提问参考模版:
- nebula 版本:2.0.1
- 部署方式(分布式 / 单机 / Docker / DBaaS):分布式
- 是否为线上版本:Y
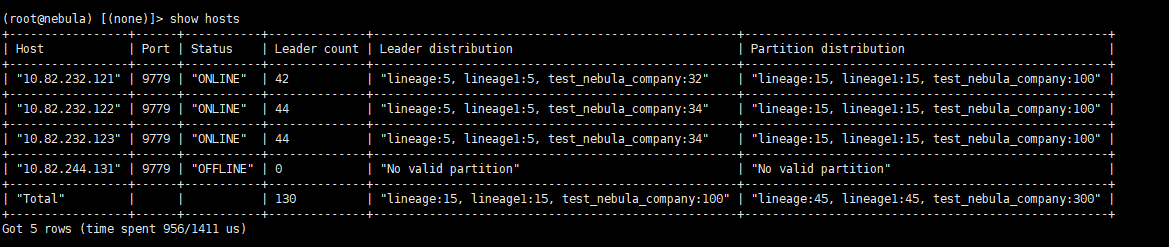
执行了 BALANCE DATA REMOVE 10.82.244.131:19779,然后节点上的storaged服务就自动停止,为啥show hosts依然存在此节点呢,如何测试删除这个10.82.244.131 记录

提问参考模版:
下线节点状态是 offline
在show hosts 里面的这条offline记录 有方法、命令 可以删除吗
删不掉
我记得等1天就好了
1、balance data 和 balance leader 有执行的先后顺序 要求吗?
2、可以设置自动balance data 和 balance leader 吗?如何设置
实际操作中,扩容了一个storaged节点,发现 执行balance leader 执行后show hosts没有任何变化,但是如果先执行balance data 后执行 balance leader,那么Leader distribution 才会从"No valid partition"变为有节点
你知道这两个命令是在做什么的吗。。。
负载均衡
BALANCE DATA 对数据分片进行均衡;
BALANCE LEADER 对分布leader进行均衡;
显然需要首先将数据分布均匀 然后调整leader 分布
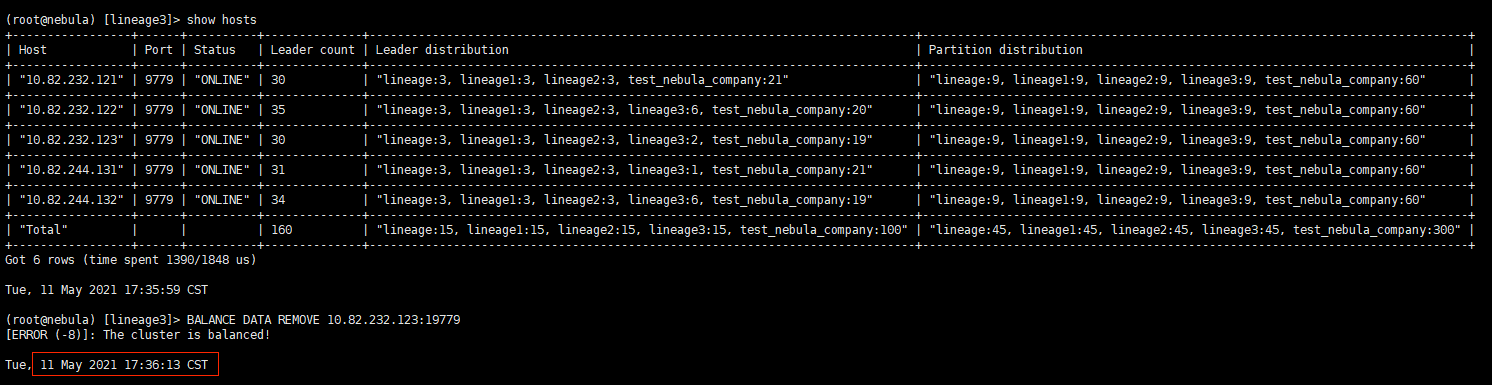
1、请教下如何优雅的踢掉一个storaged节点 10.82.232.123:9779,进行缩容
2,如果暴力的,直接kill掉 10.82.232.123机器上的storaged进程,然后执行balance data,问题是如果此时有程序正在写入,大概有30s的部分数据写入失败异常,
3,看到有命令 BALANCE DATA REMOVE 10.82.232.123:19779,但是这个命令在集群正常的时候,执行是不成功的,如果我直接kill了storaged进程,然后show hosts显示OFFLINE后,执行才能成功,那此时执行balance data 和执行 BALANCE DATA REMOVE 区别在哪?我观察到结果是一样的
发bug
发bug?啥意思?
执行不成功不应该的
是不是单副本?
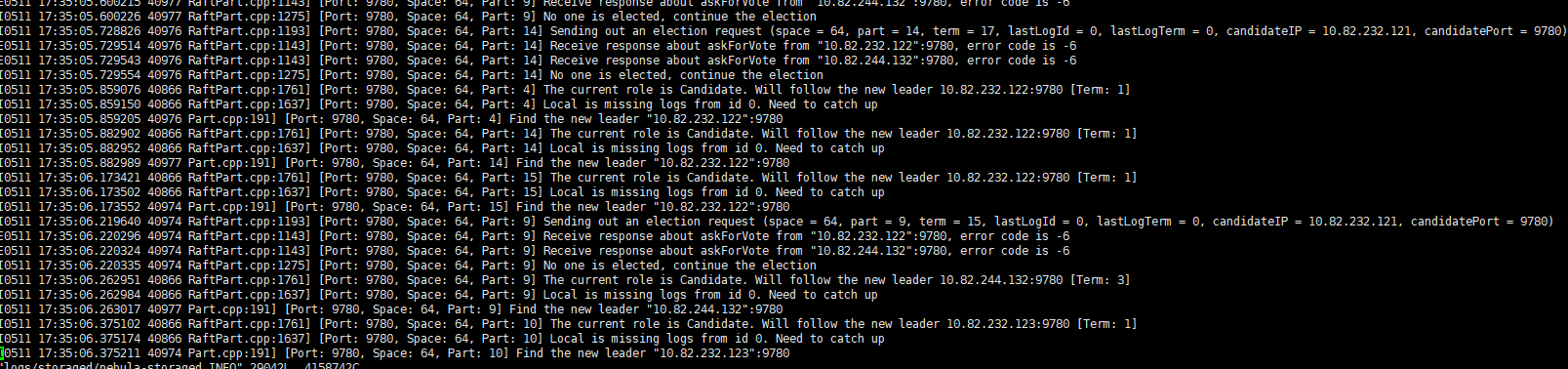
上面的主副本处于失效状态,需要重新进行一次选举得出主副本,所以会有一段时间失效。
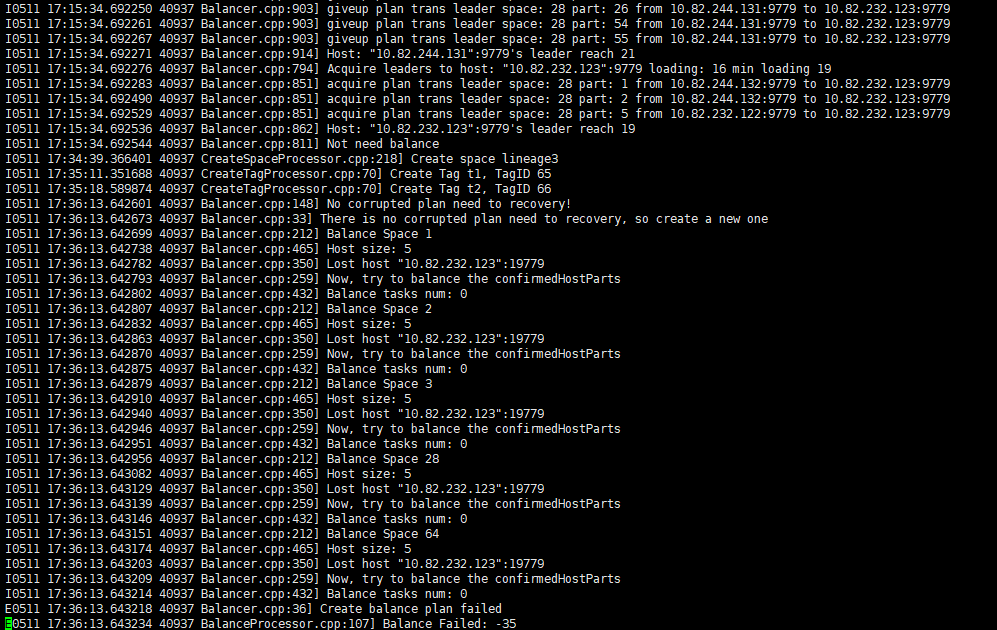
这个有日志么?
连接的10.82.232.121 graphd 执行,所有的space都是 三副本,重置环境再次执行测试
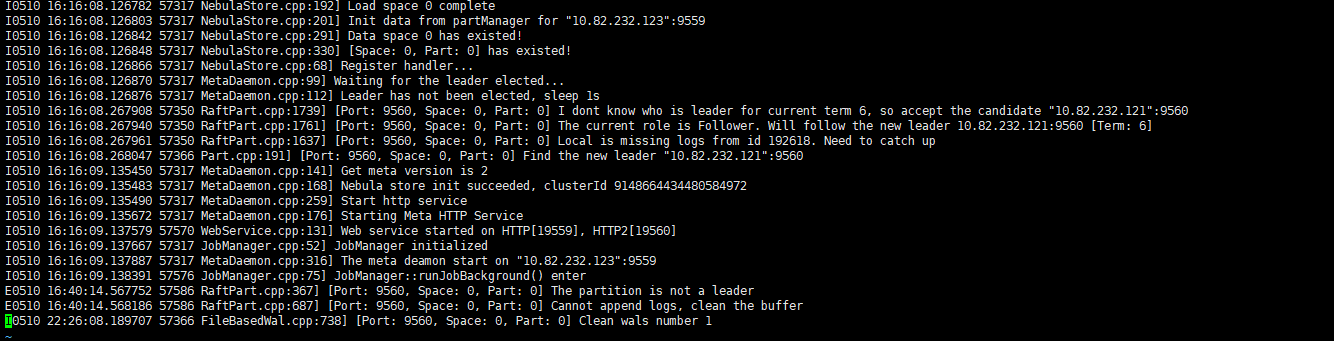
10.82.232.121 storage的 info日志
10.82.232.123 meta的 info日志
10.82.232.123 storage的 info日志
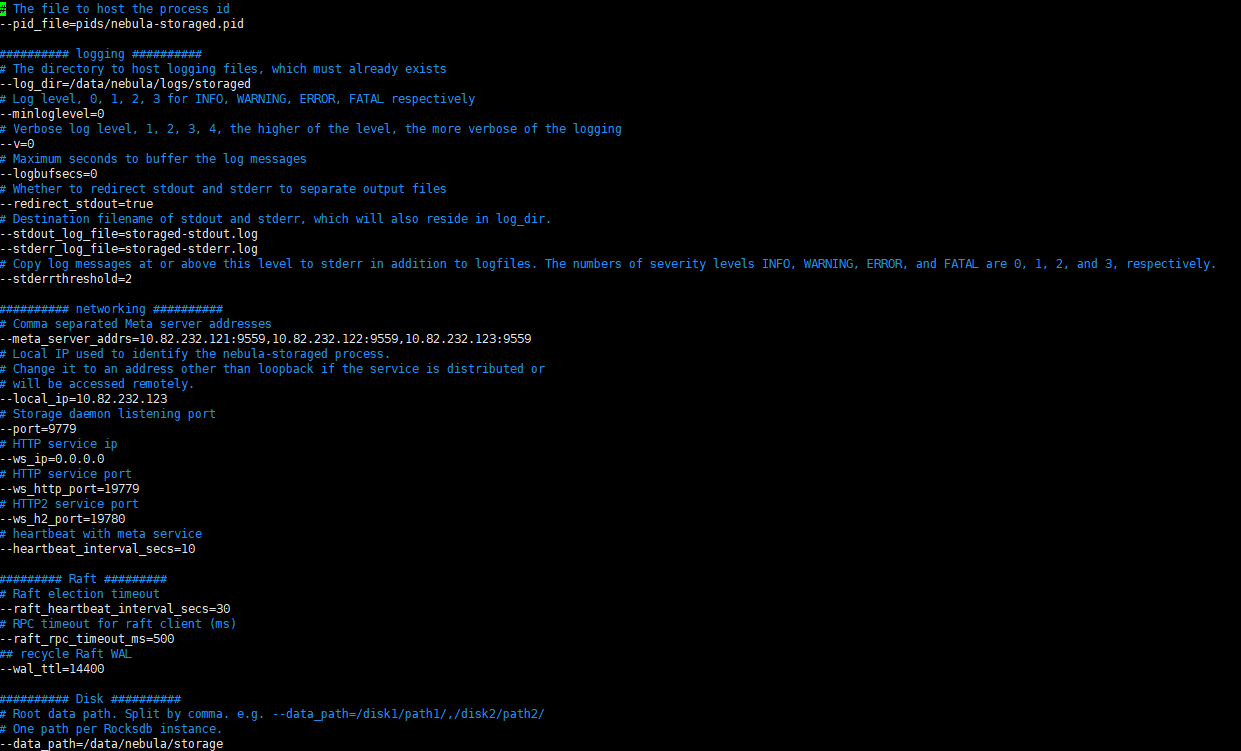
10.82.232.123 storaged配置
balance task 是 0 说明没启动 balance 任务 这个我来查一下为什么