Nebula2.0.1 和Exchange 2.0.0
val nebulaReadVertexConfig: ReadNebulaConfig = ReadNebulaConfig
.builder()
.withSpace( param.space)
.withLabel(name)
.withNoColumn(false)
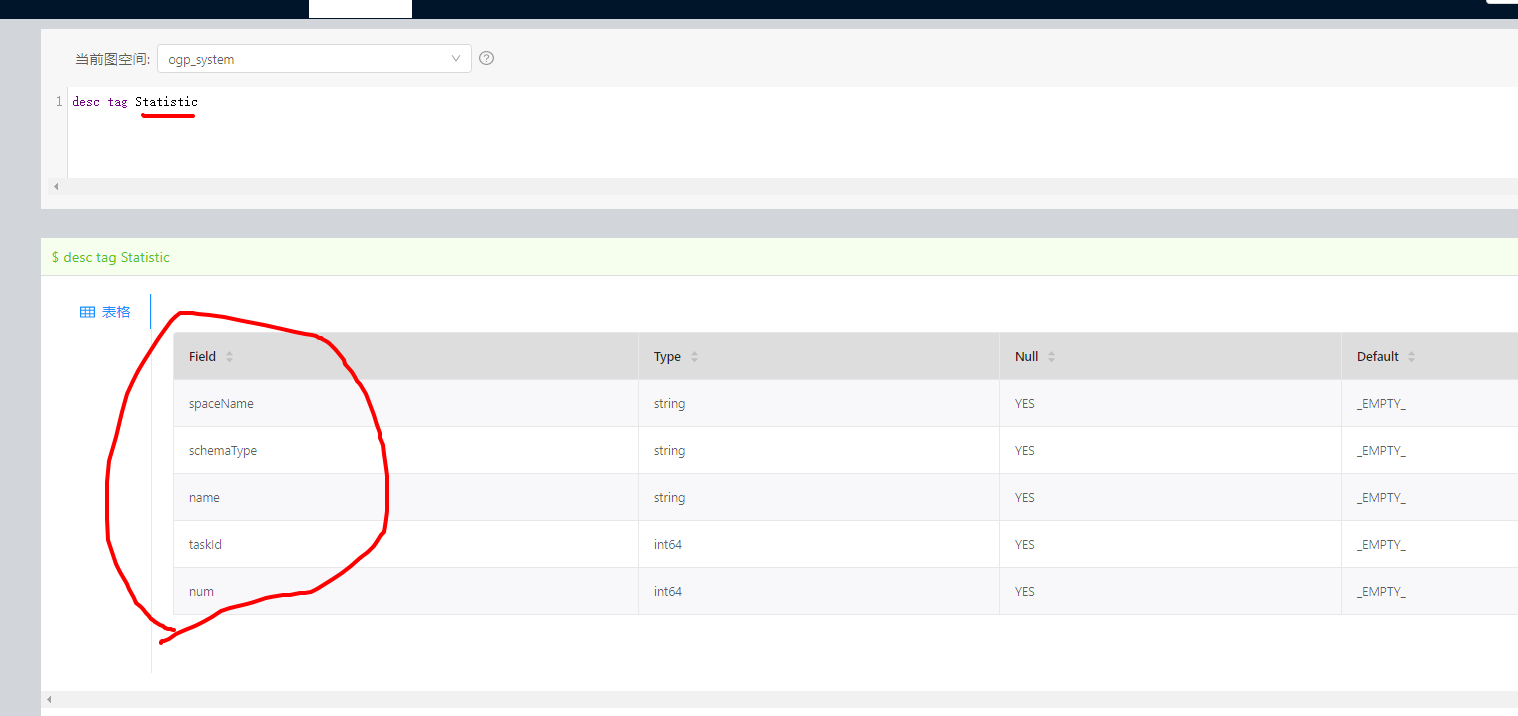
.withReturnCols(List("spaceName", "schemaType", "name", "taskId", "num"))
.withLimit(100)
.withPartitionNum(10)
.build()
val tagDataset= sparkSession.read.nebula(config, nebulaReadVertexConfig).loadVerticesToDF()
// val tagDataset: Dataset[Row] = reader.loadVerticesToDF(name, "*")
tag.setFields(tagDataset.columns.mkString(", "))
tag.setPath(param.path + "/Tag_" + name)
tag.setIdName("_vertexId")
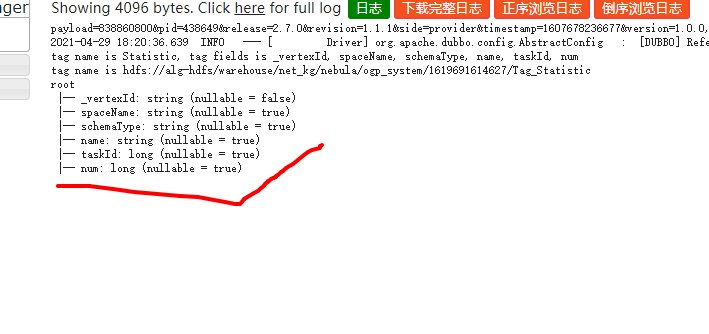
println("tag name is " + tag.getName + ", tag fields is " + tag.getFields)
println("tag name is "+tag.getPath)
//println("tag name is "+tagDataset)
//statistic.num = tagDataset.count()
tagDataset.printSchema()
tagDataset.show(1)
tagList.append(tag)
println("=====count==="+String.valueOf( tagDataset.count()));
println("======"+tag)
tagDataset.write.option("header", "true").option("seq", seq).format("csv").save(tag.getPath)
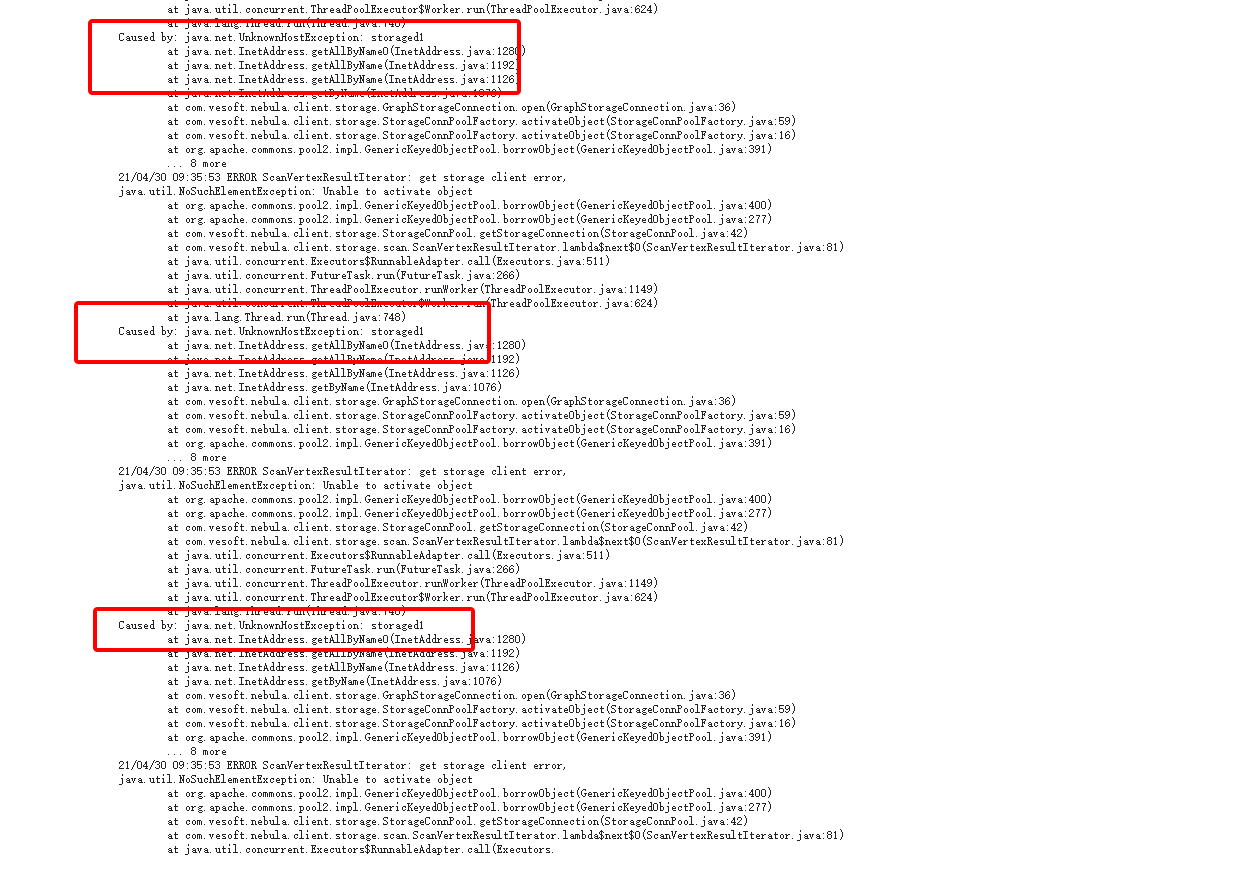
报错:21/04/29 15:46:14 WARN DFSClient: DFSOutputStream ResponseProcessor exception for block BP-1109931589-10.12.180.29-1536716072073:blk_6872991669_6049197242
java.io.EOFException: Premature EOF: no length prefix available
at org.apache.hadoop.hdfs.protocolPB.PBHelper.vintPrefixed(PBHelper.java:2305)
at org.apache.hadoop.hdfs.protocol.datatransfer.PipelineAck.readFields(PipelineAck.java:235)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer$ResponseProcessor.run(DFSOutputStream.java:1093)
tagDataset.printSchema() 有数据日志
tagDataset.show(1) 没数据日志卡主不动