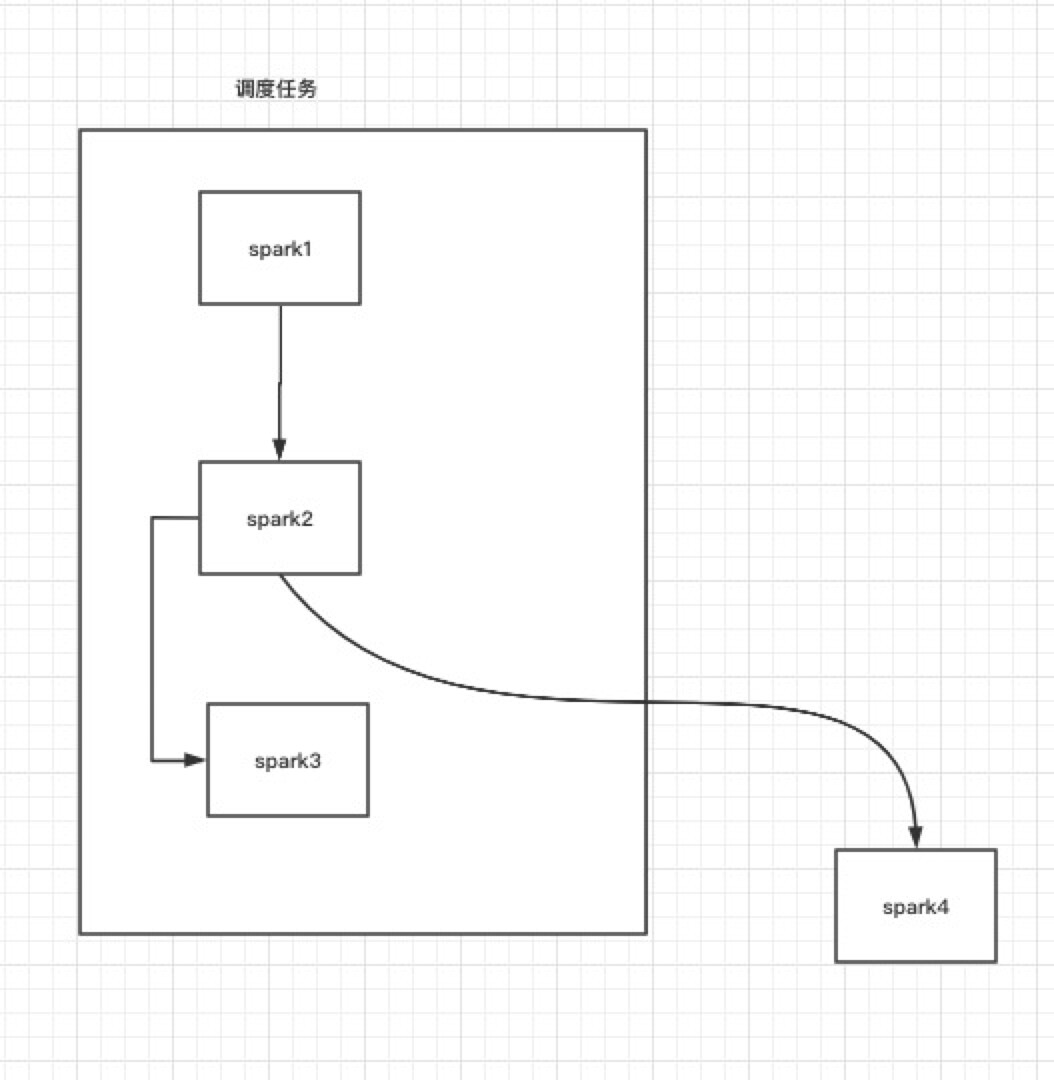
如图,有一个调度任务,此时spark4就是需要前置依赖于某一个调度任务的某个算子
产品是否可以支持这种需求:我可以单独定义某一个作业去前置依赖于任何调度任务中的某个任务, 而不是再建一个 spark1->spark2 ->spark4的调度任务
产品是否可以支持这种需求:我可以单独定义某一个作业去前置依赖于任何调度任务中的某个任务, 而不是再建一个 spark1->spark2 ->spark4的调度任务
你们目前使用Nebula 是怎么存储你的一个个调度任务、任务内的算子、算子之间依赖关系的?
如果你不想让task节点有冗余,那就需要将每个task节点的输出进行落盘,比如你上面的DAG中的spark4 有一个前置节点spark2,只需要根据spark2的标识信息如id等获取到spark2节点的输出即可。
如果你要求DAG的中间结果不落盘,那就需要重新建立起一个新的调度任务,且新的调度任务也需要包括spark1和spark2节点。
按照你的描述,你的调度任务应该是一个个独立的DAG,就算是依赖其他DAG中的task节点,也只是task复用数据不复用吧,你可以介绍下这个需求的具体场景么?