nebula 版本:nebula gragh 2.0 ga
部署方式:分布式
是否为线上版本:N
硬件信息
磁盘:HHD
GH-204:500G
GH-205:500G
GH-206:500G
CPU、内存信息
问题的具体描述:
使用 nebula-spark-connector 2.0 从hive导入数据到nubula 频繁报连接超时
LOG.info("start to write nebula edges")
//val df = spark.read.json("example/src/main/resources/edge")
var df= spark.sql("select *,1 as rank from neb.t_dwd_relation").repartition(1000)
LOG.info("---------------分区个数----------"+String.valueOf(df.rdd.partitions.size))
df.persist(StorageLevel.MEMORY_AND_DISK_SER)
df.show()
//df.persist(StorageLevel.MEMORY_AND_DISK_SER)
val config =
NebulaConnectionConfig
.builder()
.withMetaAddress("GH204:9559,GH205:9559,GH206:9559")
.withGraphAddress("GH204:9669,GH205:9669,GH206:9669")
.withTimeout(300000)
.withConenctionRetry(3)
.withExecuteRetry(3)
.build()
val nebulaWriteEdgeConfig: WriteNebulaEdgeConfig = WriteNebulaEdgeConfig
.builder()
.withSpace("neb2")
.withEdge("relation2")
.withSrcIdField("s_vid")
.withDstIdField("e_vid")
.withRankField("rank")
.withSrcAsProperty(true)
.withDstAsProperty(true)
.withRankAsProperty(true)
.withBatch(1500)
.build()
df.write.nebula(config, nebulaWriteEdgeConfig).writeEdges()
spark 日志如下:
21/05/18 11:00:11 INFO scheduler.TaskSetManager: Starting task 903.1 in stage 3.0 (TID 2022, act64, executor 22, partition 903, PROCESS_LOCAL, 7778 bytes)
21/05/18 11:00:16 INFO scheduler.TaskSetManager: Finished task 891.1 in stage 3.0 (TID 2020) in 132231 ms on act62 (executor 1) (991/1000)
21/05/18 11:00:19 INFO scheduler.TaskSetManager: Lost task 895.0 in stage 3.0 (TID 1896) on act63, executor 21: com.vesoft.nebula.client.graph.exception.IOErrorException (java.net.ConnectException: 连接超时 (Connection timed out)) [duplicate 1]
21/05/18 11:00:19 INFO scheduler.TaskSetManager: Starting task 895.1 in stage 3.0 (TID 2023, act66, executor 30, partition 895, PROCESS_LOCAL, 7778 bytes)
21/05/18 11:00:56 WARN scheduler.TaskSetManager: Lost task 991.0 in stage 3.0 (TID 1996, act64, executor 16): com.vesoft.nebula.client.graph.exception.AuthFailedException: Auth failed: Authenticate failed: java.net.SocketException: 断开的管道 (Write failed)
at com.vesoft.nebula.client.graph.net.SyncConnection.authenticate(SyncConnection.java:59)
at com.vesoft.nebula.client.graph.net.NebulaPool.getSession(NebulaPool.java:108)
at com.vesoft.nebula.connector.nebula.GraphProvider.switchSpace(GraphProvider.scala:47)
at com.vesoft.nebula.connector.writer.NebulaWriter.prepareSpace(NebulaWriter.scala:28)
at com.vesoft.nebula.connector.writer.NebulaEdgeWriter.<init>(NebulaEdgeWriter.scala:49)
at com.vesoft.nebula.connector.writer.NebulaEdgeWriterFactory.createDataWriter(NebulaSourceWriter.scala:44)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.run(WriteToDataSourceV2Exec.scala:113)
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec$$anonfun$doExecute$2.apply(WriteToDataSourceV2Exec.scala:67)
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec$$anonfun$doExecute$2.apply(WriteToDataSourceV2Exec.scala:66)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
21/05/18 11:00:56 INFO scheduler.TaskSetManager: Starting task 991.1 in stage 3.0 (TID 2024, act62, executor 25, partition 991, PROCESS_LOCAL, 7778 bytes)
21/05/18 11:00:57 INFO scheduler.TaskSetManager: Lost task 913.0 in stage 3.0 (TID 1917) on act62, executor 7: com.vesoft.nebula.client.graph.exception.AuthFailedException (Auth failed: Authenticate failed: java.net.SocketException: 断开的管道 (Write failed)) [duplicate 1]
21/05/18 11:00:57 INFO scheduler.TaskSetManager: Starting task 913.1 in stage 3.0 (TID 2025, act63, executor 3, partition 913, PROCESS_LOCAL, 7778 bytes)
尝试过 调整过 withBatch() 500 ~1500
.withTimeout() 10000 ~ 300000
连接超时的task还是比较多
task 运行截图如下:
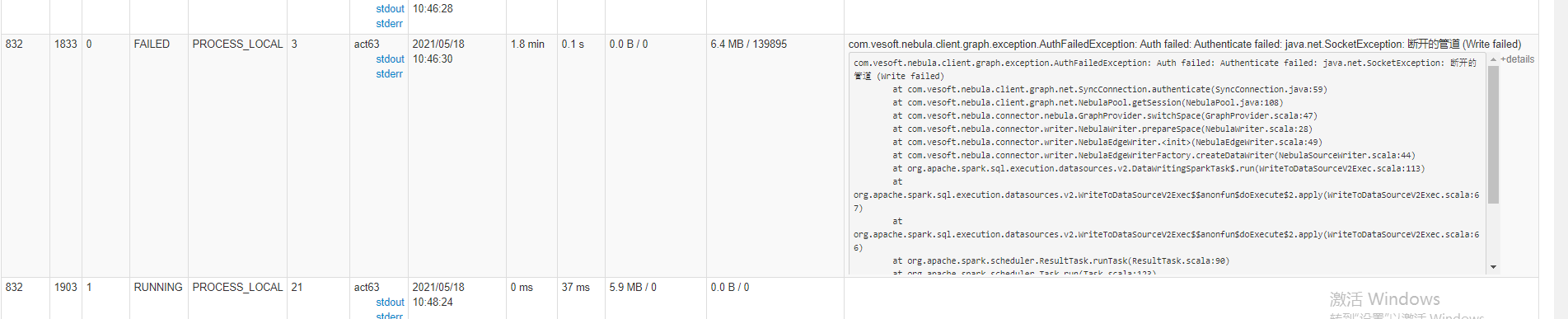
 这个鉴权本身就是关闭的
这个鉴权本身就是关闭的