nebula 版本:v2 nightly
studio 版本:v2.1.5-beta
部署方式 :单机
硬件信息
磁盘: 2T SSD
CPU、内存信息:32Core 64G
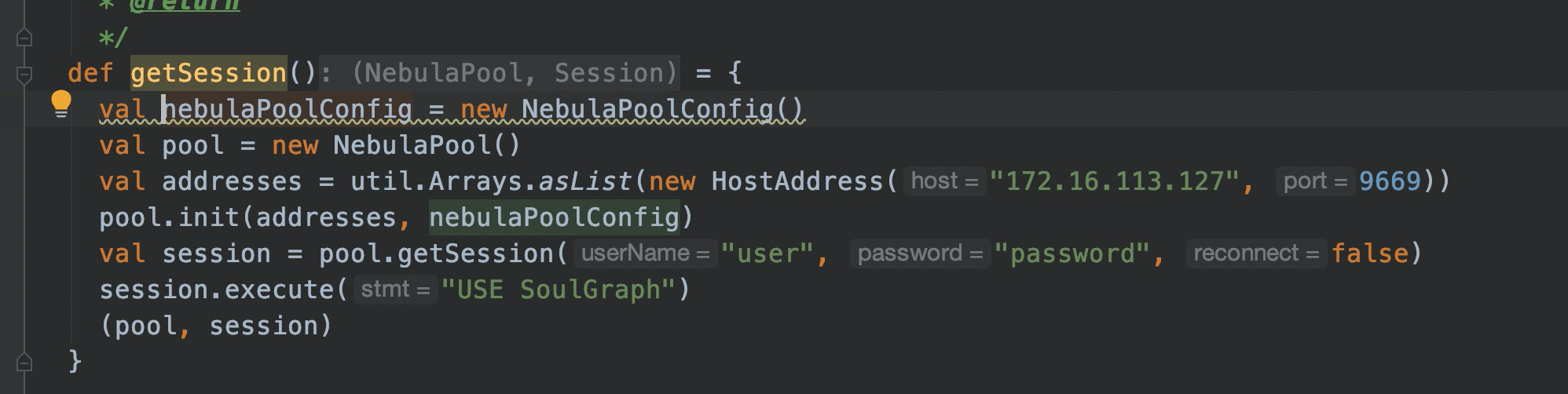
怎样才能每个线程用1个session,pool怎么设置的大一点。我们每次几千条一查询即便开了多线程也要延误好久,这样业务支持不了
nebula 版本:v2 nightly
studio 版本:v2.1.5-beta
部署方式 :单机
硬件信息
磁盘: 2T SSD
CPU、内存信息:32Core 64G
你的查询语句是怎样的,单独执行延时多少,并发的时候延时又是多少,麻烦贴下。
请问下nebulaPoolConfig.setMaxConnSize(1000)能不能提高并发
这个和并发没有直接关系,这个只是设置客户端连接池里面最大的连接数,用户怎么用这个连接才是关键。你们现在是起1000个线程,然后线程一开始拿一个session,然后后面每个线程的请求都是用这个拿到的session去执行请求吗?
是的。
那你回答我上面的问题
你的查询语句是怎样的,单独执行延时多少,并发的时候延时又是多少,麻烦贴下。
MATCH (n)-[:registerUserAndIP|:loginUserAndIp*0…2]-(v1:user) where id(n)==‘IP地址’ return v1.state,v1.user_id
用时:
假如你每个线程的query都是这样,并发肯定延时上去的,你相当于同时1000个人同时操作同一块数据,肯定是要排队的。
是不同的IP号去查询,能有什么改进的地方么,我们的业务要求在5秒内这条IP查询完
你们所有查询的起点都是 id 为 ‘IP地址’ 吗
是的 都是同一批IP去查
有批量查的nGQL
假如你的业务是一定要从同一个点出发做查询,那这样是避免不了排队等待的。说明你们的建模设计的有问题,不应该出现所有query都是访问同一个起点做查询。我觉得你还是改变你们的建模,然后业务查询也相应的做修改。
当然不是从一点出发查询,是不同IP去查它各自挂着的用户状态。
那你直接用 go,不要用match, GO 2 STEPS FROM start_id OVER edge1,edge2 YIELD $$.user.state, $$.user.user_id
但是指向是由用户指向IP 所以无法用
GO
什么意思,你上面发的query 就是可以用go等效的
go 出发的 应该是该节点由自己的出边出去的。而我们IP的是入边端的节点。
go 可以查出边也可以查入边,也可以查双向边,现在的 match 查询性能不行,你要想并发性能好些,还是先用 go 做
GO [[<M> TO] <N> STEPS ] FROM <vertex_list>
OVER <edge_type_list> [{REVERSELY | BIDIRECT}]
[ WHERE <conditions> ]
[YIELD [DISTINCT] <return_list>]
[| ORDER BY <expression> [{ASC | DESC}]]
[| LIMIT [<offset_value>,] <number_rows>]
刚刚试了 GO的就是空的 