你好, 各位大佬, 帮忙指导一下这怎么解决
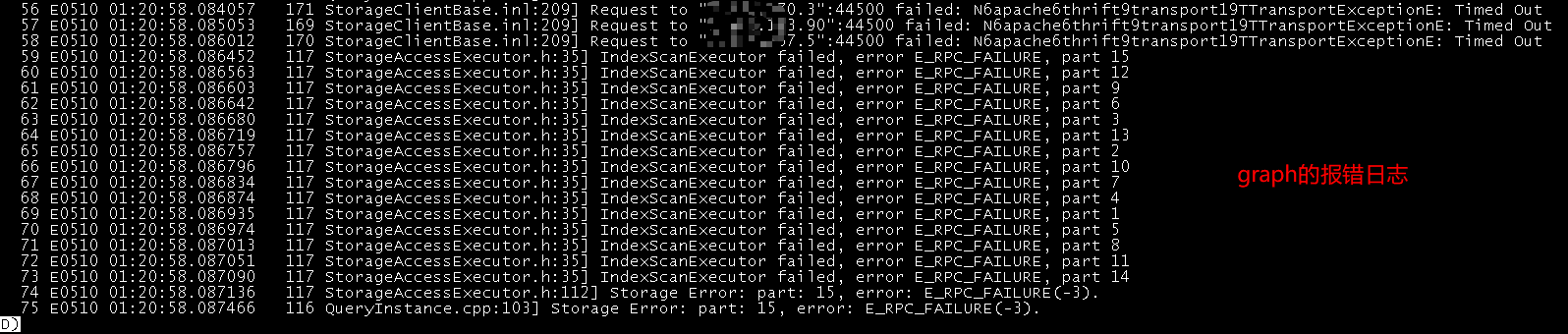
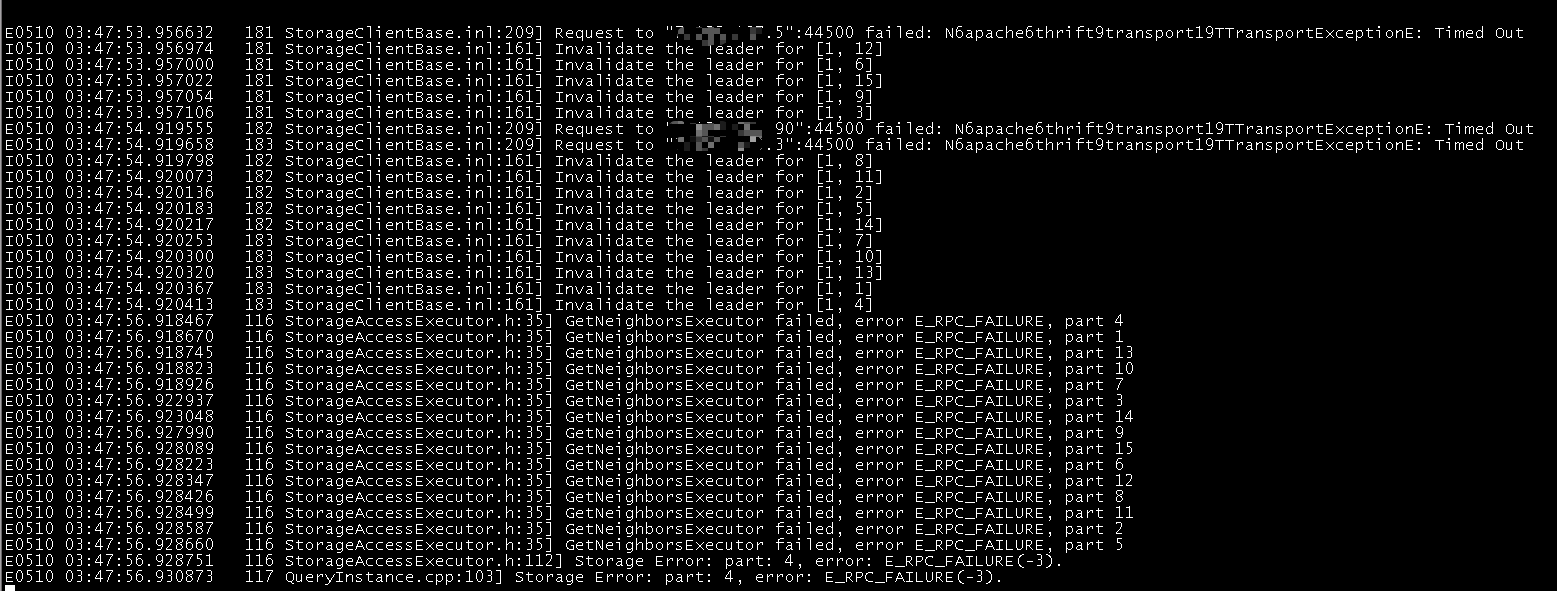
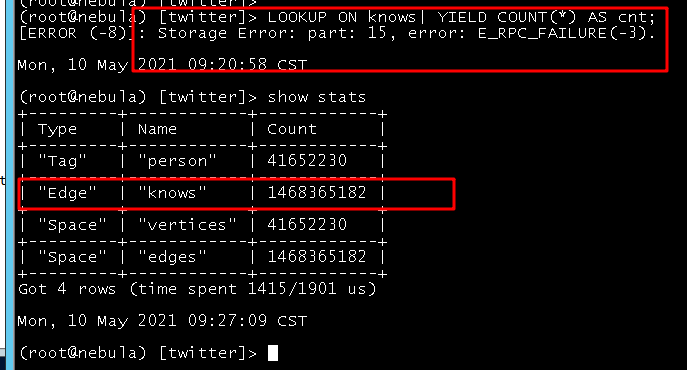
1 我使用这个语句来查中边数 (或者, 我查一些多跳, 节点数上7, 8 亿的也会报这个错, 其实我的内存只用了300G, 一共754G, 是什么原因呢??? 是不是有些默认配置需要修改??)
2 监控信息
3 对应graph节点的err日志
你好, 各位大佬, 帮忙指导一下这怎么解决
1 我使用这个语句来查中边数 (或者, 我查一些多跳, 节点数上7, 8 亿的也会报这个错, 其实我的内存只用了300G, 一共754G, 是什么原因呢??? 是不是有些默认配置需要修改??)
2 监控信息
3 对应graph节点的err日志
graphd向storaged请求的时间超时 storage_client_timeout_ms 是60秒,query查询的数据量太大的时候,storaged那边会超时,假如你内存够大,你可以在graphd的配置文件增加配置,将时间设置大些,单位是ms
--storage_client_timeout_ms=120000
你好, dingding
你说的这个配置, 我已经修改为300s了, 但是我有疑问就是这个配置的意思是一次query, graph等待storage计算返回结果的时间吗??? 那为啥我这个不是等5分钟(我这里配置的300S)挂的??? 大概是10分钟往上了
![]()
谢谢
你说的这个配置, 我已经修改为300s了, 但是我有疑问就是这个配置的意思是一次query, graph等待storage计算返回结果的时间吗?
你这个 query 可以这样理解。
那为啥我这个不是等5分钟(我这里配置的300S)挂的??? 大概是10分钟
你这里的意思是,你执行这条query后,从console执行到收到失败后,总共花费的时间接近10分钟吗?
假如是这个意思,可能是因为你的是三个storaged,然后你有部分part是成功的,然后这中间需要数据接收处理时间,还有graphd服务本身也需要处理时间,storage_client_timeout_ms 只是 graphd向每个storaged每条请求的超时时间。
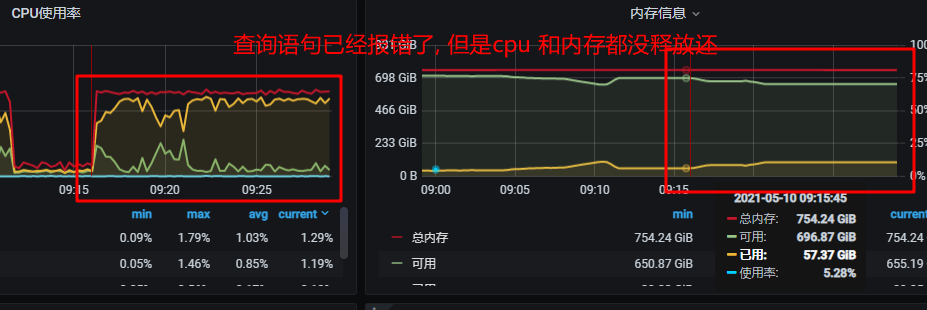
还有你上面提到的查询语句已经报错,但是cpu和内存没有释放,是因为graphd向storaged获取数据的时间超时了,但是storaged那边还在读数据,现在还没有超时后,storaged任务取消的机制。所以会有这现象。
对个, 请教你下, 一旦一个慢查询开始后, 我能不能手动的kill了??? 还是说只能等它执行完或者失败??
你这个是因为你是多度查询,6度的话,其实向每个storaged的请求最多是6条,所以这个时间可能就是超过你设置的 storage_client_timeout_ms
现在还没提供管理查询任务的功能,所以你只能等它做完。你们什么业务需要把所有边的数据全部拿出来呢?这样的操作应该不会是线上的。
其实这也不是真真的业务场景, 我们现在就是测nebula的性能极限, 和neo4j做个对比
还有你的是ssd还是hdd,导入数据之后有做过compacte吗
高性能SSD, IOPS压测能达到10W, 不是在导入数据的时候回自动做吗? 我这份数据导入完成, 到今天测已经过去了48小时了, 没有做任何操作
你可以手动做下compact ,然后再做下查询看下
ok, 默认的compact速度
做完 compact 之后,storage_client_timeout_ms 设置为 300000 后,还会查询超时吗?
你好, 稍等, 26G数据耗时30分钟 刚刚完成
你好, dingding, 做完之后, 还是报这个错, 其他的查询也没有任何性能上的查询提升
你那个6度之后出来的数据量应该很大,估计把整个space的大部分边都拿了一遍,你里面有十几亿边,读数据的时间肯定很久。假如你一定要测极限,要把所有数据拿出来,你就超时先调到int64的最大值,然后重启graphd,进行测试吧。你同样的数据,查询6跳,在neo4j的时间是多少?查出来的数据量又是多少呢?先有个预期。
哈哈, 不用没那么长, 5跳已经是8亿了, 6跳肯定… neo4j查不出来这个, nebula这个已经很厉害了 ![]() , 我就是想确认下我这个配置的有啥问题没,
, 我就是想确认下我这个配置的有啥问题没,
我是想验证这句话 ![]()