- nebula 版本:v2.0.1
- 部署方式(分布式 / 单机 / Docker / DBaaS):docker swarm
- 是否为线上版本:n
- 硬件信息
- 磁盘( 推荐使用 SSD)960g ssd
- CPU、内存信息 36 core,128g mem
- 问题的具体描述
- 相关的 meta / storage / graph info 日志信息
场景:
图空间副本数为1,新添加一个节点后,再balance data失败。
在论坛的其他帖子里有看到说1副本的可能不能做balance。不知道是不是这个原因。
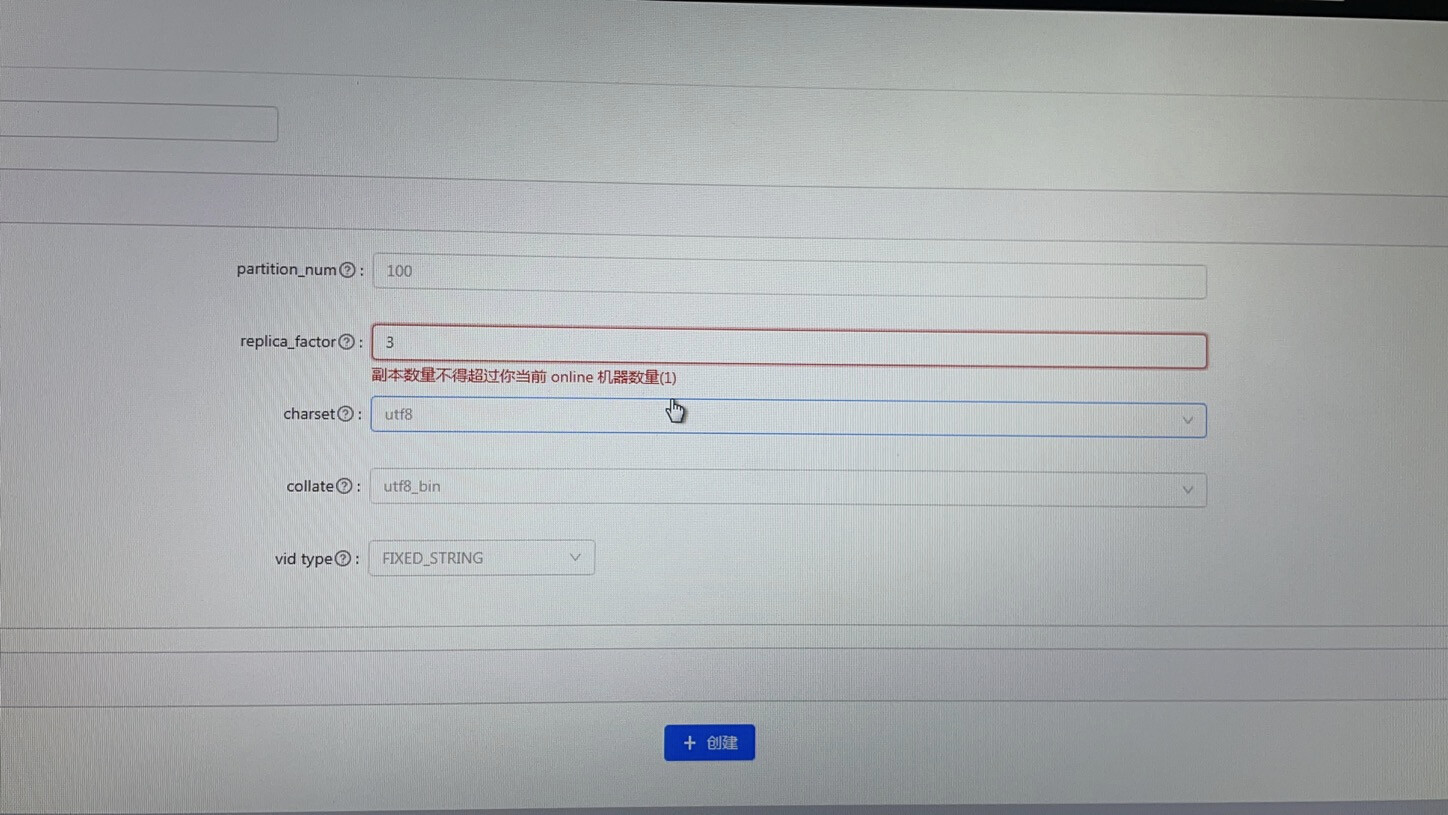
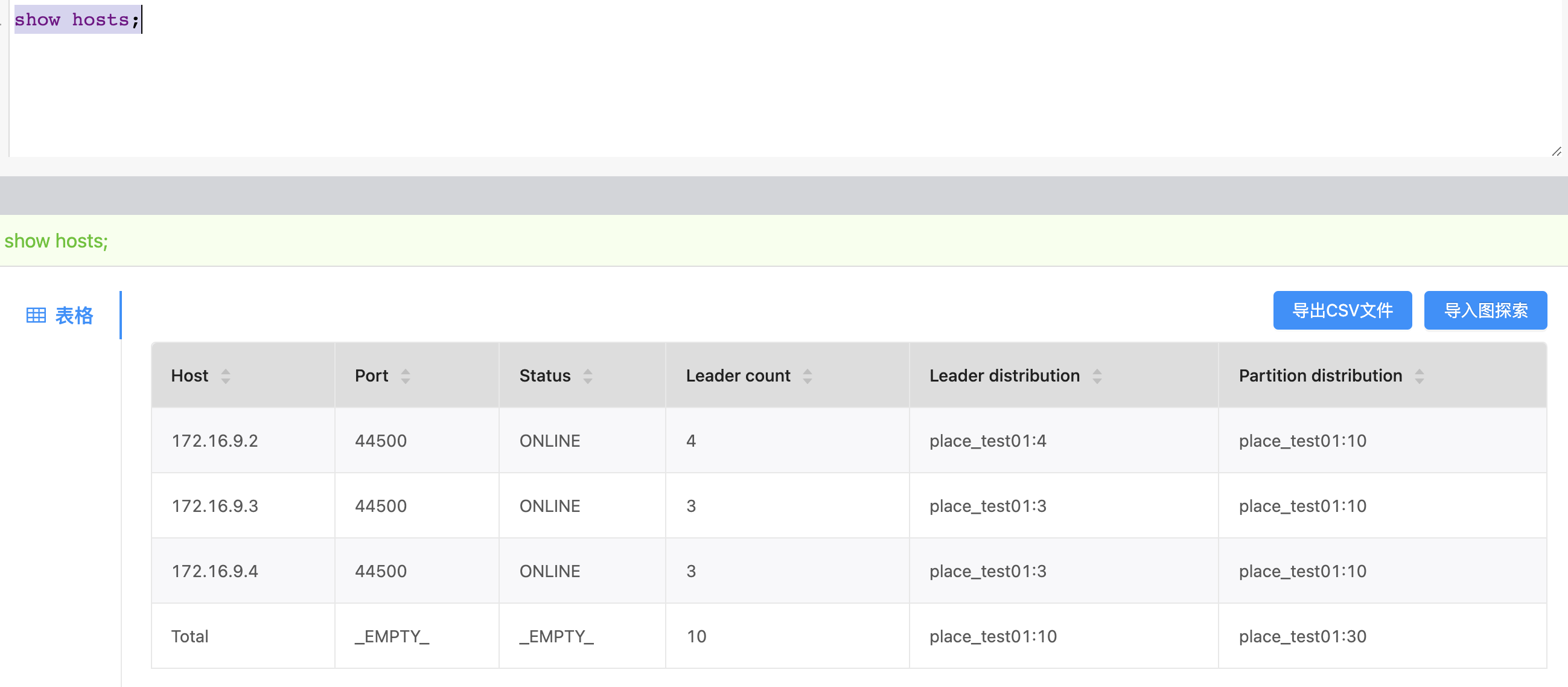
想新建一个3副本图空间,可是显示online机器数量不够。可是第一张图里是三台都online
新建一个副本为3的图空间还是会有balance data失败的问题
请问是什么不当操作会造成raft协议出问题呢?按理来说每台服务器配置和参数都一样,不应该就这一台出问题
从这次导入数据到balance这个过程中没有挂过。
之前的一次导入数据过程中192.122.3.11这台机器就出现过storage与meta节点通信出问题导致数据导入失败的问题。后来把它下线了,在这一次导入数据前重新上线。
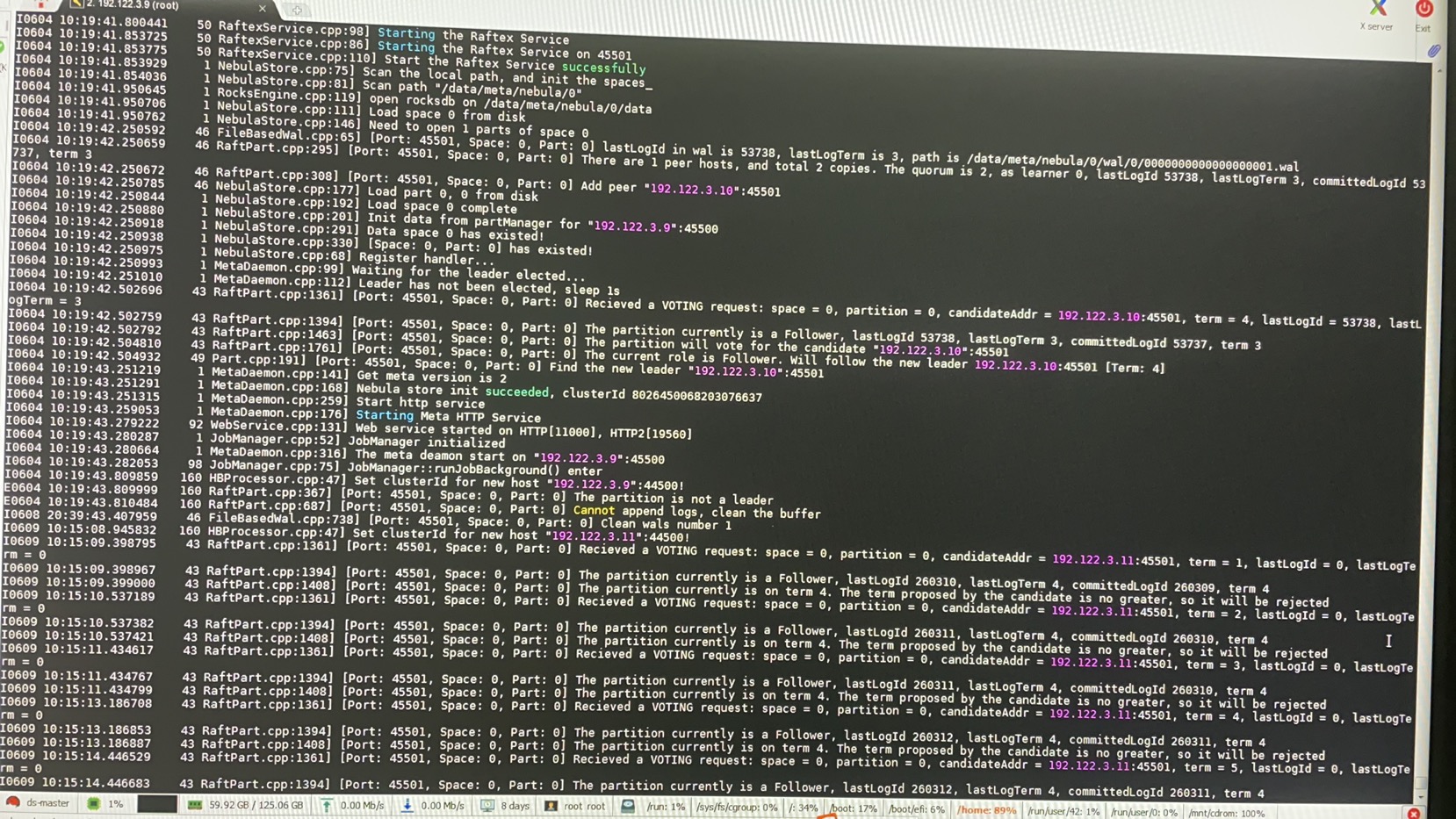
可以帮忙再看看吗  ,又换了个机房重新找了服务器复现错误。还是遇到了同样的问题,balance data失败。meta的日志如下
,又换了个机房重新找了服务器复现错误。还是遇到了同样的问题,balance data失败。meta的日志如下
@darionyaphet @dingding
看了一下源码发现是因为找不到space id报的错。
但是为什么会自动drop space呢?
我现在也在做扩容测试,我的主要出现一下问题
E0712 13:57:03.918248 23466 FileBasedWal.cpp:583] [Port: 9780, Space: 303, Part: 1] Failed to append log for logId 7542637
E0712 13:57:03.918275 23466 RaftPart.cpp:1588] [Port: 9780, Space: 303, Part: 1] Failed to append logs to WAL
我失败之后,就重新再执行一次,有些就能够成功了,有些还是不能成功,感觉有的像rart 通信的时候出错了,你可以再运行一次试试?
另外 想问一下你,你做了扩容失败之后数据会丢失的测试吗? 你是怎么做这个测试的?
Reid00
11
哦哦,好吧,我这边是线上环境,真是操作的时候要考虑这个
后面这次balance失败就是你看到的因为space已经被drop掉了,肯定不是自动drop的。
我一开始有一个space 副本为1,然后我drop掉了,又创建了一个space副本为3,再做的balance。这不是这样的操作流程会导致这个问题呢?
如果副本数小于机器数量就会balance data remove失败是么?我是3副本,3节点,这种情况下是不可以变成两节点的对吗?
在leader和partition都balance的情况下我执行remove报错的是"the cluster is balanced!"
system
关闭
19
该话题在最后一个回复创建后7天后自动关闭。不再允许新的回复。