nebula 版本:v2.0.0
部署方式(分布式 / 单机 / Docker / DBaaS):Docker
是否为线上版本:N
硬件信息
问题的具体描述
比如这样的场景,tag定义为用户user,edge是单向的邀请信息invite,关系不会存在闭环,同时可以保证“一入多出”,即一个user能invite多个人,但只能被一个人invite,其实就是一棵树。请问用go语句或者match语句怎样能查询以一个特定user为开始节点,返回他所直接和间接invite的所有节点(或数量),举例:A invite B, B invite C and D, C invite E,输入A,输出BCDE
wey
2021 年5 月 10 日 08:39
2
MATCH 有变长模式 模式 - Nebula Graph Database 内核手册
MATCH path = (origin:player {name:"LaMarcus Aldridge"})-[*3..5]-(f:player) RETURN DISTINCT f.name
GO 也有指定 upto多少steps的方式https://docs.nebula-graph.com.cn/2.0.1/3.ngql-guide/7.general-query-statements/3.go/
GO 3 TO 5 STEPS FROM "player102" OVER follow YIELD DISTINCT $$.player.name;
您看看行不行?
感激老哥,有个问题是 变长模式必须指定最大长度,但实际场景下最大长度是未知的,想到两种方法可能可以解决:
暂定一个特别大的“最大长度”,比如100000,保证远远大于业务实际存在的最长链路,但此方法显然过于trick;
新增一个匹配条件,使终止节点(对应树的叶节点)没有invite边not (endPoint)-[:invite]->();
这两种我试一下是否可行,可以的话顺便对比下性能(现在的match语句和opencypher的在语法细节上好像还有不少差异,不清楚之后兼容的话性能的变化是怎样的)。
另外有没有函数式的写法,之前用GraphQL可以用递归的方式来写,不需要特意处理终点的问题
试了下这两种方法可行度都不高,
wey
2021 年5 月 10 日 09:36
6
确实这个性能代价太高了
opencypher的语法支持我们还在努力中,如果您觉得这个语法很重要,麻烦来github提issue哈!
您可以试试子图能满足您的需求么?它的性能是好很多的。
https://docs.nebula-graph.com.cn/2.0.1/3.ngql-guide/16.subgraph-and-path/1.get-subgraph/
GET SUBGRAPH 100 STEPS FROM "player100" OUT follow;
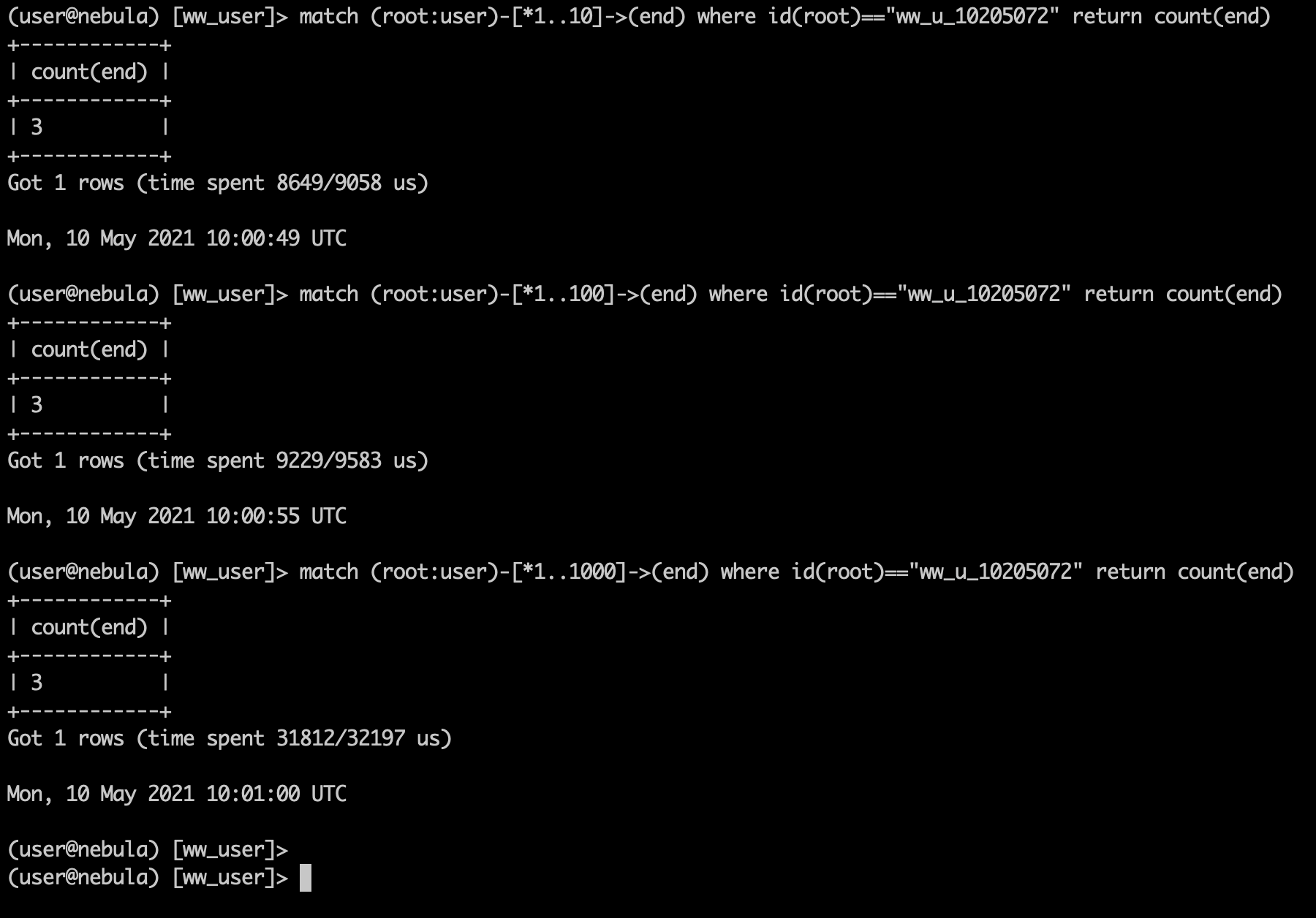
但看测试结果好像不是的,这个space里只有4个节点,除了根节点就只有3个,关系是单向的root->A->B->C,遍历10层和100层1000层耗时浮动比较明显,不知道是什么原因
记混了,是1.0的GO会终结。
感觉查询引擎里没有提前终止.虽然第一第二跳可能就知道查不到结果了.但是还是循环到match语句里的边跨度最大值100,1000.