从我个人判断是从flink到nebula的问题,比如开了过多连接。还是先看句柄吧,看看到底问题在哪



这也是fd不够啊 看句柄吧





docker小白  这感觉就和之前帖子有点类似了
这感觉就和之前帖子有点类似了
lsof -p pid 可以看看到底是开了些啥
你好, 你这个命令一炮的话, 全是wal文件, 你看我上一层的补的, 基本已经可以确定了
你把wal_ttl改小点 下面7700那几个进程呢 那些也占了十几万
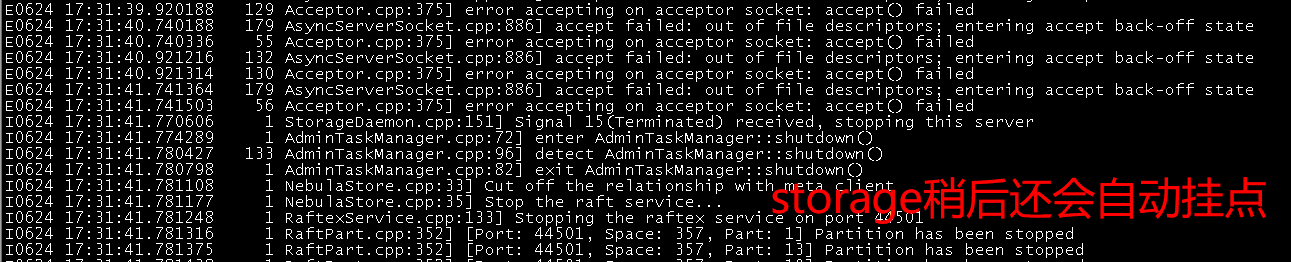
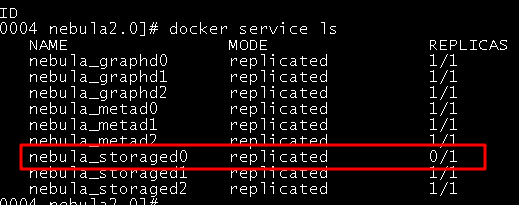
总结一下刚刚的导入, 开始导入后第一时间机器4开始报错, 然后过了1/2分钟我就把导入停了, 然后给你截图了4, 5, 6 机器的所有句柄最大的几个, 基本都是storage占了快100W了
机器4第一时间报的错

你好, 我应该为啥一开始导入就报错了, 因为机器现在重启后啥也没开始干, 3台机器的storage占得句柄已经快100W了, 到现在这个结果我不确定是不是用Flink导入造成的, 但是可以确定的是和打开*.wal文件没关系了, 并且重启不能释放这个.sst句柄
meta, graph都是10几万

storage打开的句柄中百分之99是.sst文件
我吧 lsof -p结果放在ym.ym中了
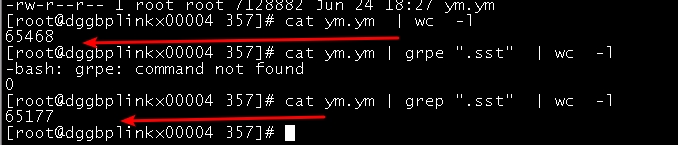

- 重启不能释放这个.sst句柄咋看出来的
- graph的句柄都是啥?
1 因为上面的结果就是我刚刚重新启动nebula后没有啥也没干的情况下在三台机器上查的句柄大小,可以看到最大的快100W的都是storage 进程
- 这个我明天再看一下meta和graph具体占的句柄是啥
得做下compaction了 rocksdb现在数据量多大 有多少个sst
三台机器,这个357 space下每个机器700多G 三个就2T左右,那行,今晚先做下compact
1 昨晚20点多开始做compact, 但是在凌晨0:30 失败了, 还是Too many open files… 三台storage节点失败重启了, 刚刚我又查了下机器上的打开句柄排序, 还是快1000W了(昨天还说是快100W)

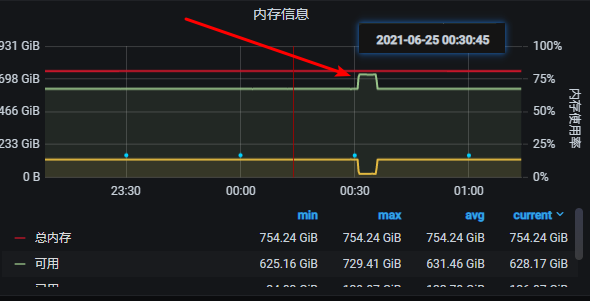

2
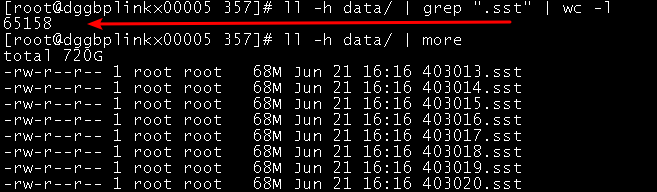
rocksdb的几个参数需要改下 现在单个sst太小了 64M 导致文件比较多
write_buffer_size
max_bytes_for_level_base
另外你可以试下把rocksdb的max_open_files改下,比如改到100w,不过文档上说-1是无限的。
68m的还是大的, 后面还有很多几兆的, 那我改写参数, 再启动下
这样可以吗? (不用管单位, )
rocksdb_column_family_options="{“write_buffer_size”:“256mb”,“max_write_buffer_number”:“4”,“max_bytes_for_level_base”:“512m”}"
rocksdb_db_options="{“max_open_files”:"-1"}"
max_bytes_for_level_base改到1G
max_open_files默认就是-1,怀疑没起作用
那我就改1亿吧
// Number of open files that can be used by the DB. You may need to
// increase this if your database has a large working set. Value -1 means
// files opened are always kept open. You can estimate number of files based
// on target_file_size_base and target_file_size_multiplier for level-based
// compaction. For universal-style compaction, you can usually set it to -1.
//
// Default: -1
//
// Dynamically changeable through SetDBOptions() API.
int max_open_files = -1;
1E太大了,不过你sst也只有几万个,rocksdb为啥会开这么多句柄。