记得按照下面模版提需求哟
(1)- 需求原因 / 使用场景
大数据量基于Cypher语句查询报错,数据量如下:
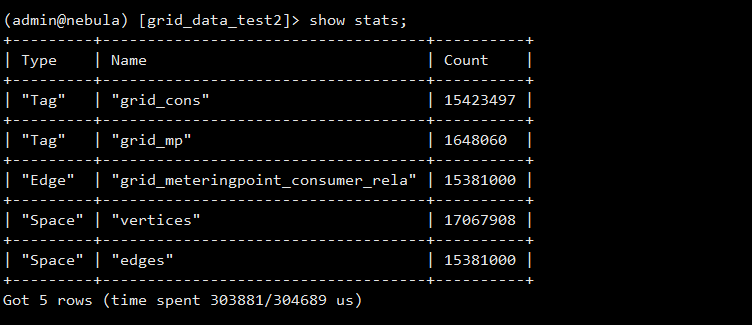
(1.1)报错如下:

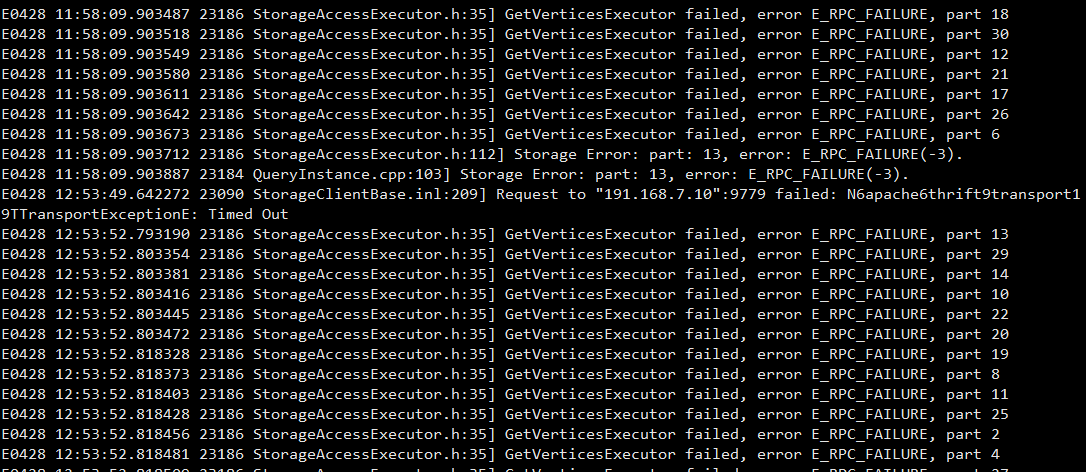
(1.2) graphd-stderr.log日志如下:
(2)- 需求描述
通过exchange方式导入3千多万数据,导入性能很不错,但是在建立完索引后,基于cypher查询老报错,多方查阅资料均未解决,特写出来,请官方解决,以便其他小伙伴遇到同样问题,可以得心应手处理
记得按照下面模版提需求哟
(1)- 需求原因 / 使用场景
大数据量基于Cypher语句查询报错,数据量如下:
你这个相当于把你整个space的所有点和边的信息全部捞出来,肯定超时了呀,你的机器内存多少,数据实际占用磁盘空间多少。
您好,机器配置如下:
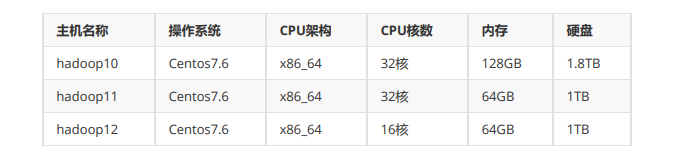
你是一定要把整个space的数据捞出来的吗?还有graphd所在机器是哪一台? 这么多数据占用磁盘空间是多少?
我们的需求: 之前用的Neo4j单节点 基于cypher语句写的 ,
现在要全面用咱的NebulaGraph 改造成基于OpenCypher 的写法,
现在的遇到问题是:
(1)由于Neo4j中一些业务Match查询写法基本都会涉及全局扫描,用Neo4j可以查出来,但是现在改造成这个基本执行一会就报错了
(2)针对您说的这个graphd所在机器,我是全集群部署的,部署如下:
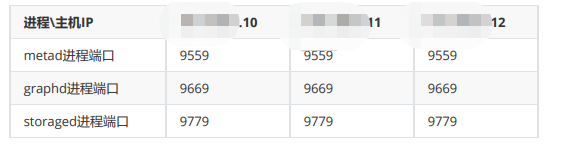
这些数据占用磁盘空间从下面可以看到,依次为hadoop10,hadoop11,hadoop12, 感觉占用也不大


因为你要全部捞出来,假如你的数据是占用存储是 100G,那么在查询过程中,要把所有数据全部加载到内存,内存需要的肯定就不止这么多,你可以把请求发给 10 的graphd,在graphd 的配置文件加上
--storage_client_timeout_ms=600000
看还会不会超时,假如还超时,就接着放大,也有可能会因为内存不够被 oom了。
好的,我试试,那再请问您一下,基于我们这种业务需求,NebulaGraph除了这种方式还有什么方式可以实现全空间扫描节点或者边呢