nebula-importer 我感觉我好难,文档上没有说需要linux环境打包,也没说需要可以联网的linux环境。下载之后本地打包步成功,上传服务器,打包又报错估计要联网
[nebula@hadoop-node-2 nebula-importer]$ make build
rm -rf nebula-importer;
go: github.com/kr/text@v0.2.0: Get "https://goproxy.cn/github.com/kr/text/@v/v0.2.0.mod": dial tcp: lookup goproxy.cn on [::1]:53: read udp [::1]:54881->[::1]:53: read: connection refused
make: *** [fmt] Error 1
1 个赞
不需要linux环境,windows 和 macos 也是可以的,但是联网是必须的,这个我们可以在文档加上。谢谢你的反馈。
1 个赞
即使不需要linux环境但是也需要安装其他东西,不然make命令是不能识别的(如果你们还有别的打包命令另说),我最后折腾了半天,用wls打包,然后上传到服务器上。这个包就8.1M,强烈建议直接上传到github上。而且打这个包还需要go环境。而且联网的话,有的地方github网络真的很差,打包失败在github网络环境真的有点吃哑巴亏。
怎么说呢,建议考虑KISS原则。让用户更易用。
好的,谢谢你的反馈,我们提供下访问不了外网机器的情况下,如何使用 importer 或者直接提供免编译直接可用版本。
1 个赞
您好,
对于文档
我还有一个建议,文档看了几遍,首页我知道图数据的关系,不清楚的他的背景。在就是给的例子显得很混乱。不知道改怎么去入手,比如一第一个配置文件示例用得是./student.csv。里面用得是name,age,gender,后面用了grade ,以及 这些数据
101,Math,3,No5
102,English,6,No11
点示例
:LABEL,:VID,course.name,building.name:string,:IGNORE,course.credits:int
+,"hash(""Math"")",Math,No5,1,3
+,"uuid(""English"")",English,"No11 B\",2,6
边示例
:DST_VID,follow.likeness:double,:SRC_VID,:RANK
201,92.5,200,0
200,85.6,201,1
最后文档看完,也不明白这个测试数据是如何关联的,怎么把关系型数据转为图数据关系得。如果没有把给的demo理解清除,那么就很难把自己的业务数据按照同样的方式进行转换。
建议:
1.补充示例数据的关系说明,这个在neo4j权威指南里就是讲功能前会先声明自己用的数据的内容和关系
2.给一个完整的测试数据,以及对应的一个完整的可用的配置文件。
比如一第一个配置文件示例用得是./student.csv。里面用得是name,age,gender,后面用了grade ,以及 这些数据
你这里说的 name,age,gender 是 student 这个tag的属性,所以配置文件的配置是对应上的,然后那个 grade 它是 edge 的属性,它没有混淆在 vertex的配置里面。
schema:
type: vertex
vertex:
vid:
index: 1
function: hash
tags:
- name: student
props:
- name: age
type: int
index: 2
- name: name
type: string
index: 1
- name: gender
type: string
但是你说的csv 表头的例子确实没有和前面不带表头的时候保持一致,给你带来困惑了,非常抱歉,为了让刚接触的人更容易对应上,我们应该用同个tag和edge表示,方便理解。
1 个赞
yee
8
如果你的服务器不能连网,建议你在能联网的机器上把源码 clone 下来之后,再把依赖的 vendor 拉取到本地后,打包上传到对应的服务器上编译即可,操作步骤如下:
- git clone nebula-importer
- 使用如下的命令下载并打包依赖的源码:
$ cd nebula-importer
$ go mod vendor
$ cd .. && tar -zcvf nebula-importer.tar.gz nebula-importer
- 将上述的 tar 包上传到服务器
- 解压并编译:
$ tar -zxvf nebula-importer.tar.gz
$ cd nebula-importer
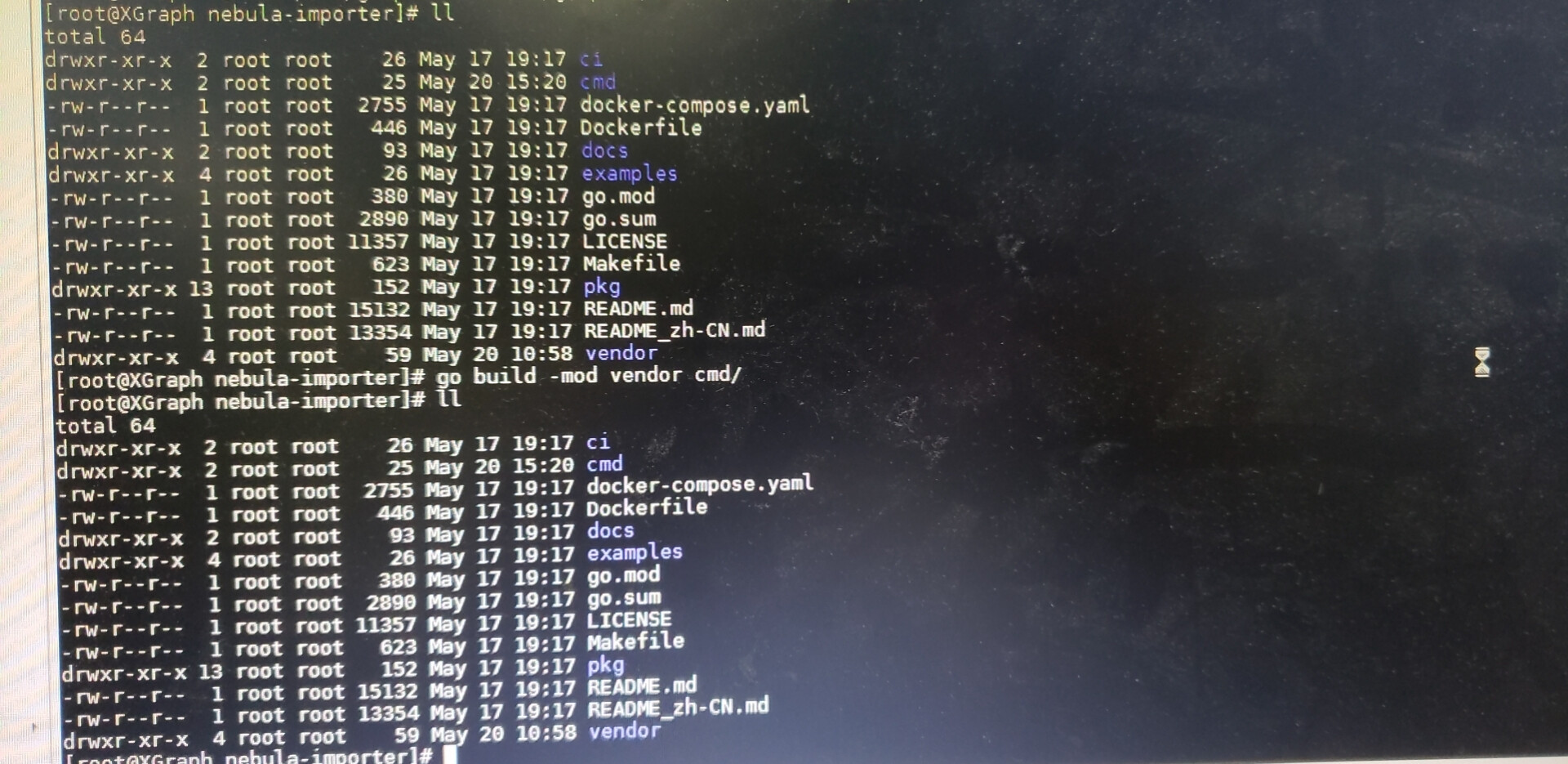
$ go build -mod vendor cmd/
这时就能编译出来服务器上的 importer 的 binary 了。
不联网的环境这样是有点麻烦了,后面会把每个平台的 binary 自动打包好,用户就不必再下载源码了。感谢你的反馈
2 个赞
您好,在这个不用docker都觉得自己会被嘲笑的时代。。但是我们真的没有用docker,为了测试真实性能,我们都是物理机测试,512g内存+2T存储+64核心cpu,虽然上面已经跑了很多应用。studio要和同事商量一下看怎么安装合适。。
之前测试neo4j是启动之后就能访问的。
nenula是不是也可以为自己做减法,让自己变得清爽,简单一点呢。
为了学习使用nebula,还得先去学习docker,路线有点长了。或者说入门门槛高了。。
要学习nebula-graph,因为技术选型,使用者也要学习go,docker。这样的学习成本我觉得应该方到最低,甚至无感。
比如mysql oracle ,我们用的时候极少去考虑他的底层,很容易就上手了,所以很流行
以上纯属个人拙见。。  。
。
1 个赞
我只在官网看了一下,没有点进去看,点进去就有了。这些对我很有用,因为大部分环境都没有网络,需要离线安装,而且docker在实际环境还不支持。
给你们的优秀点个赞。
2 个赞
请问这样安装的importer如何启动呢?文档上没有启动的说明
还有一个问题,创建nebula 创建space时要制定VId类型,当我当
执行
将打包好的文件重命名
ln -s nebula-importer nimporter
执行导入
./nimporter --config ./nimportercfg/20210428-nebula-importer-cfg.yml
yee
14
上面那个只是修改了一下编译的过程,执行跟之前的方式是一样的。go 语言的程序编译出来是没有多余的执行依赖的,只要用 importer 的 binary 直接执行就行。
已解决
原因:go build -mod vendor ./cmd/ 未指定cmd下的importer.go文件
2 个赞