相当一大堆。特别是compaction的时候,会额外占用一大堆。
好滴吧,谢谢大佬
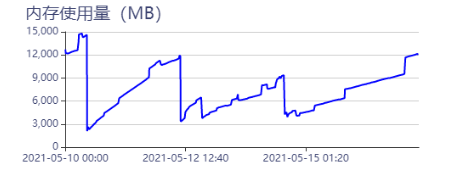
大佬,我把实例数改成1个了为啥内存还在不停上涨嘞?有阻止它上涨的方法吗?(5-15之后一直在上涨)
贴下storaged 的日志和rocksdb的日志,看看在干啥
1 个赞

disable_auto_compact=true
然后放置不动看看。
compact的内存使用不可控。
呜呜呜呜呜不管用啊
暂时看来不管用,内存还在不停上涨
看下你的vertex cache 的配置,有可能是vertex cache 太大了?
1 个赞
啊!我试试,谢谢大佬!这个是啥呀?怎么设置合理嘞?

好的谢谢
想了解下,这个改了后,有效果吗?
调成了64,放了四天,涨的慢了,但还是在不停上涨
我也遇到类似的问题,一个空环境放在那里,啥也没干,也没什么数据,nebula-storaged进程的总内存占用从5月13日的942MB涨到了今天的2777MB。
现在排查到增长是因为nebula-storaged进程会在固定的8MB缓冲区的起始地址之下分配一个动态增长的VMA,该VMA的终止地址固定在8MB缓冲区(间隔一个4KB的空洞)的起始地址,起始地址不断重映射成一个更小的地址,该VMA涨到最大长度1405MB后就不再增长,保留在那里不变了。然后在其起始地址之下,按照类似方法重新分配一个动态增长的VMA。
简单搜索了下nebula-storaged的源码,没有地方调用mmap系统调用,应该不是nebula-storaged的源码分配的,应该是第三方库分配的。现在怀疑是RocksDB分配的该VMA,正在研究RocksDB源码里的mmap系统调用。
3 个赞
贴一下nebula-storaged进程今天的pmap看到的内存vma列表,帮助理解上面的描述:
2599: ./bin/nebula-storaged --flagfile=./etc/nebula-storaged.conf --daemonize=false --meta_server_addrs=metad0:9559 --local_ip=storaged0 --ws_ip=storaged0 --port=9779 --ws_http_port=19779 --data_path=/data/storage --log_dir=/logs --v=0 --minloglevel=0
0000000000400000 12152K r---- nebula-storaged
0000000000fde000 21744K r-x-- nebula-storaged
000000000251a000 6592K r---- nebula-storaged
0000000002b8a000 420K r---- nebula-storaged
0000000002bf3000 52K rw— nebula-storaged
0000000002c00000 2960K rw— [ anon ]
00007fb2da600000 583680K rw— [ anon ] // 这个是正在涨的第二个该类VMA
00007fb2fe173000 1438720K rw— [ anon ] // 这个就是已经涨到最大长度1405MB的第一个该类VMA
00007fb355e73000 4K ----- [ anon ]
00007fb355e74000 8192K rw— [ anon ]
00007fb356674000 2560K rw— [ anon ]
3 个赞
大佬!靠您了!
基本确定两点:
(1)前贴中不断增长的VMA就是C++ new分配的对象所在的堆,堆的特点就是其结束地址固定不变,起始地址不停变小,堆也就不停变大。
(2)前贴中8MB的VMA应该就是rocksdb的block cache,storaged进程启动时有打印”block_size: 8192“。
在我的环境上,容器重启后,问题消失,其它nebula环境上也没有这个问题。
初步结论:nebula-storaged进程应该是有持续new的对象没有delete(该对象应该不会太小,至少几十KB级别,否则堆的生长到不了每天100MB以上),怀疑是和心跳、日志等周期性发生的事件有关,即使数据库空置也会持续发生,但很偶现。
后面待其再次出现时,可以在容器里使用gdb附着到nebula-storaged进程,直接在标准C++库的()函数或者jemalloc的je_mallocx()入口设置分配字节数大于一定数字的条件断点,应该就能断到泄漏的源码位置。
2 个赞
大佬,我这边现在内存又崩了,最后内存持续增长的时间段内,日志一直是这个信息,给你提供个参考,不知道对你有用没:
‘’’
I0530 15:03:28.141156 24606 EventListner.h:53] Rocksdb flush completed column family: default because of WriteBufferFull the newly created file: /data/graphdb/storage/1/nebula/390/data/001918.sst the smallest sequence number is 242561875 the largest sequence number is 242562898 the properties of the table: # data blocks=3; # entries=1024; # deletions=0; # merge operands=0; # range deletions=0; raw key size=16384; raw average key size=16.000000; raw value size=16384; raw average value size=16.000000; data block size=9946; index block size (user-key? 1, delta-value? 1)=73; # index partitions=1; top-level index size=21; filter block size=0; (estimated) table size=10019; filter policy name=rocksdb.BuiltinBloomFilter; prefix extractor name=rocksdb.FixedPrefix.16; column family ID=0; column family name=default; comparator name=leveldb.BytewiseComparator; merge operator name=nullptr; property collectors names=[]; SST file compression algo=Snappy; SST file compression options=window_bits=-14; level=32767; strategy=0; max_dict_bytes=0; zstd_max_train_bytes=0; enabled=0; ; creation time=1622358208; time stamp of earliest key=1622356182; file creation time=1622358208;
‘’’
有一个疑问:你的环境没有操作,怎么会有rocksdb因为WriteBufferFull而把该缓冲区刷出到硬盘文件的打印呢?
下次问题再出现时,需要你做两件事:
(1)确定metad、grpahd、storaged中的哪个进程的内存占用一直在涨。
(2)确定是进程的哪个VMA的大小一直在涨,还是不停有新的VMA在冒出来。
如果是和我前面帖子描述的类似的情况的话,建议你按照我说的方法,直接用gdb附着到内存一直增长的进程,然后在C++的new操作对应的operator new函数的入口设一个条件断点,看看都是什么地方在分配内存。条件断点的条件是要分配的内存块大小大于一定的字节数,可以先把字节数设大一点,断不到的话,再把字节数改小一点,如此不断减小,直到能够断到内存分配。
内存不断增长就是因为这些不断用new新分配的内存里面有一些没有用delete释放,也就是说泄漏了,泄漏的内存应该就在这些断到的内存分配里面。逐个排查其分配和释放的源码位置,应该就能发现泄漏点。