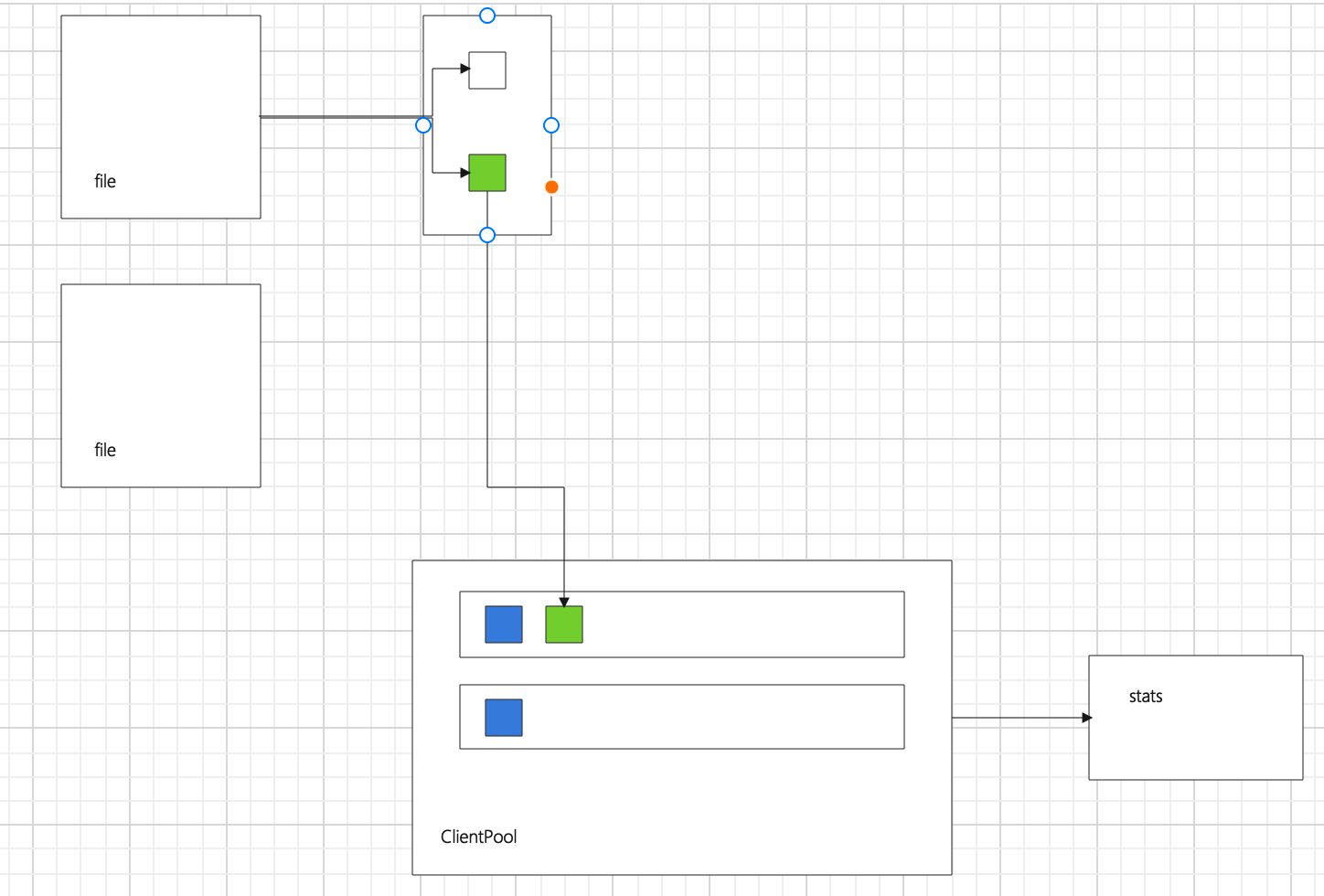
因为不确定你具体要问什么问题,画了个简单的示意图。
CSV 文件中的数据,每一行按 id 取模,放到不同的 batch 中,一旦这个 batch 达到配置中文件的 batchSize或者文件读完了,格式化 nGQL 语句,然后把语句(绿色方块)放到对应 client 的 chan 里,然后 client 发请求到 graph。
- 数据结构的话,就是 base.Data
- 不明白 key-value 形式是什么意思。格式化成 nGQL 是 FormatValues
因为不确定你具体要问什么问题,画了个简单的示意图。
CSV 文件中的数据,每一行按 id 取模,放到不同的 batch 中,一旦这个 batch 达到配置中文件的 batchSize或者文件读完了,格式化 nGQL 语句,然后把语句(绿色方块)放到对应 client 的 chan 里,然后 client 发请求到 graph。