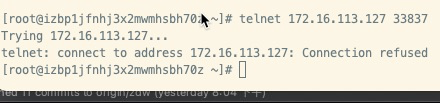
你在你运行spark writer 的机器上执行下 telnet 172.16.113.127 33837 截图
你需要修改docker-compose,将外面的端口固定。
ports:
- "9559:9559"
- 11000
- 11002
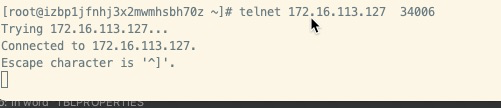 配置文件meta端口是:34006,是可以连上的。
配置文件meta端口是:34006,是可以连上的。
配置文件中的meta端口是:34006,发的application.conf中的是之前的端口。端口是没问题的。
之前配置已经固定住了 刚搞错了 发了之前的Application.conf
也是端口没问题的前提下,出现起初的报错
可是你spark的配置用的是33837的端口呀
实际的配置文件就是34006 其余一致
会不会是32Core 64G并发时不够用了啊 然后就是超时错误
你现在是所有线程都报这个错,还是就个别,你可以修改线程数试试
是个别。因为有些实时任务调用查询数据没有问题。就是批量导数据是有问题的。
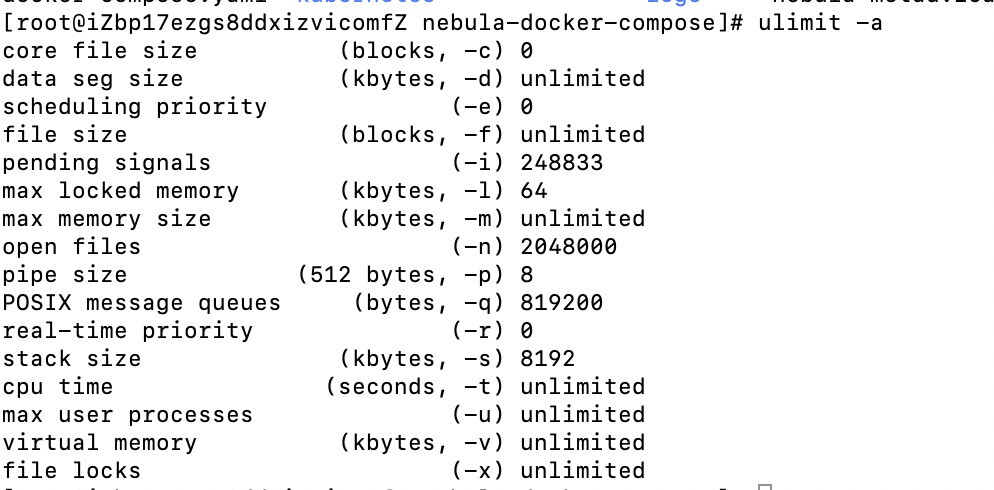
那你看下运行docker-compose 的机器设置的文件数是多少, ulimit -a 看是不是默认的。
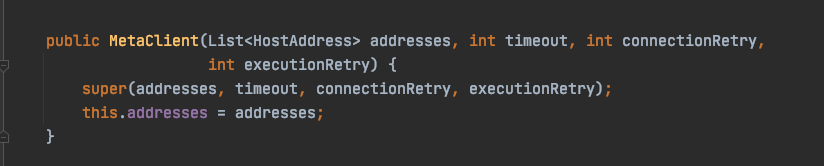
还有你现在 sparkwriter 的连接超时时间是1秒,可能当大并发的的时候,这个有点小。这个现在没有支持传入,假如还是,不行,你搜 new MetaClient,传下 connect time
请问下怎么搜new MetaClient??