目录
- 一、测试结论
- 1.1 测试结论
- 二、测试环境
- 2.1 机器
- 2.2 部署方式
- 2.3 Space 信息
- 2.4 配置文件
- 三、测试数据
- 四、测试用例
- 4.1 CASE1
- 4.2 CASE2
- 4.3 CASE3
- 4.4 CASE4
- 五、测试结果及说明
- 5.1 测试指标
- 5.2 测试结果
- 5.2.1 CASE1
- 5.2.2 CASE2
- 5.2.3 CASE3
- 5.2.4 CASE4
- 5.3 测试结果说明
一、测试结论
1.1 测试结论
测试结论如下:
- 一跳场景下,Nebula v2.0.1 吞吐下降约 10%-20%(原因分析详见 5.3)
- 多跳场景下,Nebula v2.0.1 表现优于 Nebula v1.2.0
- 简单目的点查询场景下,两个版本基本持平
- 其他查询场景下,Nebula v2.0.1 吞吐量提升在 35%-100% 之间,延迟下降在 10%-50% 之间
下面为具体的测试过程。
二、测试环境
2.1 机器
4 台物理机:48 Core,256G Mem,1.5T SSD,万兆网
2.2 部署方式
| 服务 | 数量 | 说明 |
|---|---|---|
| graphd | 1 | 单机部署 |
| metad | 3 | 使用 3 台机器混布 |
| storaged | 3 | 使用 3 台机器混布 |
表2-1 服务部署方式说明
2.3 Space 信息
| Space 名称 | 分片数量 | 备份数量 | VID 类型 |
|---|---|---|---|
| ldbc_snb_sf100_vid_int | 24 | 1 | INT64 |
表 2-2 Nebula v2.0.1 Space 信息说明
| Space 名称 | 分片数量 | 备份数量 | VID 类型 |
|---|---|---|---|
| ldbc_snb_sf100 | 24 | 1 | INT64 |
表 2-3 Nebula v1.2.0 Space 信息说明
2.4 配置文件
Storage:
- –rocksdb_block_cache=81920
- –max_handlers_per_req=1
- –heartbeat_interval_secs=10
其他配置参见 Nebula 生产环境配置。配置文件在 conf 目录下的三个配置文件:
- nebula-graphd.conf.production
- nebula-storaged.conf.production
- nebula-metad.conf.production
三、测试数据
本次测试及性能对比均采用 LDBC 100G 数据集。
四、测试用例
本次测试共选择了四个测试用例。
4.1 CASE1
该用例用于测试 N 跳拓展取目的点 ID。语句用法如下:
GO {N} STEP FROM {vid} OVER knows
4.2 CASE2
该用例用于测试 N 跳拓展取边属性。语句用法如下:
GO {N} STEP FROM {vid} OVER knows yield knows.`time`
4.3 CASE3
该用例用于测试 N 跳拓展取目的点属性。语句用法如下:
GO {N} STEP FROM {vid} OVER knows yield $$.person.first_name
4.4 CASE4
该用例用于测试 N 跳拓展后取边属性以及目的点属性,并进行 TOPN 计算。语句用法如下:
GO {N} STEP FROM {vid} OVER knows YIELD DISTINCT knows.`time` as t, $$.person.first_name, $$.person.last_name, $$.person.birthday as birth | order by $-.t,$-.birth | limit 10
五、测试结果及说明
5.1 测试指标
本次测试主要考察系统吞吐量(Throughput),查询延迟(Latency)。其中 Latency 部分将分别考察服务端及客户端的结果,并细分为 P99,P95,P90 三个指标。
5.2 测试结果
5.2.1 CASE1
语句 GO {N} STEP FROM {vid} OVER knows 测试结果
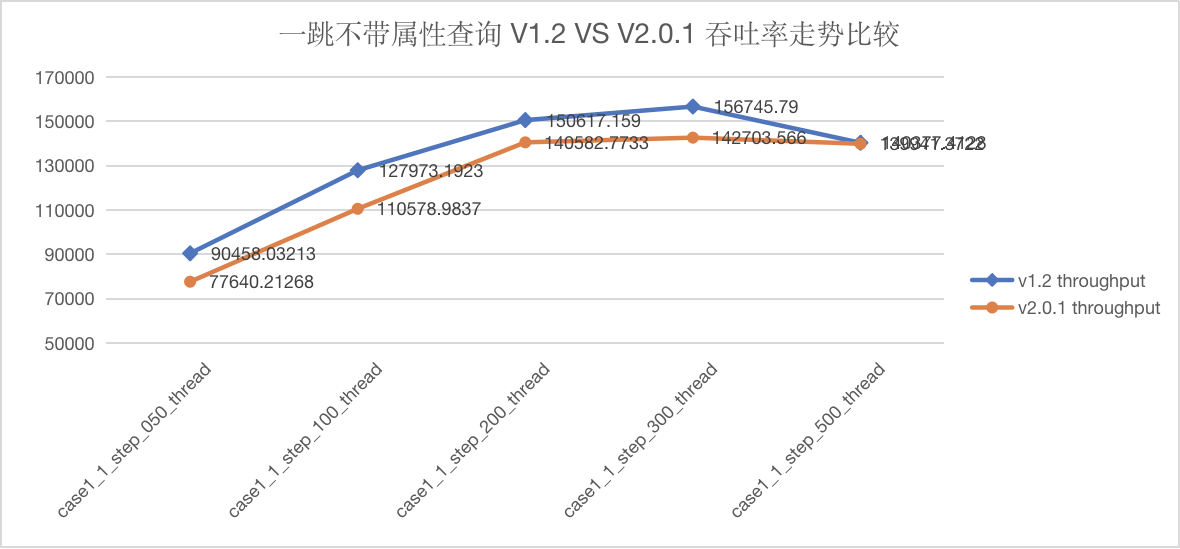
图5-1 CASE1 一跳查询吞吐量

图5-2 CASE1 一跳查询服务端延迟
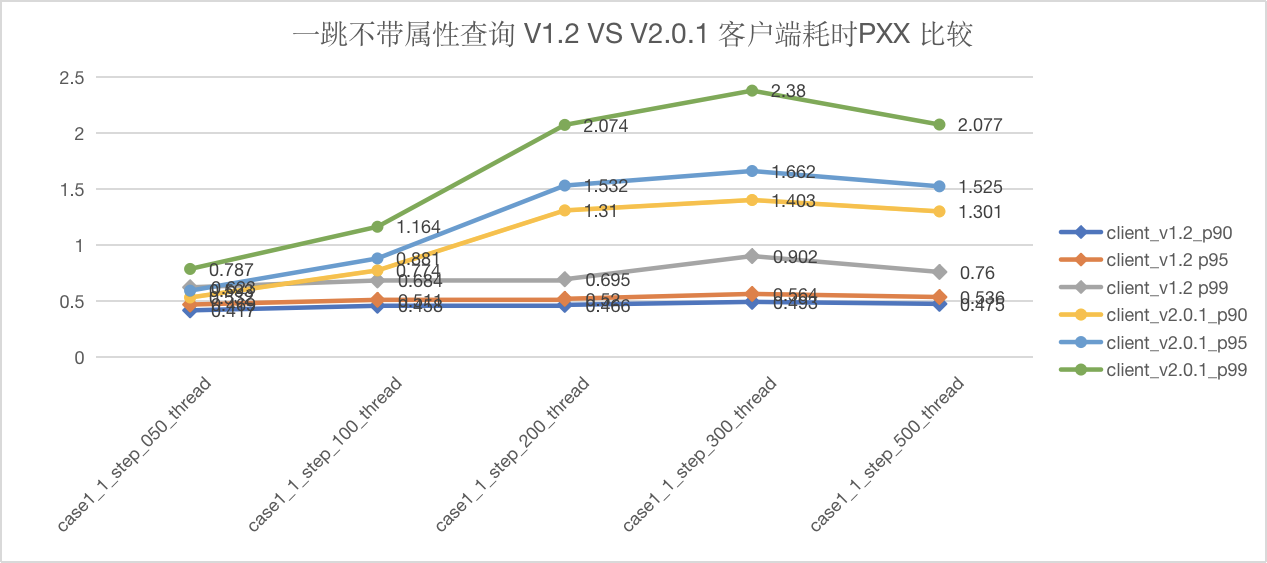
图5-3 CASE1 一跳查询客户端延迟
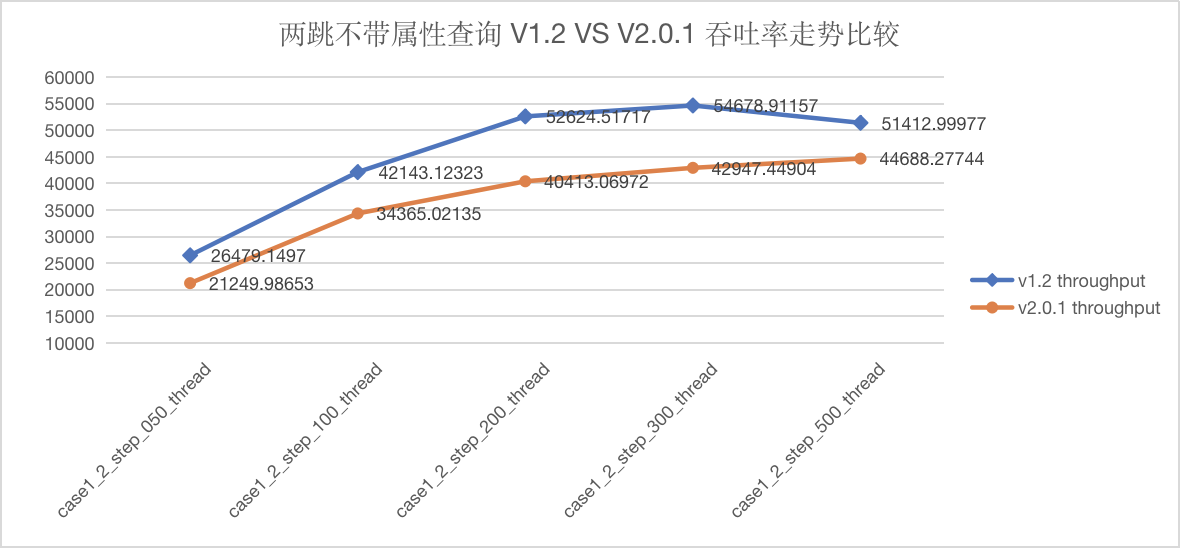
图5-4 CASE1 两跳跳查询吞吐量
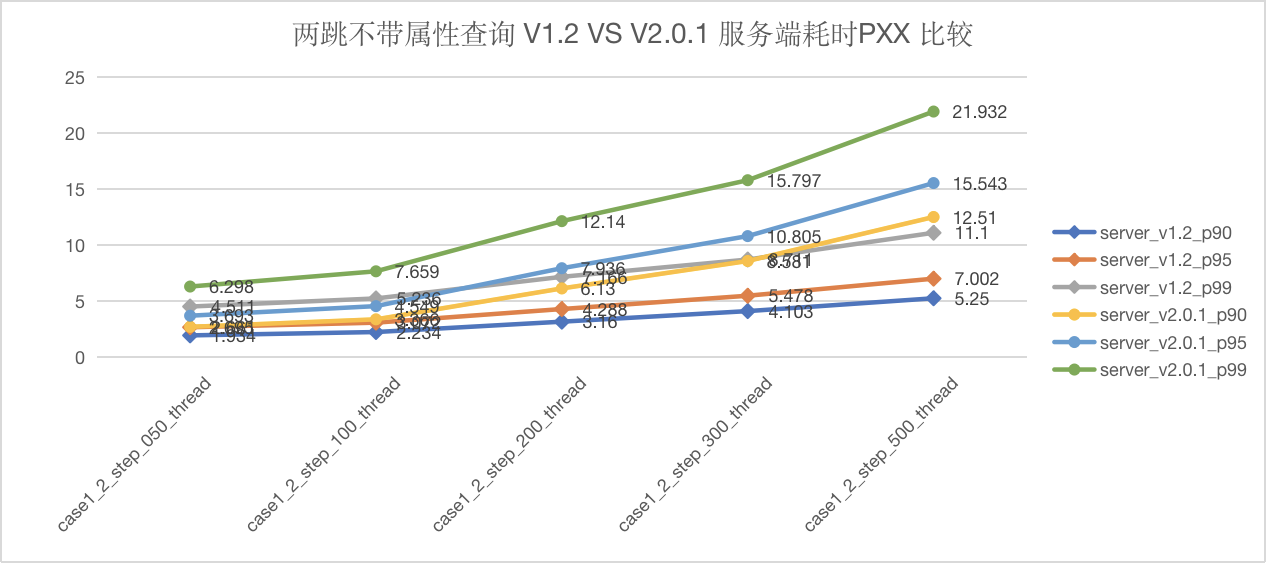
图5-5 CASE1 两跳查询服务端延迟
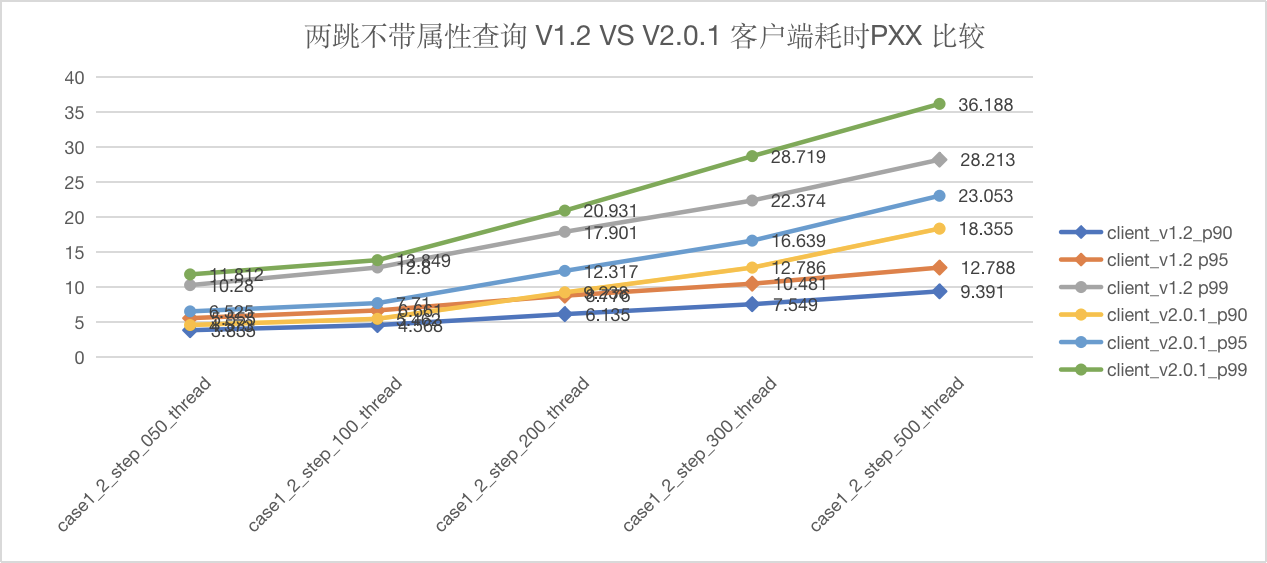
图5-6 CASE1 两跳查询客户端延迟
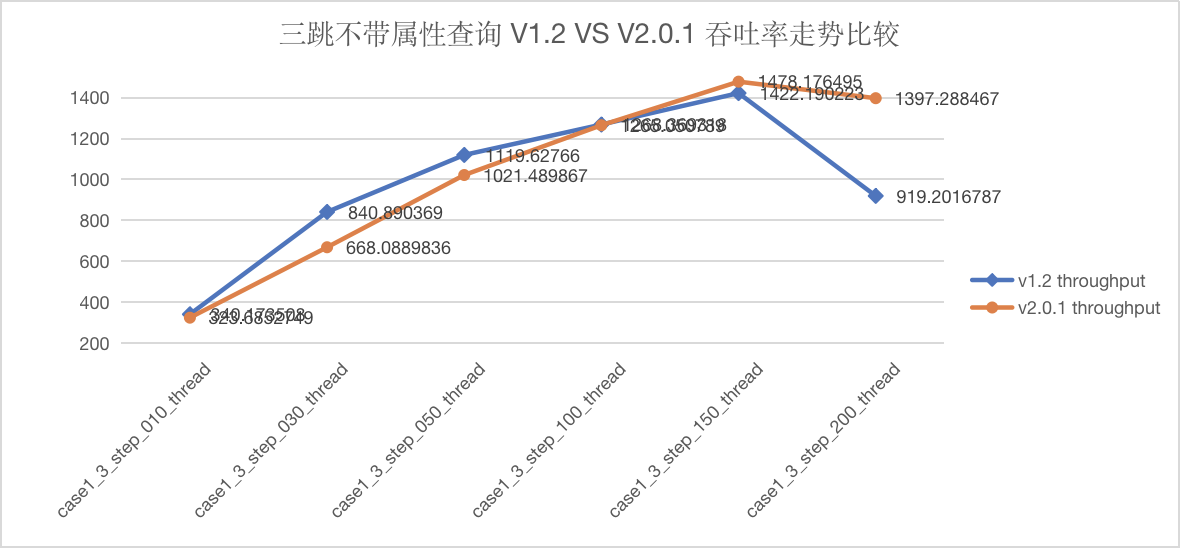
图5-7 CASE1 三跳查询吞吐量
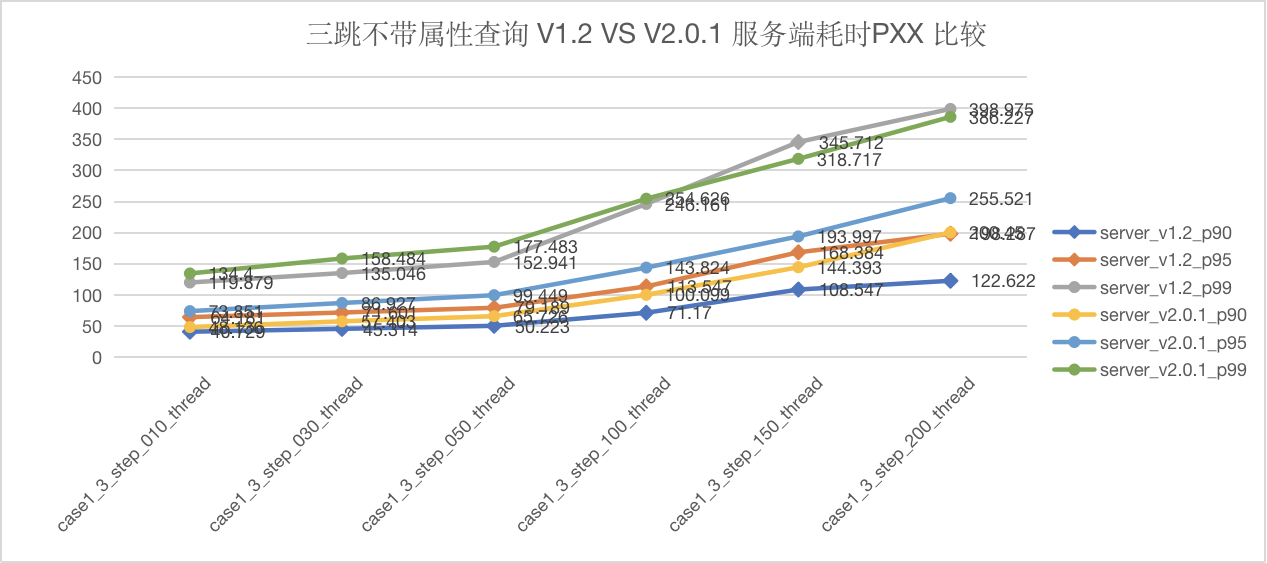
图5-8 CASE1 三跳查询服务端延迟

图5-9 CASE1 三跳查询客户端延迟
5.2.2 CASE2
语句 GO {N} STEP FROM {vid} OVER knows yield knows.time 测试结果:
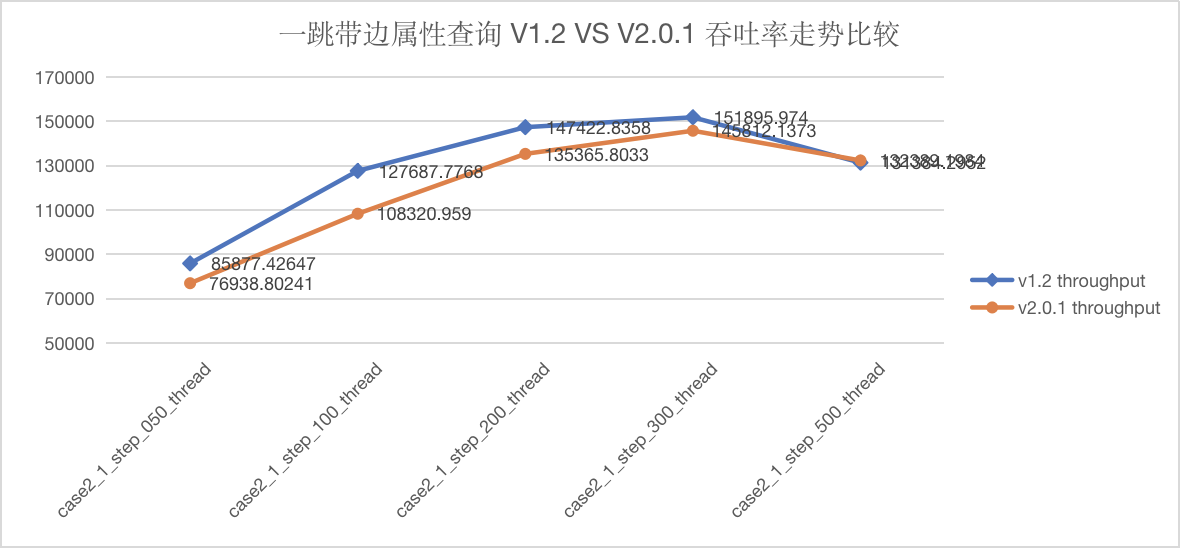
图5-10 CASE2 一跳查询吞吐量
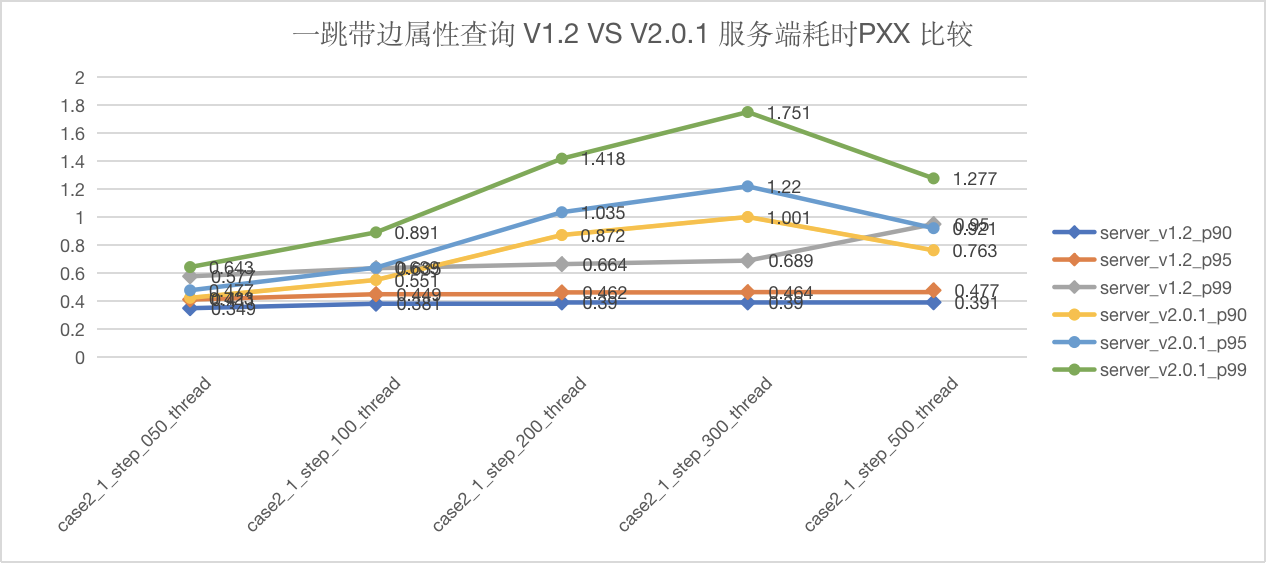
图5-11 CASE2 一跳查询服务端延迟
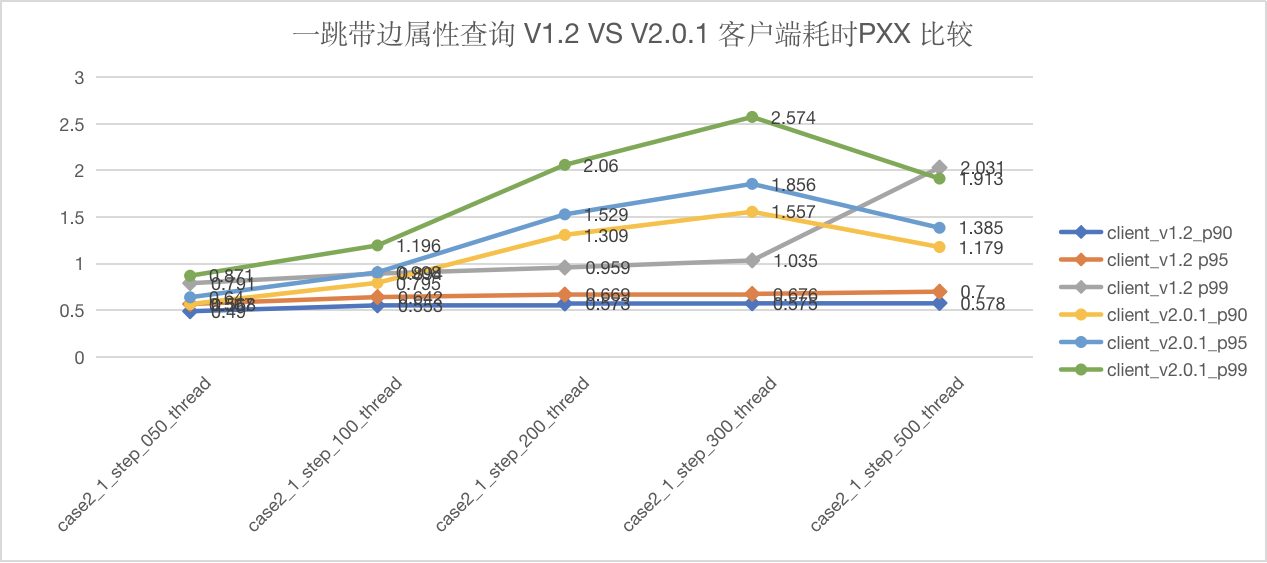
图5-12 CASE2 一跳查询服务端延迟
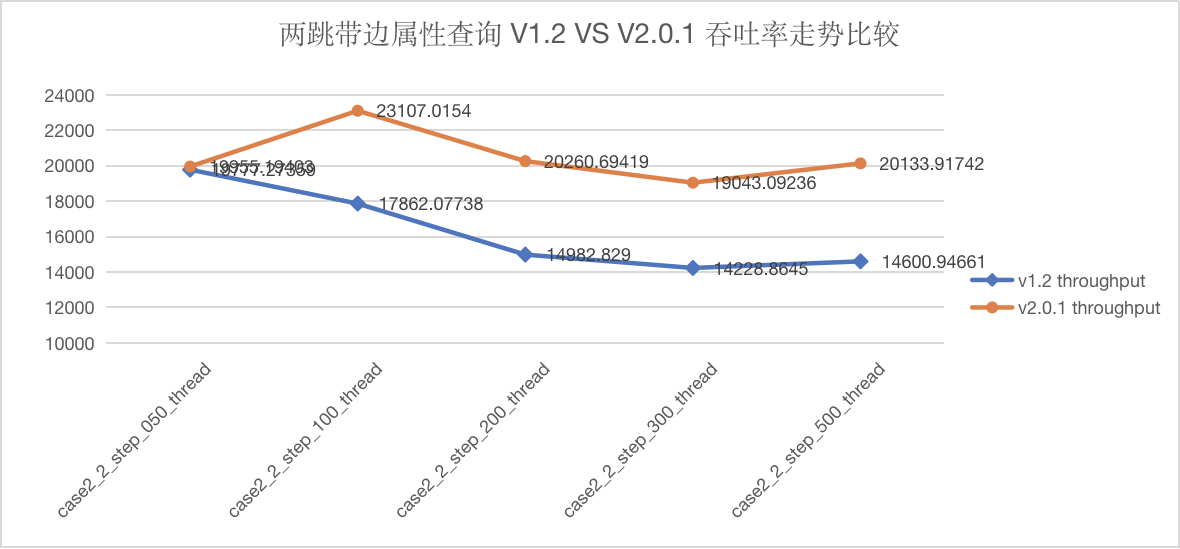
图5-13 CASE2 两跳查询吞吐量
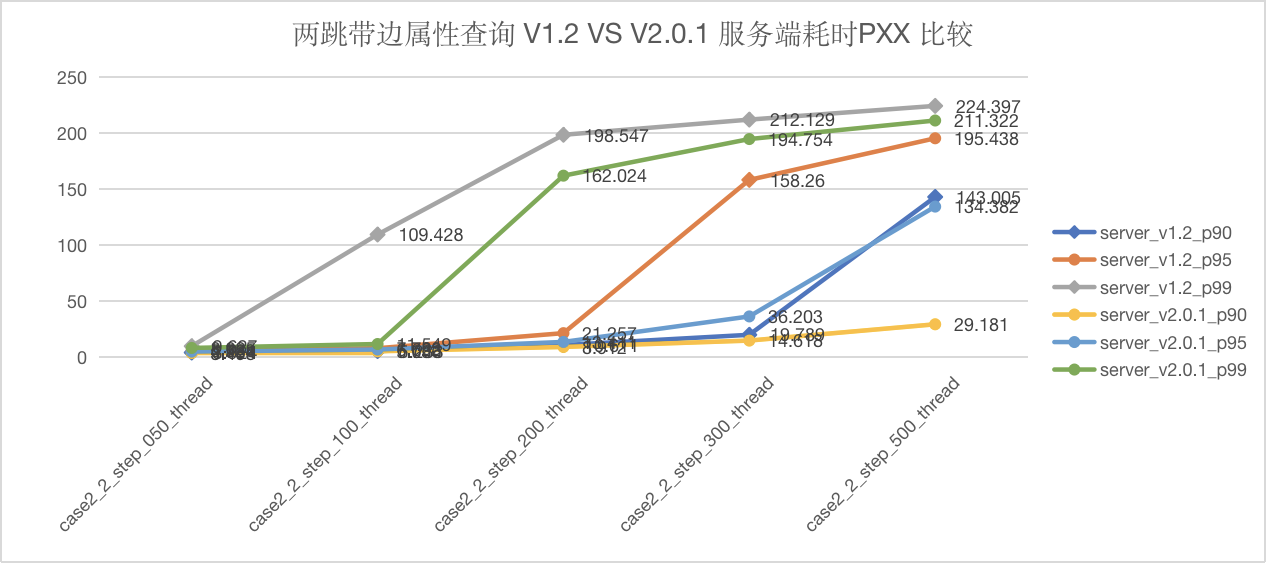
图5-14 CASE2 两跳查询服务端延迟
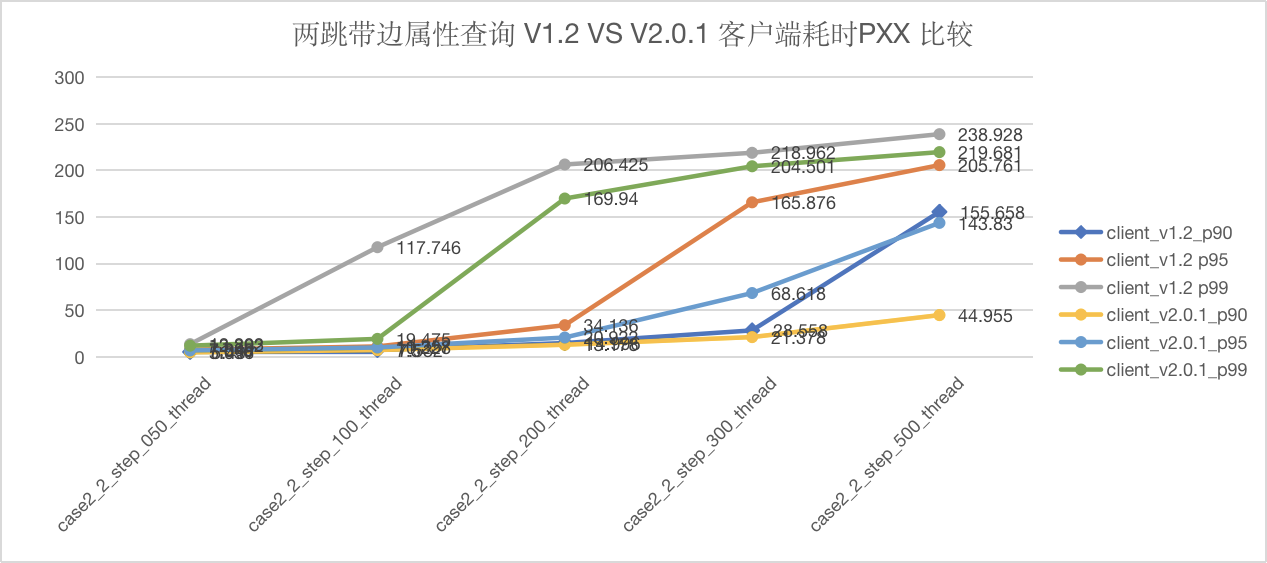
图5-15 CASE2 两跳查询客户端延迟
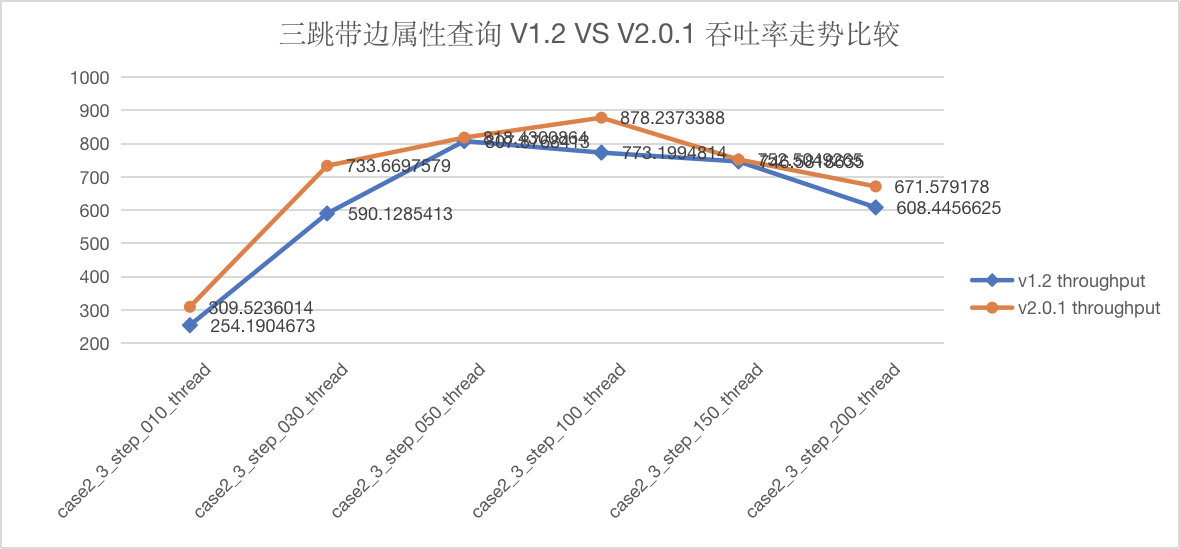
图5-16 CASE2 三跳查询吞吐量

图5-17 CASE2 三跳服务端延迟

图5-18 CASE2 三跳客户端延迟
5.2.3 CASE3
语句 GO {N} STEP FROM {vid} OVER knows yield $$.person.first_name 测试结果
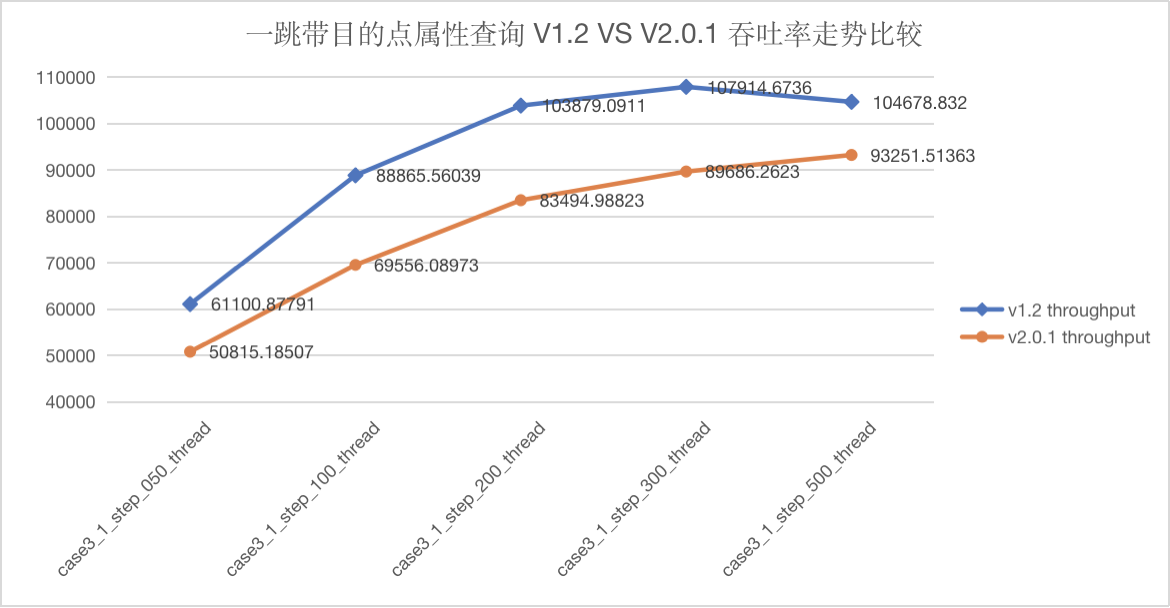
图5-19 CASE3 一跳吞吐量
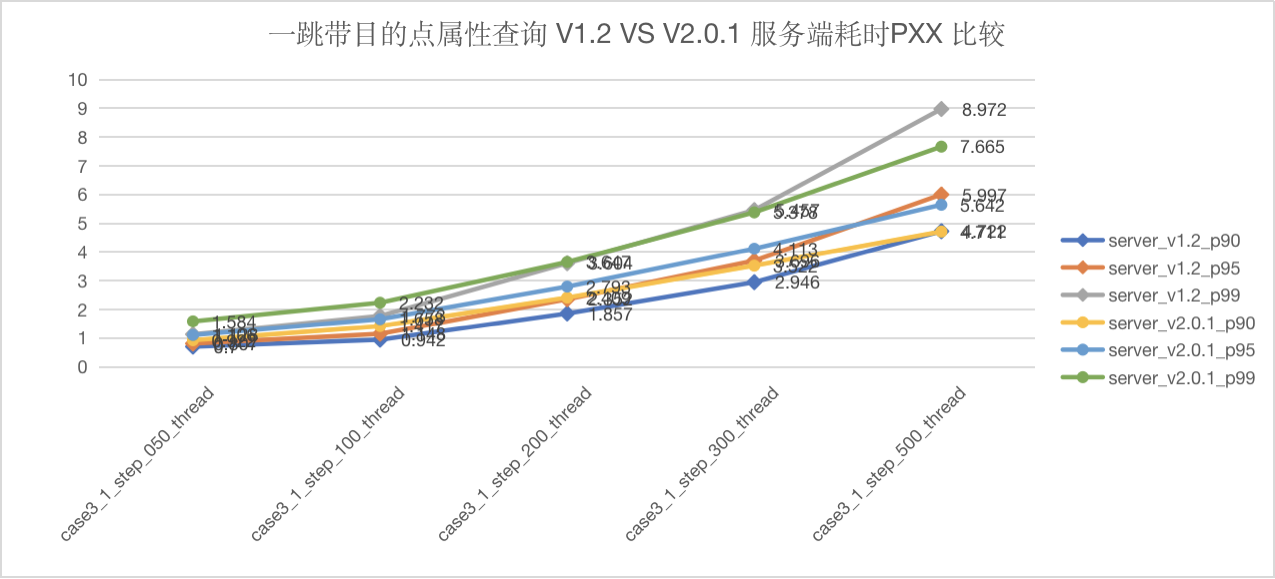
图5-20 CASE3 一跳服务端延迟
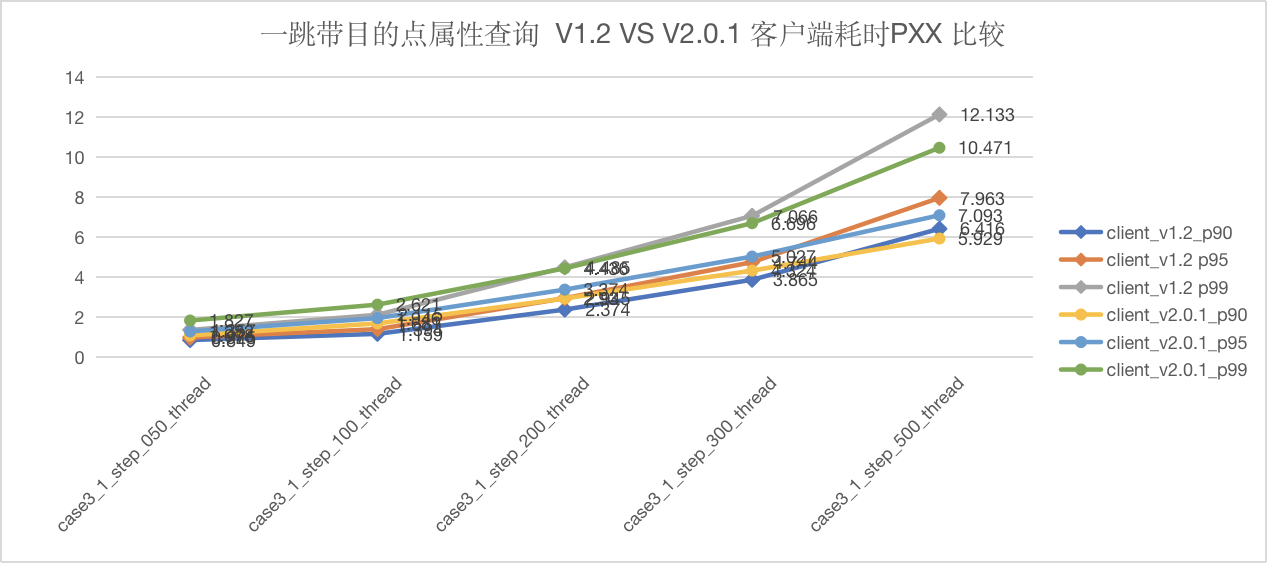
图5-21 CASE3 一跳客户端端延迟

图5-22 CASE3 两跳吞吐量
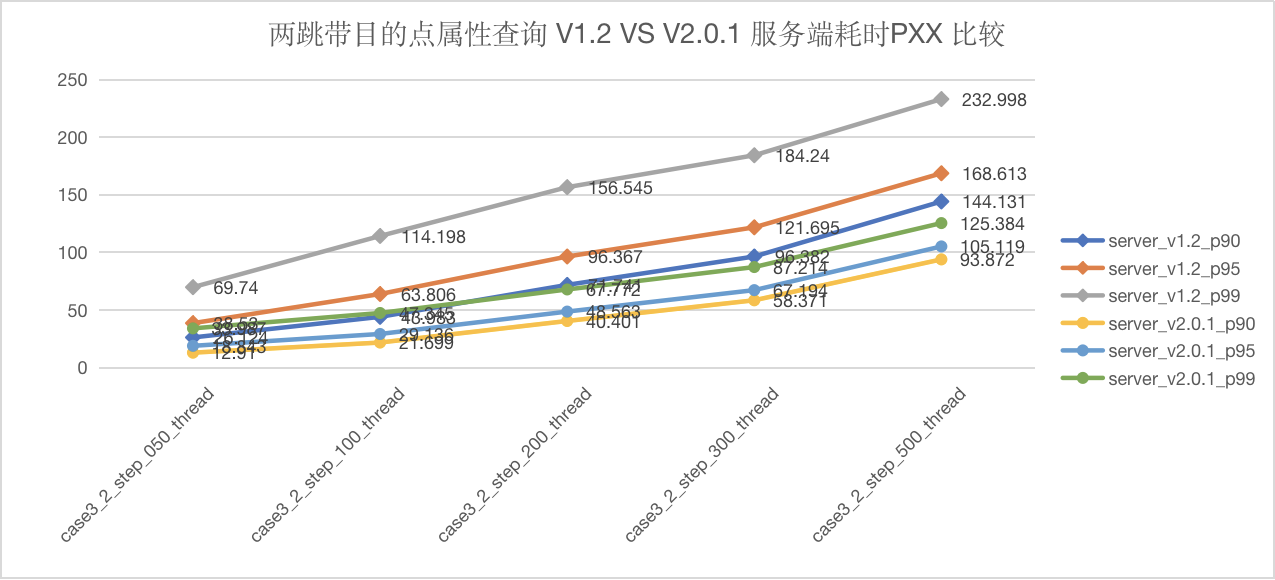
图5-23 CASE3 两跳服务端延迟
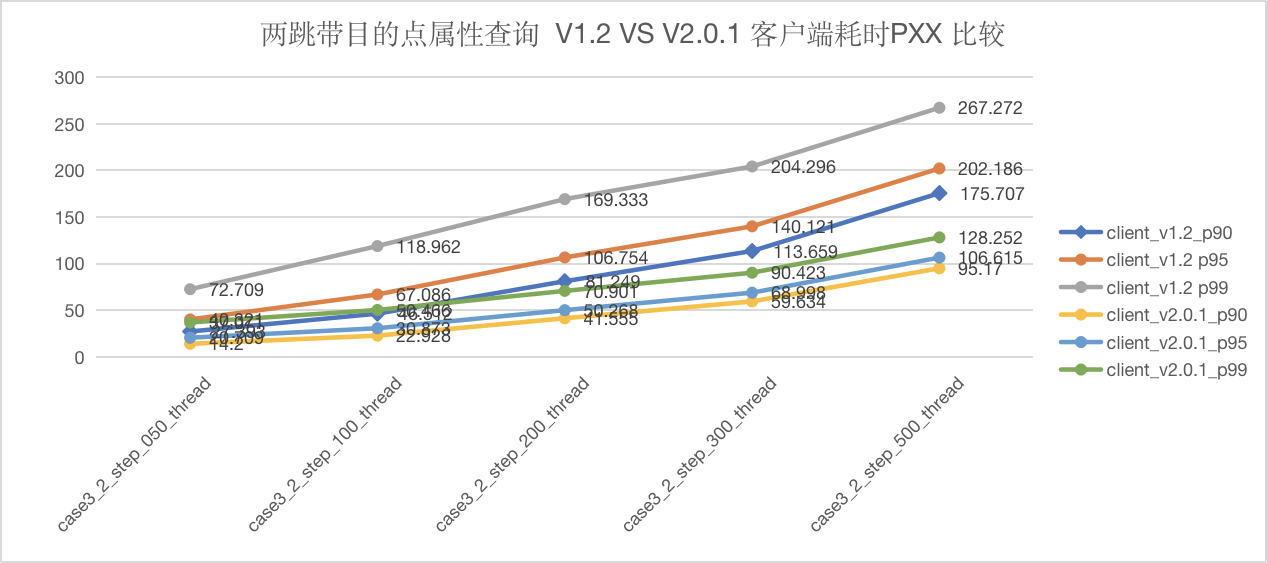
图5-24 CASE3 两跳客户端延迟
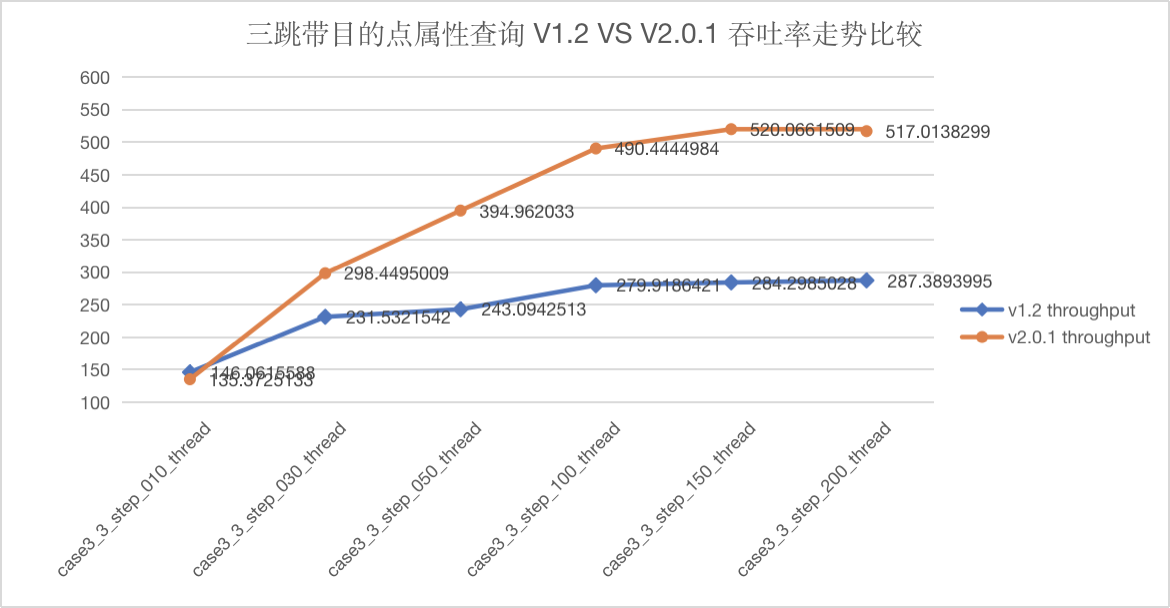
图5-25 CASE3 三跳吞吐量

图5-26 CASE3 三跳服务端延迟

图5-27 CASE3 三跳客户端延迟
5.2.4 CASE4
语句 GO {N} STEP FROM {vid} OVER knows YIELD DISTINCT knows.time as t, $$.person.first_name, $$.person.last_name, $$.person.birthday as birth | order by $-.t,$-.birth | limit 10 测试结果

图5-28 CASE4 一跳吞吐量

图5-29 CASE4 一跳服务端耗时

图5-30 CASE4 一跳客户端耗时
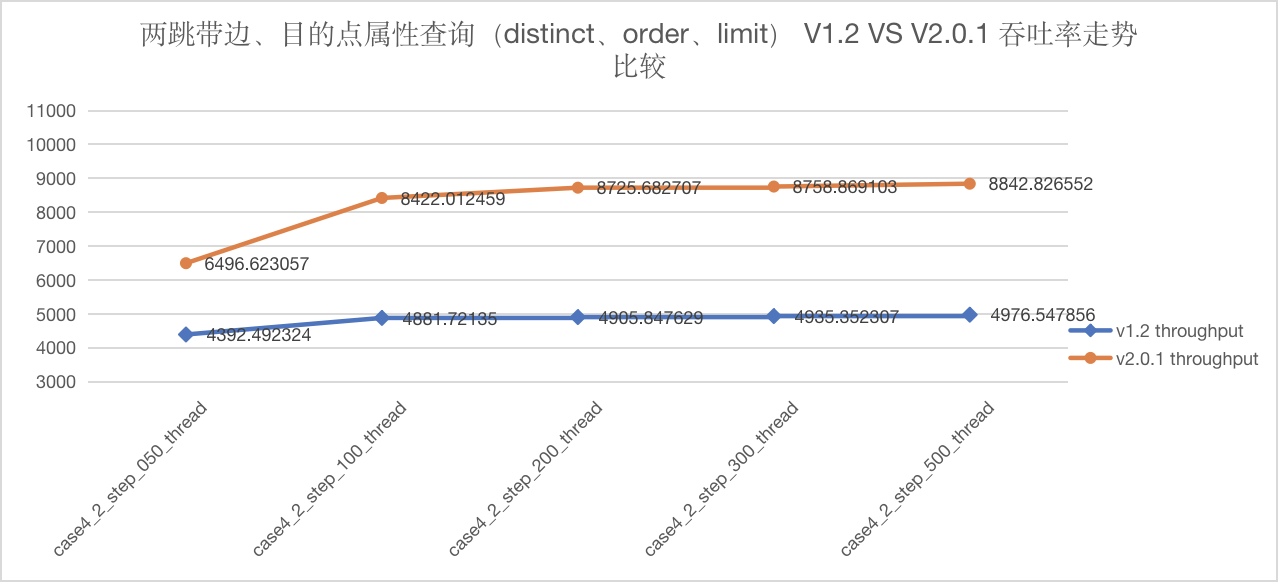
图5-31 CASE4 两跳跳吞吐量
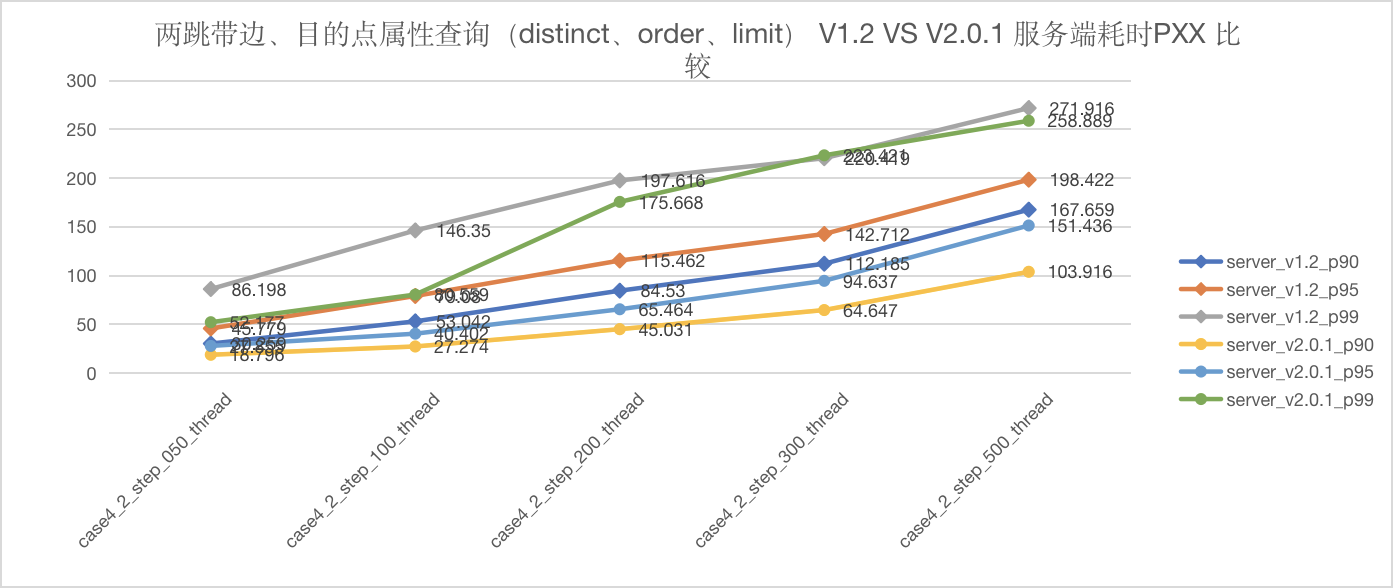
图5-32 CASE4 两跳服务端延迟
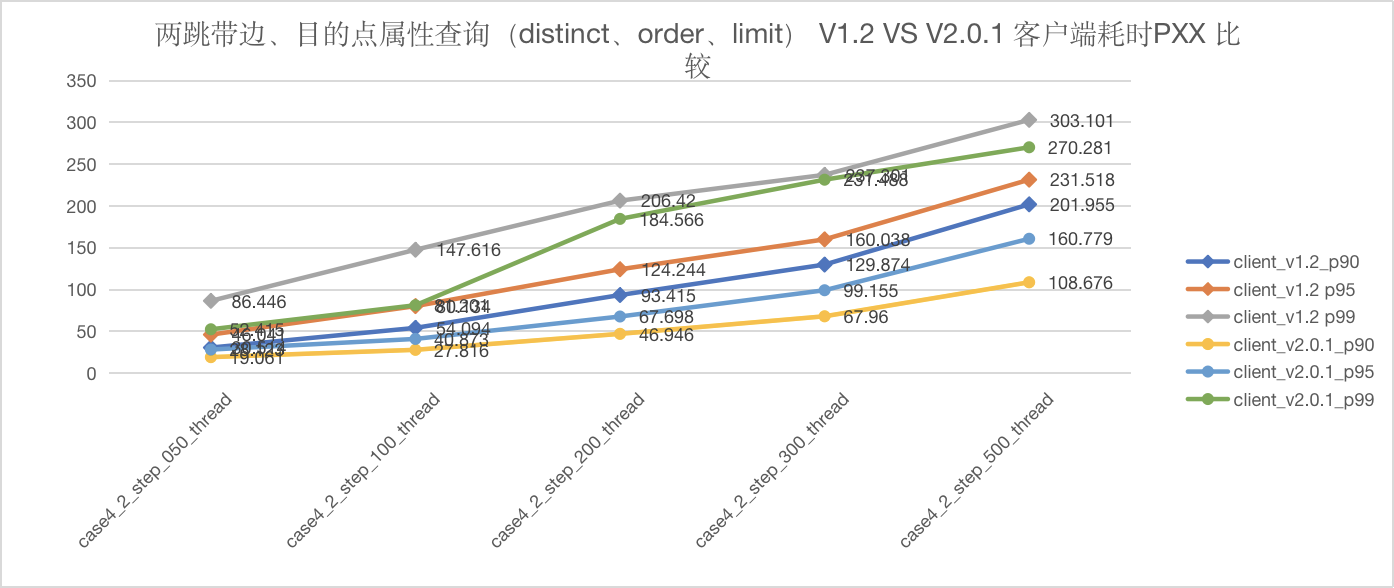
图5-33 CASE4 两跳客户端耗时
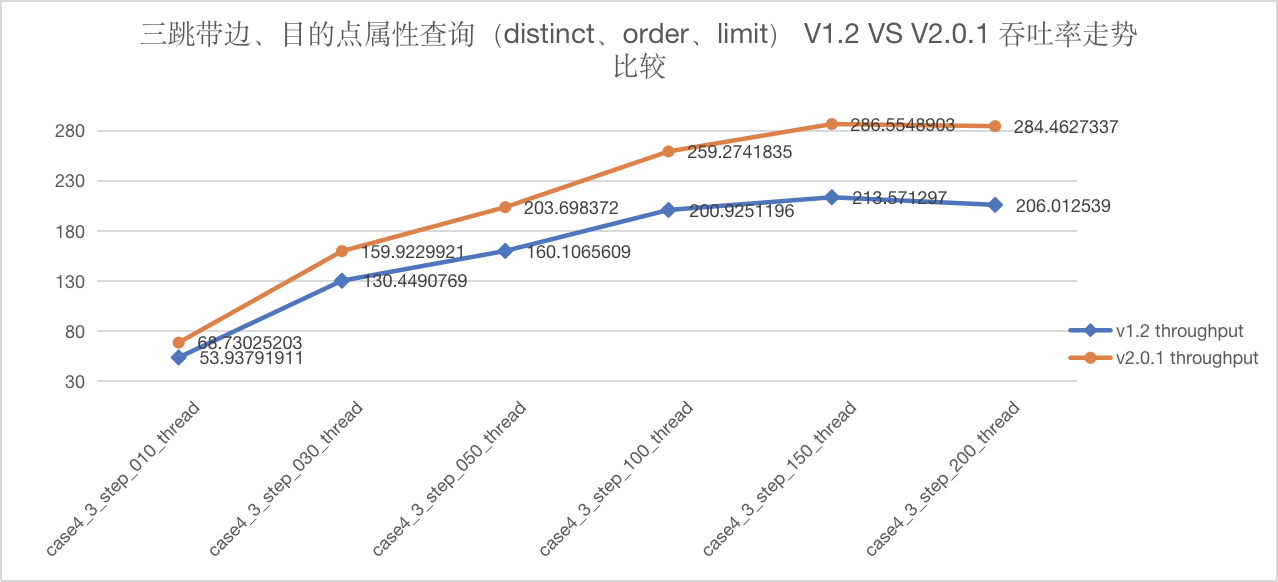
图5-34 CASE4 三跳吞吐量

图5-35 CASE4 三跳服务端耗时
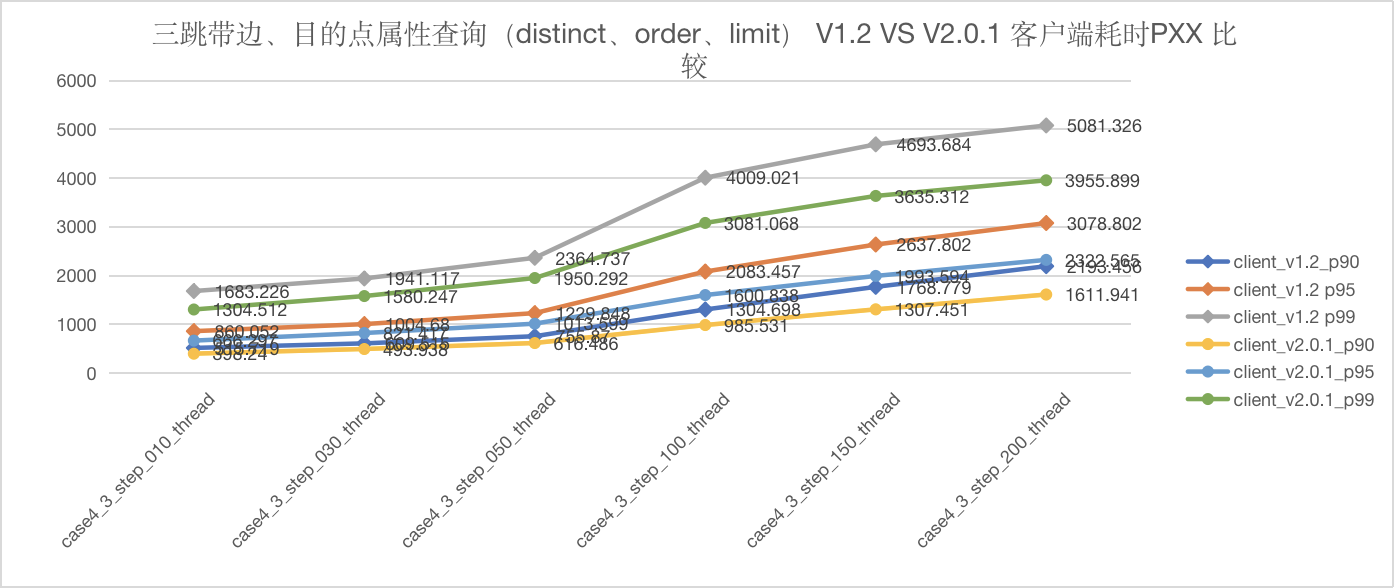
图5-36 CASE4 三跳客户端耗时
5.3 测试结果说明
与 Nebula v1.2.0 相比,Nebula v2.0.1 在多跳场景下吞吐量有较大提升,同时延迟也得到了降低。
在单跳场景下,Nebula v2.0.1 吞吐量有所下降,同时延迟也有相应上升。究其原因,主要是因为 Nebula v2.0.1 将查询语句拆分成多个子任务的查询计划,导致异步任务剧增。由于一跳场景都是小任务,所以在高吞吐情况下,会出现任务排队,导致延迟上升,同时吞吐量相比 v1.2.0 有所下降。
性能测试对比报告.pdf (3.3 MB)