nebula 版本:v2.0.1
部署方式(分布式-k8s):
硬件信息
磁盘:ssd
CPU、内存信息:4核、8g
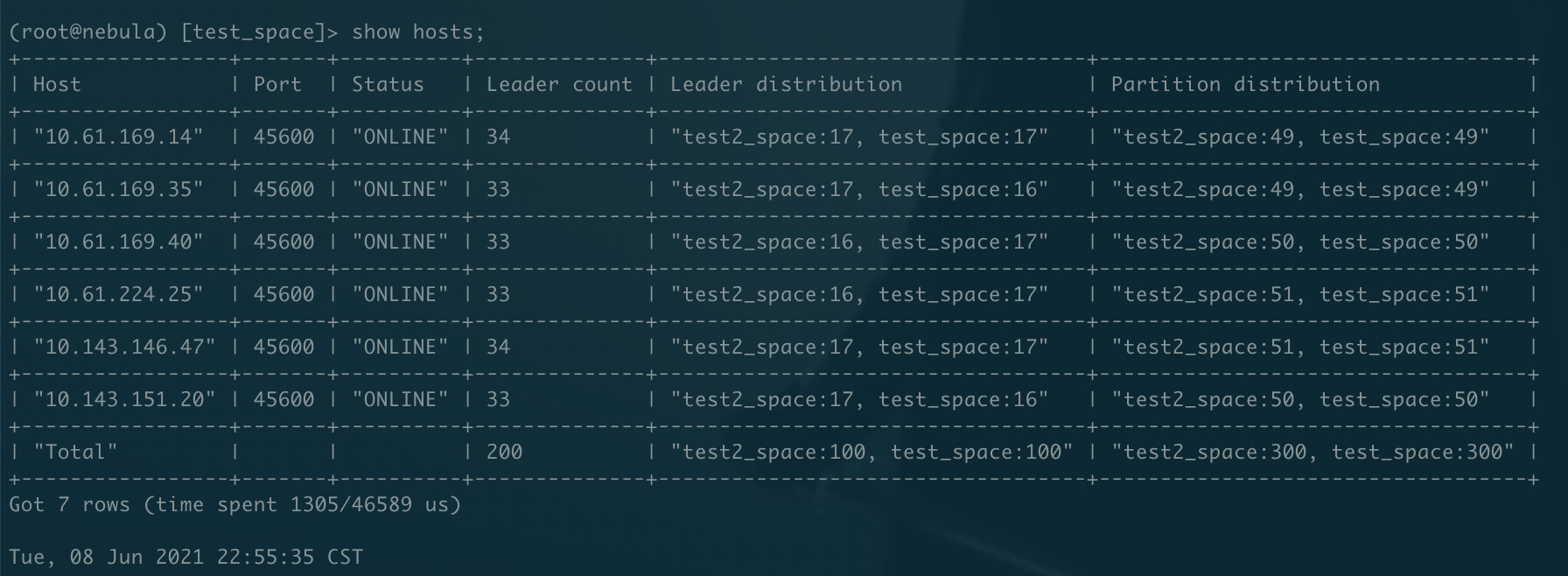
图空间&分区
create space if not exists test_space(partition_num=100, replica_factor=3, vid_type=Int64)
create tag people(f1 int, f2 string, f3 string default '')
create tag index people_index on people()
压测方式:
session通过一个负载均衡的地址进行创建多个。
每个线程写入100次。
写入语句,每次写入变更vid.
insert vertex people(f1, f2) values 1623163868926697:(1, 'f2-1'), 1623163276148835:(1, 'f2-1'),1623163195103130:(1, 'f2-1'),1623163646933444:(1, 'f2-1'),1623163257678349:(1, 'f2-1'),1623163390513198:(1, 'f2-1');
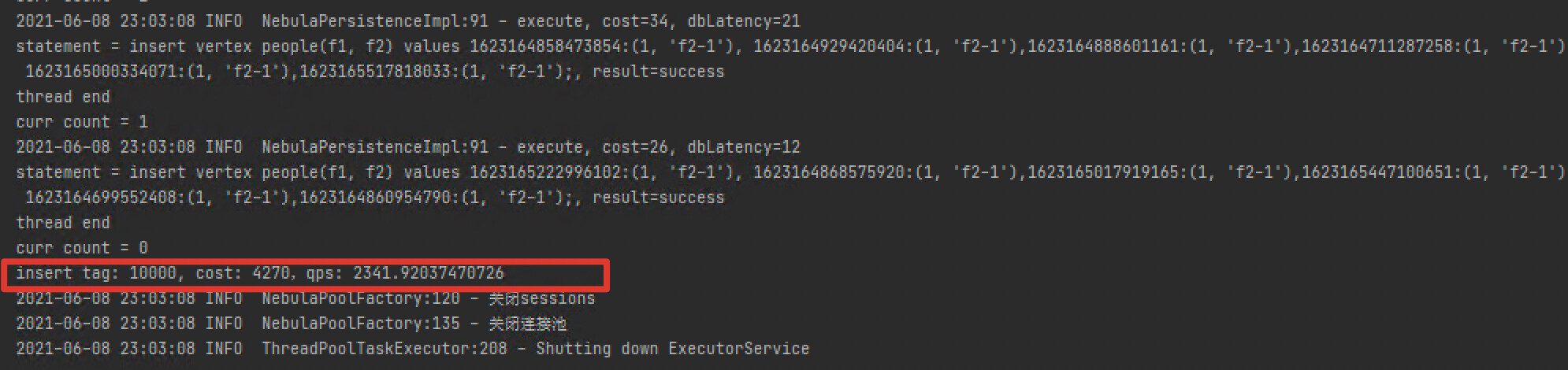
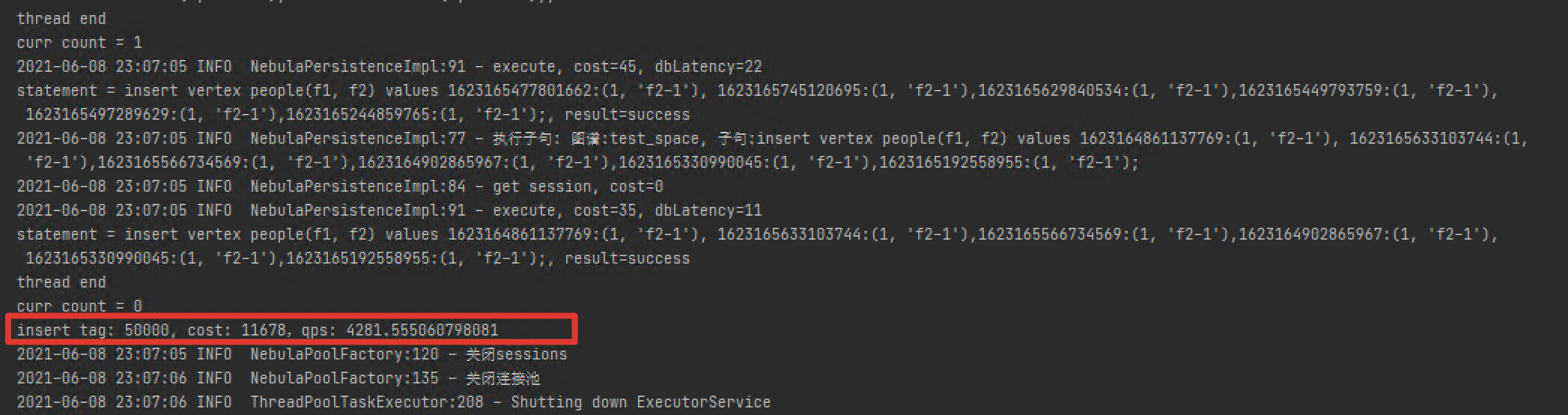
写入速度:
创建100个session,然后使用100线程并行写入,每个线程写入100次情况下,每秒写入仅2341次 。
创建500个session,然后使用500线程并行写入,每个线程写入100次情况下,在对tag创建点索引的情况下,每秒写入仅4281次 。
创建500个session,然后使用500线程并行写入,每个线程写入100次情况下,在对tag不创建点索引的情况下,每秒写入仅4539次 。
wey
2021 年6 月 9 日 02:46
3
@jmq2020 mq, 据@cangchen8180 和我描述,他的场景是线上实时的写入,会一直有写入,所以如果需要索引就不能在插入之后再建立索引。
调用API的时候用batch的方式: (如图所示的地方, 一次填个1000条)
[image]
看看这个, 可以论坛也同时搜搜。插入性能的其他帖子,看看有没有其他人和你的场景一样
wey
2021 年6 月 9 日 02:57
5
@cangchen8180 你的client场景允许 buffer 一下然后从client上 batch 么?按照我之前和你沟通的理解,你们对实时性的要求使得 client 不允许做 batch?
nebula的java client如何batch提交?没找到api,我只能一次insert多条。
k8s 的 PV 是用的 LocalPV 么?
如果 importer 也还是慢的话,用 k8s 启一个 pod,看下 io 的监控数据。
1 个赞
wey
2021 年6 月 9 日 06:55
10
我去问了 client的同学,batch 的手段就是你之前做的把多个点、边放到同一个语句里。这里你相当于是 6(按照咱们原来说的),这里的 6 业务上有可能变得更大么?
业务上也会是多个吧,不会太大,一次写入最多几十个点和边。
1 个赞
HarrisChu:
k8s 的 PV 是用的 LocalPV 么?
是的。
HarrisChu:
用 importer 导入试试
用importer和java client有区别?
wey
2021 年6 月 9 日 07:16
13
HarrisChu:
可以先用 importer 导入试试
@HarrisChu jp 这里用 importer 是控制客户端变量,先调优 server side的考量对么?
wey
2021 年6 月 9 日 07:25
14
cangchen8180:
HarrisChu:
k8s 的 PV 是用的 LocalPV 么?
是的。
咱们是Helm部署的对吧,能贴一下相关的配置的 yaml么?
只是做比对,importer 我测过,k8s 使用 NFS 的共享 PV,batch 2,一个 graph 并发 100,都有 4000+/s,如果你是 localPV 的话,理论上会更快的。
system
2021 年7 月 9 日 09:44
16
该主题在最后一个回复创建后30天后自动关闭。不再允许新的回复。