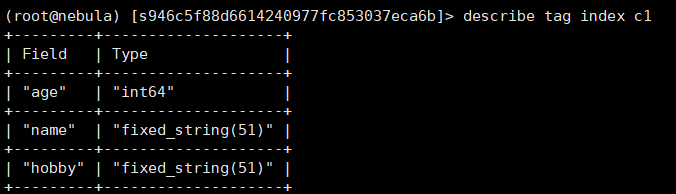
复合索引为(id、name、age、sex、hobby),也能使用id、age、sex查询,
在2000W的tag上创建单索引,drop后compact,物理空间多占用1-2G,
复合索引为(id、name、age、sex、hobby),也能使用id、age、sex查询,
您举得例子很有代表性, 用字段 1,2,3,4,5建索引 , 然后按字段1, 3, 4 查询, 索引是不生效的(只会对字段 1 生效).
理论上, 如果您想随意组合查询条件, 那么对于 n 个字段的 tag , 您需要建 2 的 n次方个索引,
在2000W的tag上创建单索引,drop后compact,物理空间多占用1-2G,
理论上索引在 drop & compact 之后不会有多余的空间. 您这个情况, 我个人怀疑可能是 nebula 的其它模块在导数据时留下的 WAL. 您这个数据是多久之前导的呢?
数据前几天导的,执行了第一次compact后是51G,重新创建索引,drop后再次compact是53G,3台服务器基本都是这个占用
几天的话应该不是 nebula 的 wal了, 不知道是不是 rocksdb 再搞事情. 您可以再关注下, 要持续, 大比例增长可能是哪里有 bug.
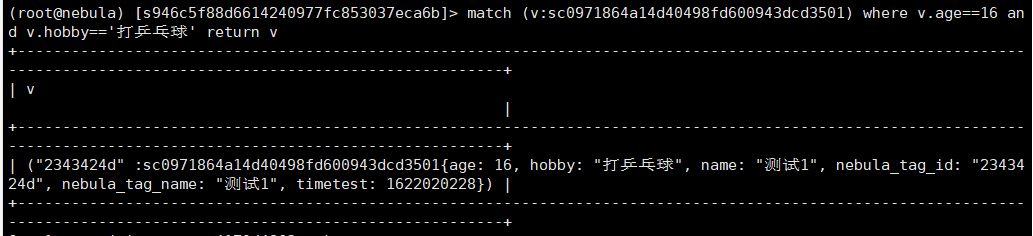
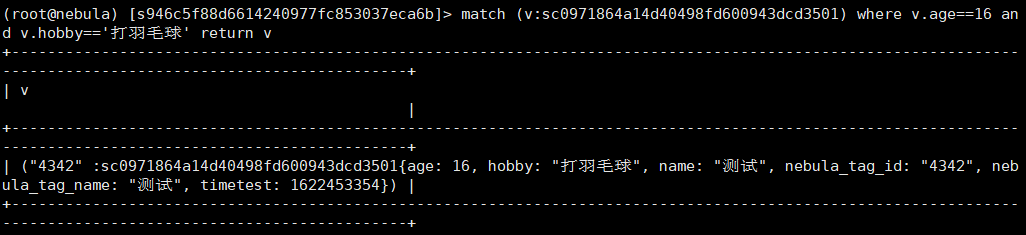
测试了下对表age,sex,hobby建索引,可以对age,hobby查询
最新版本是支持这种?
测试了3个tag3000W数据,删除后compact后物理内存没有增加,之前的可能是对索引操作导致的
哦, 我之前说的那些都是针对 lookup, match 挑索引现在有个已知 bug, 有可能用不上后面的多级索引. 正在修.
pandap
2021 年5 月 31 日 10:04
10
后面索引会优化吗?
如果a点是已知的,建议用fetch语句查询;如果a不是已知的,需要条件 b,c,d来过滤出a点的话,目前只能创建一个包含字段b,c,d的index。