Nebula-importer可以将CSV形式的数据依照yaml配置文件进行导入,我们想具体了解Nebula-importer将CSV数据组织成什么形式(哪一个数据结构),以及该数据形式是何时被组织为key-value形式通过哪一个函数导入数据库的?
1 个赞
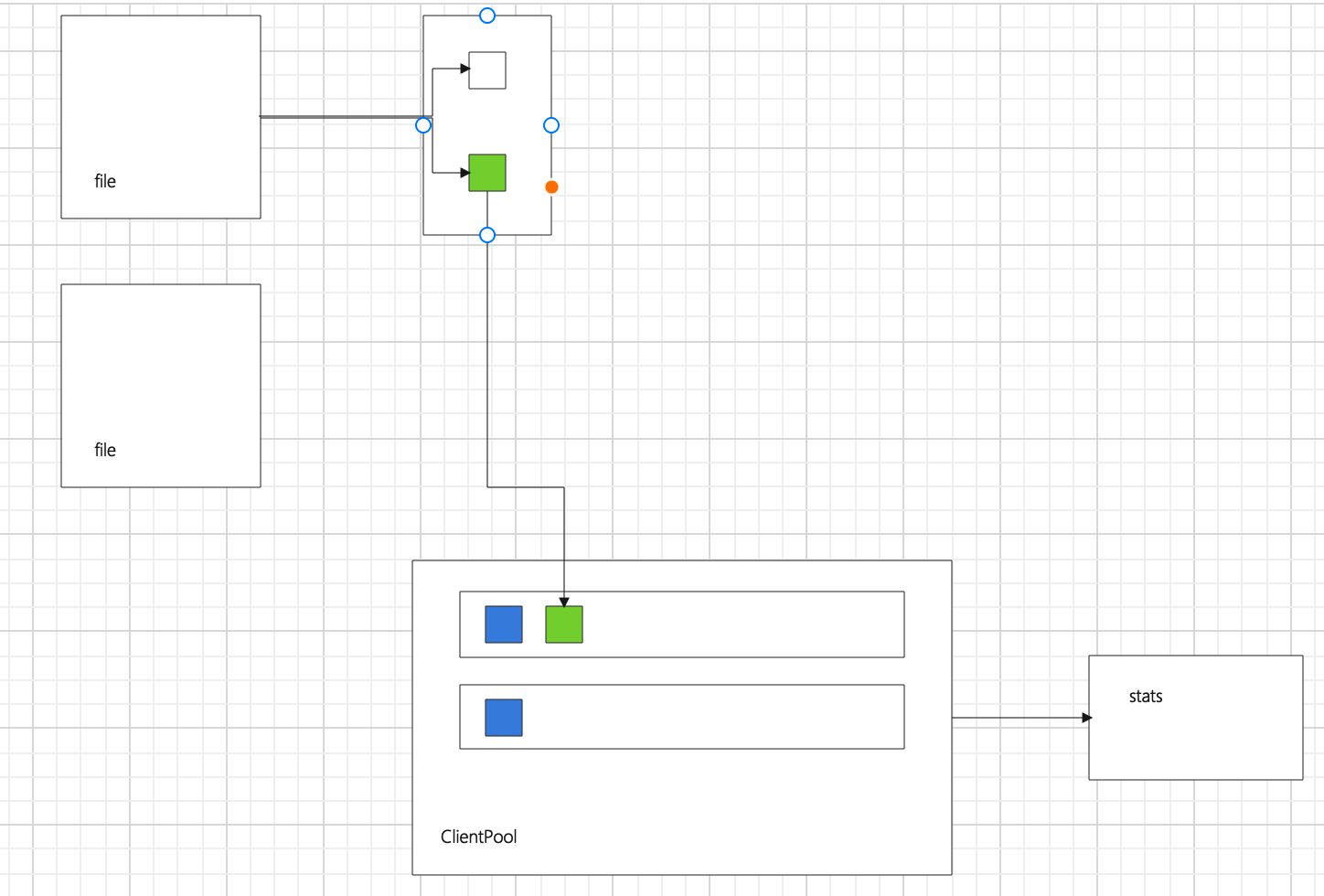
因为不确定你具体要问什么问题,画了个简单的示意图。
CSV 文件中的数据,每一行按 id 取模,放到不同的 batch 中,一旦这个 batch 达到配置中文件的 batchSize或者文件读完了,格式化 nGQL 语句,然后把语句(绿色方块)放到对应 client 的 chan 里,然后 client 发请求到 graph。
- 数据结构的话,就是 base.Data
- 不明白 key-value 形式是什么意思。格式化成 nGQL 是 FormatValues
1 个赞

这个是 storage 的存储数据格式,不直接暴露的。
nebula-importer 是通过 nebula-graph 导入,nebula-graph 调用 storage 接口。
好的,感谢您的解答。
另外还有两个问题:
1.nebula-graph层的作用是否是“将图相关的API请求翻译成一组针对相应Partition的kv操作”?
2.由nebula-importer导入的图在被存储到kv底层之前是被暂存在哪里呢?
graphD层 把 graph engine API 请求 变成 storageD 层 的 API,在 storageD 的服务端才是 KV 操作。
您可以从官方博客里的 架构设计 这个标签的文章里看到更多细节介绍哈。
importer 是一个 go app,把 csv 中的信息按照定义的规则翻译成 nGQL 的语句,按照 batchsize 用 graph client 访问 graphD 。
nebula-importer将csv中的数据拼成一系列insert语句,然后连接到query engine, 将数据插进去.
比如, csv中的数据是:
101, “a”, 18
102, “b”, 19
importer会拼出来这样一条语句:
insert vertex player(name, age) 101:(“a”, 18), 102:("b), 19)
插入到数据库中
4 个赞
好的 感谢