nebula 版本:2.0.1
部署方式(分布式 ):
是否为线上版本:Y
pagerank算法中,weightCols的意义是什么,为什么指定该属性,更改属性值,但pagerank结果没有变化。
labels: ["friend"]
# Nebula edge property name for each edge type, this property will be as weight col for algorithm.
# Make sure the weightCols are corresponding to labels.
weightCols: ["degree"]
{"src":"12345","dst":"23456","degree":34, "descr": "aaa","timep": "2020-01-01"}
{"src":"11111","dst":"22222","degree":3300000, "descr": "aaa","timep": "2020-01-01"}
{"src":"11111","dst":"33333","degree":32, "descr": "a\baa","timep": "2020-01-01"}
{"src":"11111","dst":"44444","degree":31, "descr": "aaa","timep": "2020-01-01"}
{"src":"22222","dst":"55555","degree":30, "descr": "a\naa","timep": "2020-01-01"}
{"src":"33333","dst":"44444","degree":29, "descr": "aaa","timep": "2020-01-01"}
{"src":"33333","dst":"55555","degree":280, "descr": "aa\ta","timep": "2020-01-01"}
{"src":"44444","dst":"22222","degree":27, "descr": "aaa","timep": "2020-01-01"}
{"src":"44444","dst":"55555","degree":26, "descr": "aaa","timep": "2020-01-01"}
{"src":"22222","dst":"66666","degree":25000, "descr": "aaa","timep": "2020-01-01"}
前面有个参数用于配置 是否有权重,如果前面设定了false,weightCols怎么更改都没用的。
1 个赞
已经设置了hasWeight: true, 不管怎么调整边属性degree的值,得出的pagerank都是不变的。
Sorry, 前面回复没太针对pagerank这个算法。
PageRank的权重不是传入的,是1/出度数 计算出的,所以给更改源数据中的degree不会有影响的。
3 个赞
想问下PageRank中两个参数是什么意思?
设置为PRConfig(5, 0.0001)
使用graphx原始的
这个是测试数据
还有就是想问下Nebula Algorithm中每个算法参数和返回结果有没有简单的说明。
你调用的不是同一个算法接口,封装的algorithm中调用的是runWithOptions,你自己直接调用的是 runUntilConvergenceWithOptions。
PRConfig(maxIter: Int, resetProb: Double)
你调用的graph.pageRank()参数是tol阈值,参数含义是不同的。
runWithOptions和runUntilConvergenceWithOptions这两个有什么差别吗?迭代次数和残差概率怎么知道设置什么值合适?
stella
2021 年6 月 26 日 08:15
13
请问,2.0.1版本,使用pagerank算法时,指定边的出度与入度的VID必须要能转化成数值类型吗?否则就会报错
nicole
2021 年6 月 28 日 03:13
14
是的, 使用算法包会有限制的,我们推荐使用api的形式,通过Nebula-Spark-Connector进行nebula数据读取,并调用我们封装的算法api。
pandap
2021 年6 月 28 日 03:37
16
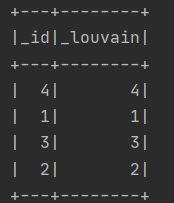
使用Louvain算法,algorithm返回的数据没有分社区,
nicole
2021 年6 月 28 日 03:57
17
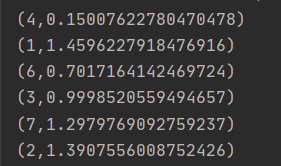
这个数据太小了吧,就4个点的话可以手动算一下看结果。
nicole
2021 年6 月 28 日 03:58
18
算法的输出形式是不一样的, 我们封装的算法包中所有算法的输出形式都是:
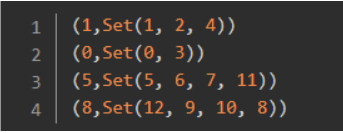
所以推荐使用api形式,这样可以根据业务进行输出定制化处理,比如Louvain结果改为社区id,当前社区的节点集合。
pandap
2021 年6 月 28 日 06:14
19
api形式是调用scala里面的方法吗?
这里面的示例和
这里面的不一样,
第一种需要对spark很熟悉才行。
还有有没有测试数据集,我看测试数据都是类似无向图这种?
人 A->商品 a,b,c
需要数据是
A->a
a->A
b->A
c->A
nicole
2021 年6 月 28 日 06:19
20
pandap
2021 年6 月 28 日 06:33
21
使用的第二种nebula-algorithm示例和测试文件,这种只要满足DataFrame形式就可以,
nicole
2021 年6 月 28 日 06:46
22
pandap:
还有想问下图计算有向可以配置吗?
看你需要用什么算法,我们提供的算法中部分是不需要了解方向性的,比如TriangleCount、Kcore、度统计等。
pandap
2021 年6 月 28 日 08:26
23
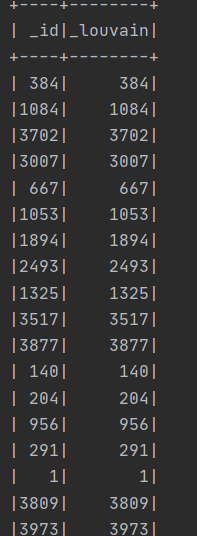
Louvain算法出来的id和_louvain都是这种结果。
system
2021 年7 月 5 日 08:27
24
该主题在最后一个回复创建后7天后自动关闭。不再允许新的回复。