- nebula 版本:2.0.0
- 部署方式(分布式 / 单机 / Docker / DBaaS):docker swarm
- 是否为线上版本:Y / N
- 硬件信息
- 磁盘( 推荐使用 SSD)
- CPU、内存信息
- 问题的具体描述
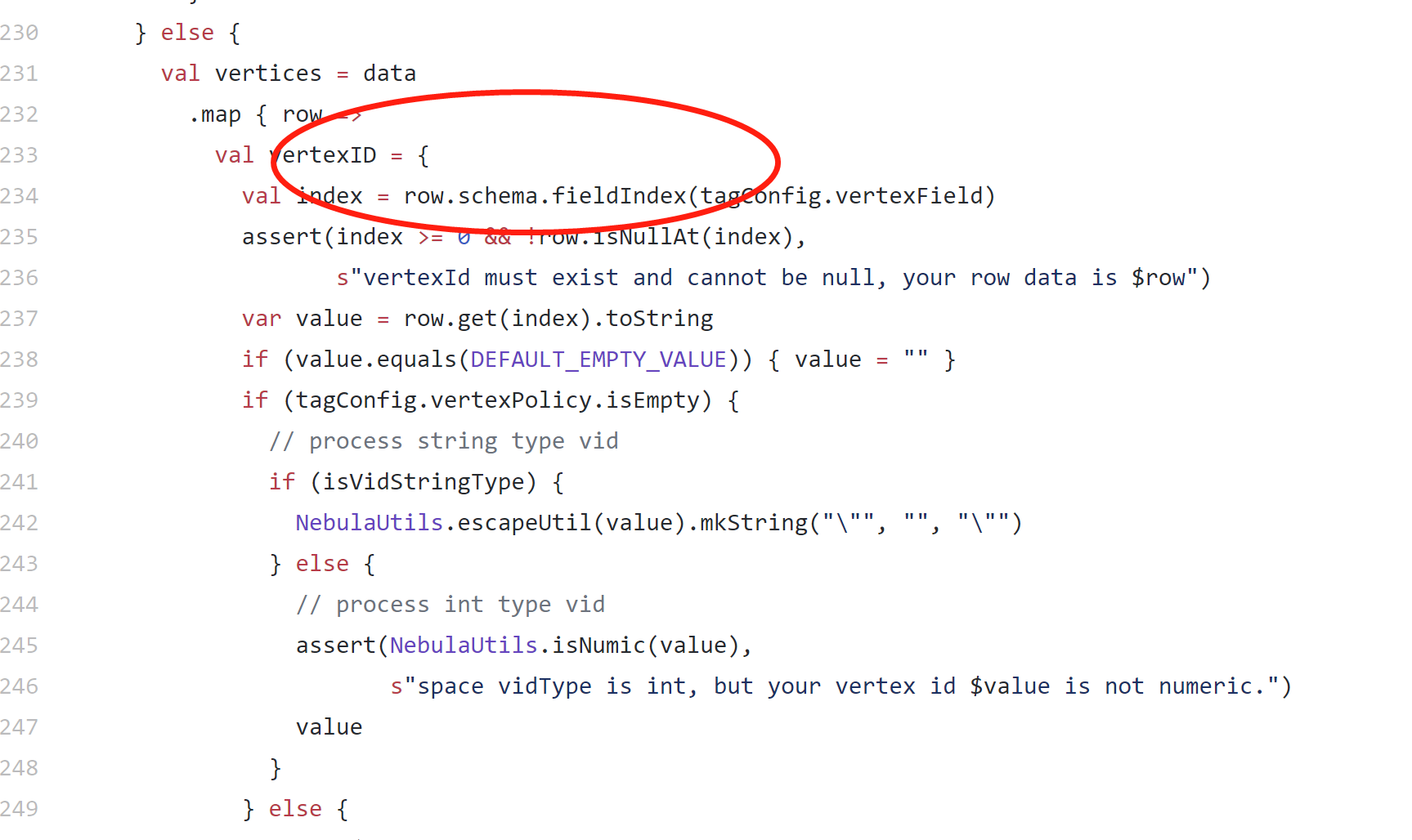
spark exchange 2.0 对接kafka数据是不是没有对kafka的数据进行解析
我看源码,直接取了kafka接入的数据,这个是没有对value进行解析的,直接写入数据库应该是会有问题的
spark exchange 2.0 对接kafka数据是不是没有对kafka的数据进行解析
我看源码,直接取了kafka接入的数据,这个是没有对value进行解析的,直接写入数据库应该是会有问题的
对,读取是kafka固定的key, value, topic, partition, offset, timestamp, timestampType这些字段,目前没有对value的解析。
有计划增加value的解析: 在支持固定字段的同时增加value的解析,以[key, topic, offset, value.a, value.b, value.c ]的形式配置value中的值。也欢迎社区同学一起参与~
好的,那我先自己解析了