集群:
- nebula 版本:v2.0.1
- 部署方式:(分布式-k8s)
- 硬件信息
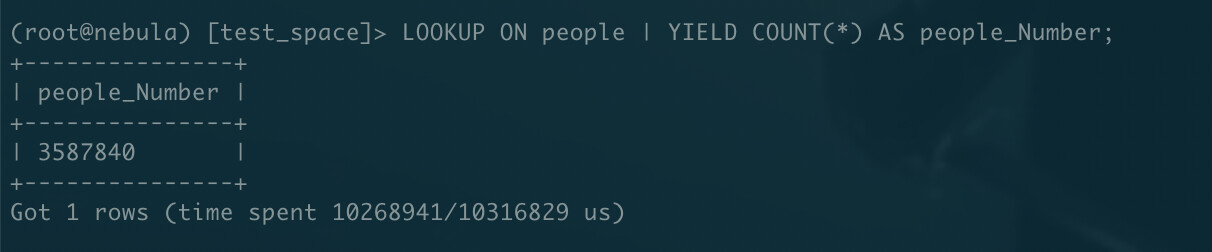
一共3百多万tag,在nebula-console下,使用match limit查询时,直接超时。
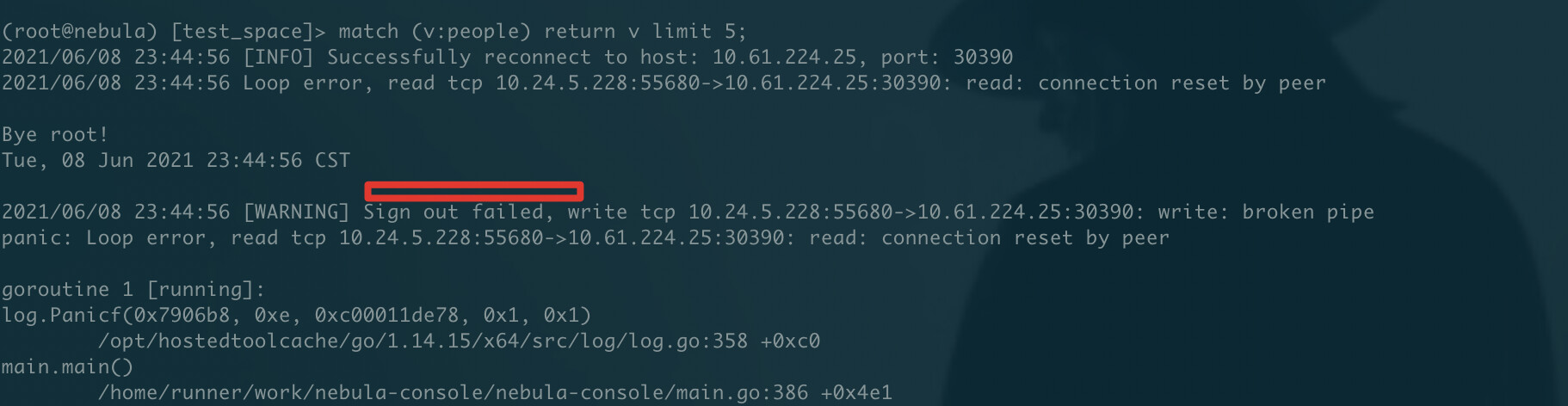
match (v:people) return v limit 5;
那如果我想这么查询的话,需要如何查询?
1 个赞
有core dump 文件产生吗, 可以把 nebula-graphd.ERROR 文件贴一下看看
1 个赞
只是超时,这个文件没有日志打出来。
另外,k8s部署,每个机器上都是这些文件?不同pod直接日志怎么看哪个是主的?
如果是超时的话,可以修改nebula-graphd.conf配置文件中的 --client_idle_timeout_sec=0
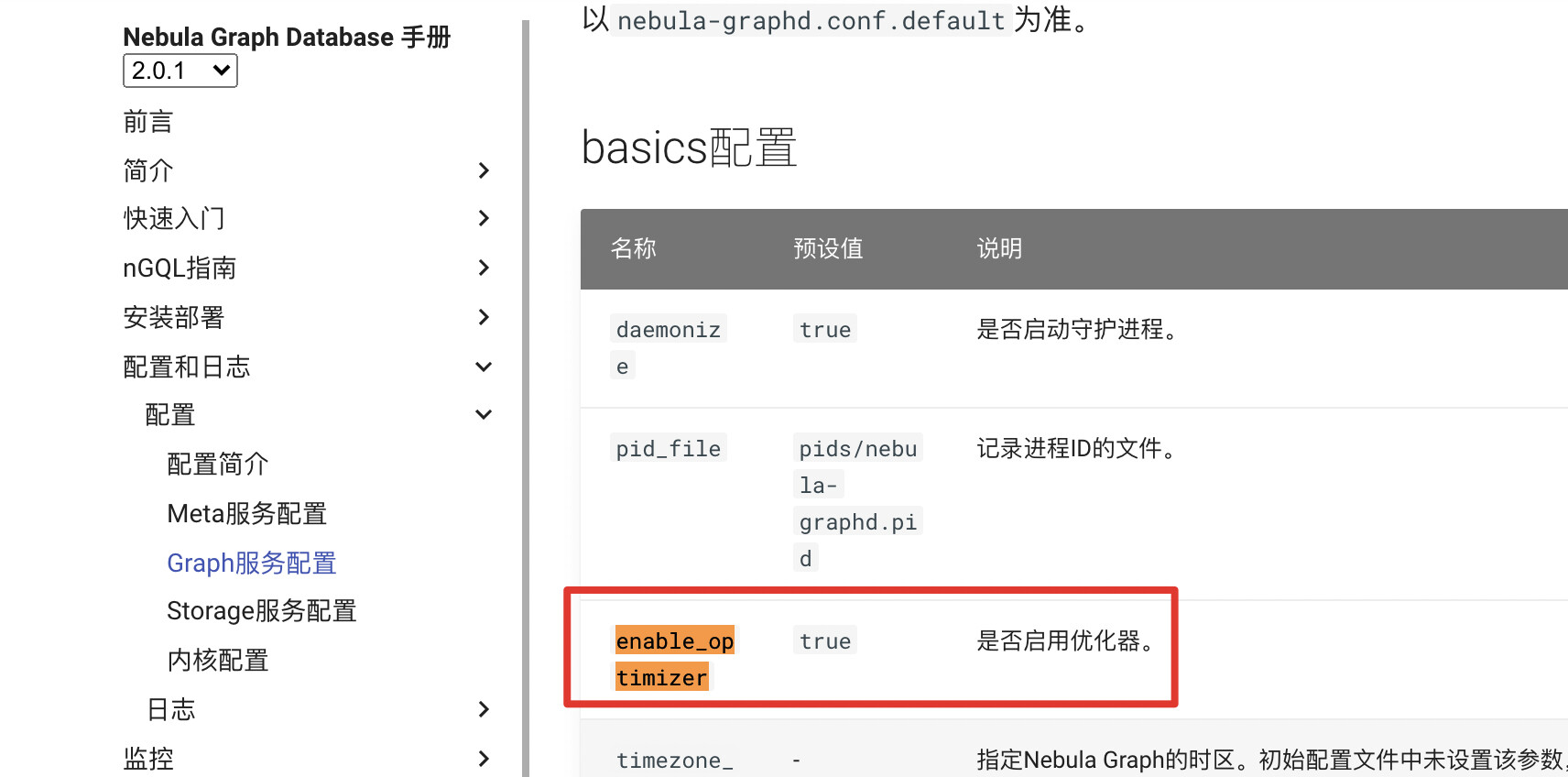
至于 match(v:people) return v limit5; 数据量大的话 可以把 --enable_optimizer=true 打开试试
1 个赞
wey
5
match (v) return v limit 5 的场景比较是全图搜索(OLAP)了,其实比较适合用 storage client 来做哈。
storaged client是全扫描吧?我看session没有相应接口。
另外,如果查询的where符合条件的比较多,应该没法用storaged client这种方式吧?
你这个case可以加优化规则,可以在nebula-graph中提个issue。
kyle
11
1 个赞
kyle
13
优化规则本身比较简单,但会涉及到一些实现的重构,可能会延后,具体关注一下 issue 吧
system
关闭
14
该话题在最后一个回复创建后30天后自动关闭。不再允许新的回复。