- nebula 版本:2.0.1
- 部署方式(分布式 / 单机 / Docker / DBaaS):分布式
- 是否为线上版本:Y / N
- 硬件信息
- 磁盘( 推荐使用 SSD) ssd
- CPU、内存信息 96c
- 问题的具体描述
1.opencypher 的实现方式与原始的ngql语句有什么不一样?
在实际测试中的例子,go要比match快很多。。
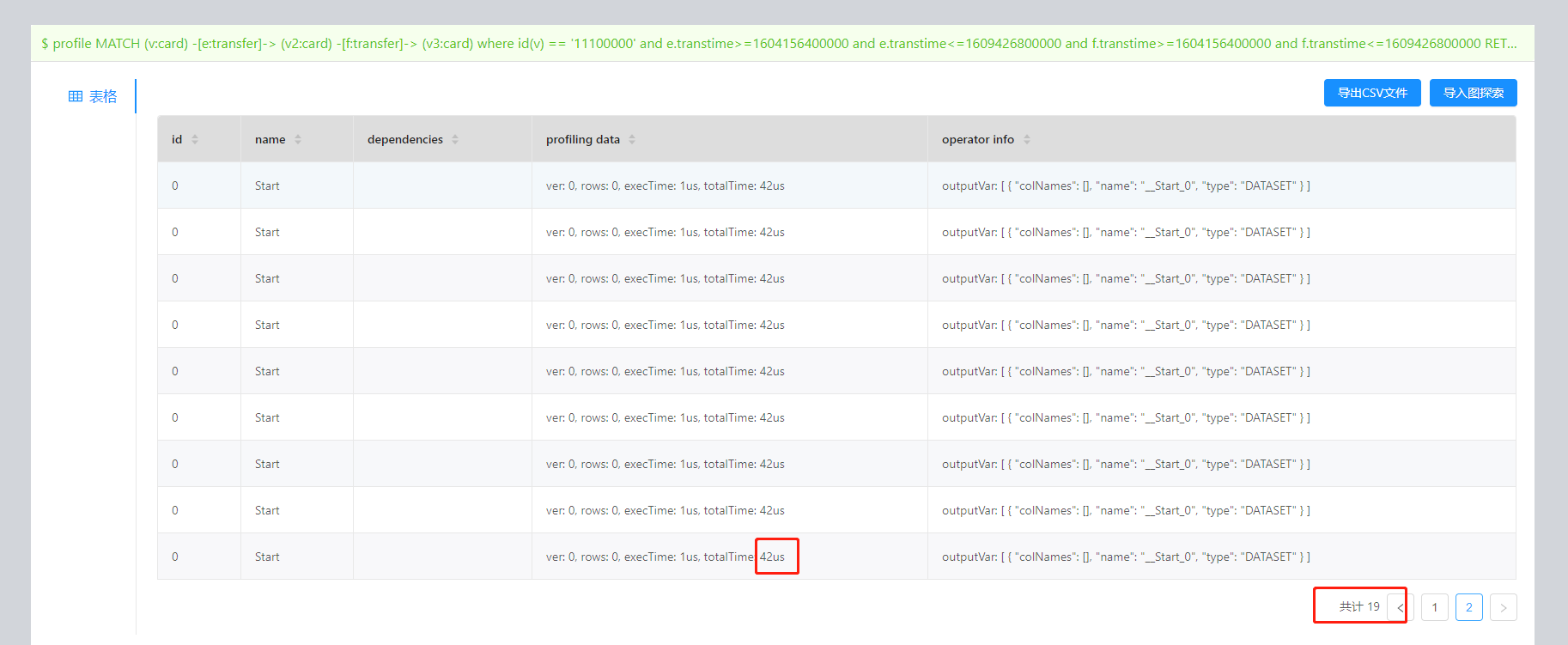
match方式
profile MATCH (v:card) -[e:transfer]-> (v2:card) -[f:transfer]-> (v3:card) where id(v) == '11100000' and e.transtime>=1604156400000 and e.transtime<=1609426800000 and f.transtime>=1604156400000 and f.transtime<=1609426800000 RETURN id(v), sum(f.amount);
go方式
profile go from '10000000' over transfer REVERSELY where transfer.transtime>=1606752000000 and transfer.transtime<=1609430399000
YIELD transfer._dst AS card |
GO FROM $-.card over transfer REVERSELY where transfer.transtime>=1604160000000 and transfer.transtime<=1609430399000 YIELD transfer.amount as amount | return sum($-.amount)
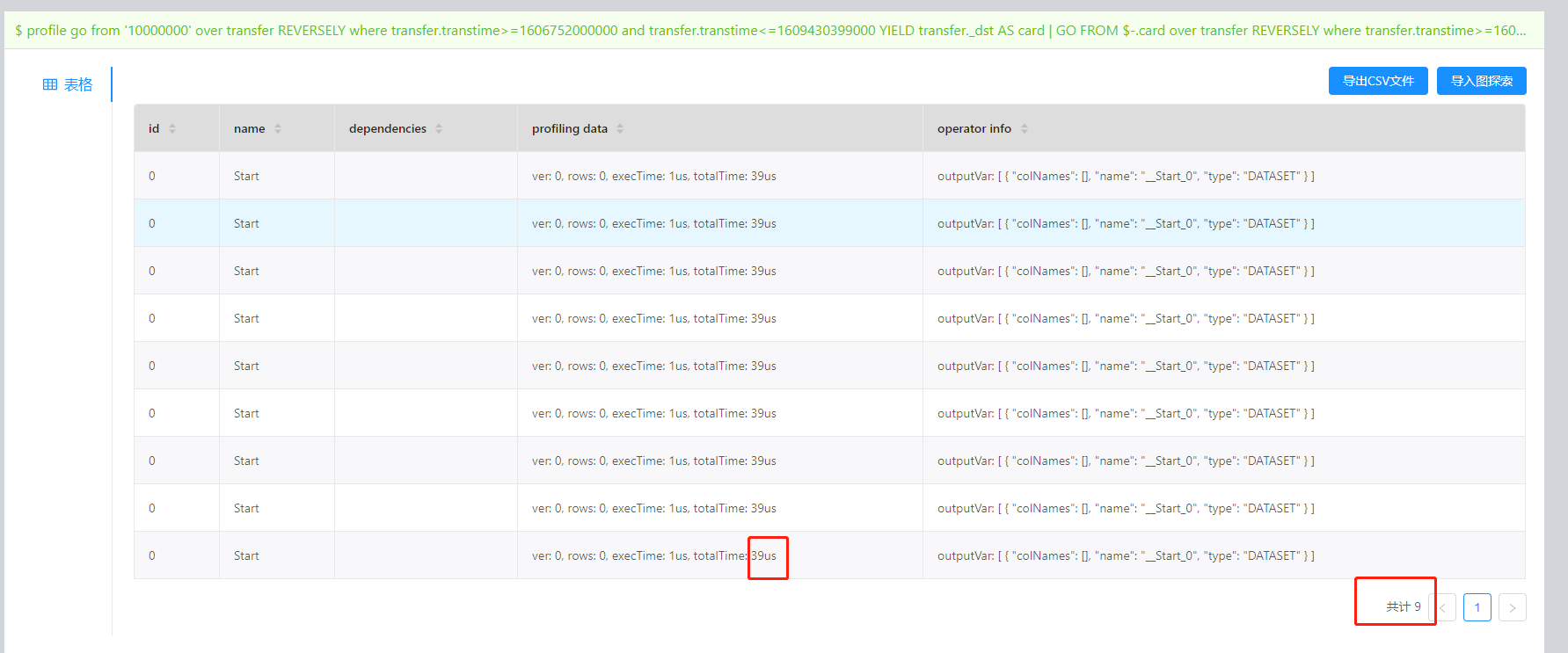
从执行计划上可以很清楚看到go的方式比match快了一倍
2.go语句怎么实现聚合判断过滤再进行下一次扩散
match写法
profile match l=(v:email)-[:email_idcard]->(ids1:idcard)<-[:phone_idcard]-(phone:phone)-[:phone_idcard]->(ids2:idcard) where id(v)=="email|2_test@zju.edu.cn"
with v, count(distinct phone) as pnum,count(distinct ids1) as ids1,count(distinct ids2) as ids2
where pnum > 0 and ids1>5 and ids1 < 200 and ids2 > 5 and ids2 < 300
return v.email_id, pnum,ids1,ids2, true as result
执行计划如下
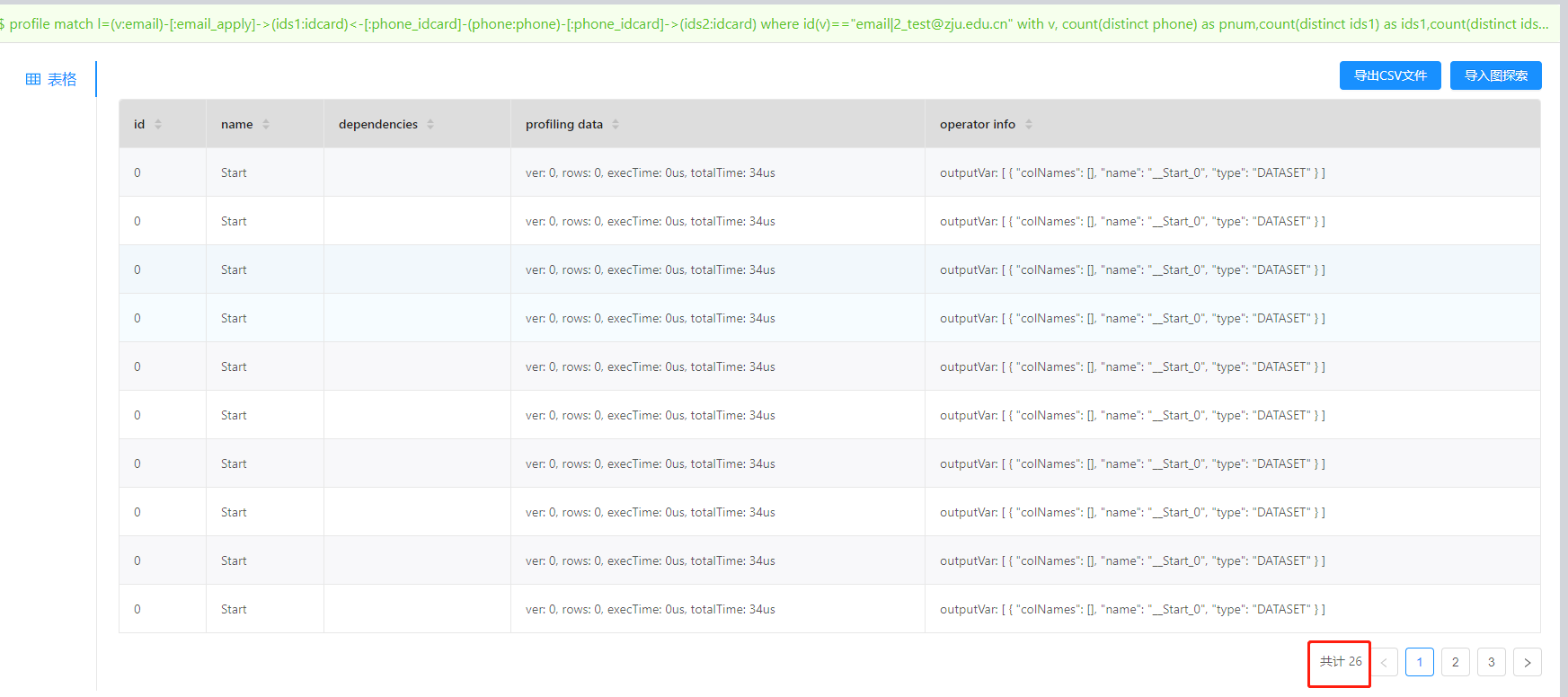
这个语句较为复杂,四度关联加聚合判断。
鉴于上边的问题,想把这个语句改为go的方式,发现count之后可以判断,但是无法得到下一次扩散的起始点了,如果再次扩散就无法得到聚合结果进行判断。不知道该怎么实现。
比如
go from "xxx" over email_idcard yield email_idcard._dst as id1 | go from $-.id1 over phone_idcard
这样可以扩散,但是判断加不进去
go from "xxx" over email_idcard yield size(collect(email_idcard._dst as id1) )
这样可以聚合但是无法下一步使用id1扩散了
官方例子较为简单,是否有更复杂的一些示例呢。
3.目前还是存在一些操作会引起graphd崩溃
YIELD case COUNT($-.var_idcards) ==100 when true THEN 1 ELSE 0 END as aa
case 后边跟聚合函数,graphd直接挂掉,我在之前发的帖子里边也有提到别的情况。
在生产环境由于一个查询就挂掉这太不安全了。。。
以上

