您这个是 studio ?我说怎么在服务端代码里找不到这个报错 
console 能重现错误么?
您这个是 studio ?我说怎么在服务端代码里找不到这个报错
console 能重现错误么?
console里怎么复现啊, 有没有手册我去试试 
找到手册了,我先研究一下…
可能是数据量大了,studio 数据传输有点问题了,console的话可以参考手册,只要是能连到 graphd 的地方就可以运行。
@jerry.liang 这个network error 是不是数据量大的时候会出的问题,有什么能绕过的窍门么?
console的参考手册 连接Nebula Graph - Nebula Graph Database 手册
出现了新的错误
用console明显跑的时间比studio长了很多,没有studio里面network error的错误
这次是[ERROR (-8)]: Storage Error: The leader has changed. Try again later
storage没有crash
graphd.ERROR的日志
I0702 19:57:00.853134 66602 SwitchSpaceExecutor.cpp:43] Graph switched to `mobile_imei_all', space id: 60
I0702 20:05:06.939954 66446 StorageClientBase.inl:147] Update the leader for [60, 6] to "10.142.158.75":9779
I0702 20:08:23.539999 66447 StorageClientBase.inl:147] Update the leader for [60, 17] to "10.142.158.76":9779
E0702 20:08:23.540454 66603 StorageAccessExecutor.h:35] IndexScanExecutor failed, error E_LEADER_CHANGED, part 17
E0702 20:08:23.540549 66603 StorageAccessExecutor.h:35] IndexScanExecutor failed, error E_LEADER_CHANGED, part 6
E0702 20:08:23.553347 66602 QueryInstance.cpp:103] Storage Error: The leader has changed. Try again later
I0702 20:08:25.569489 66464 StorageClientBase.inl:147] Update the leader for [60, 6] to "10.142.158.75":9779
I0702 20:16:20.541244 66463 StorageClientBase.inl:147] Update the leader for [60, 14] to "10.142.158.77":9779
I0702 20:16:20.541317 66463 StorageClientBase.inl:147] Update the leader for [60, 17] to "10.142.158.76":9779
E0702 20:16:43.967430 66603 StorageAccessExecutor.h:35] GetVerticesExecutor failed, error E_LEADER_CHANGED, part 17
E0702 20:16:43.967499 66603 StorageAccessExecutor.h:35] GetVerticesExecutor failed, error E_LEADER_CHANGED, part 6
E0702 20:16:43.967511 66603 StorageAccessExecutor.h:35] GetVerticesExecutor failed, error E_LEADER_CHANGED, part 14
E0702 20:16:43.967749 66602 QueryInstance.cpp:103] Storage Error: The leader has changed. Try again later
host的选择会有很大影响吗,尝试了一下78作为host,重新执行一次,跑了50多分钟才报错
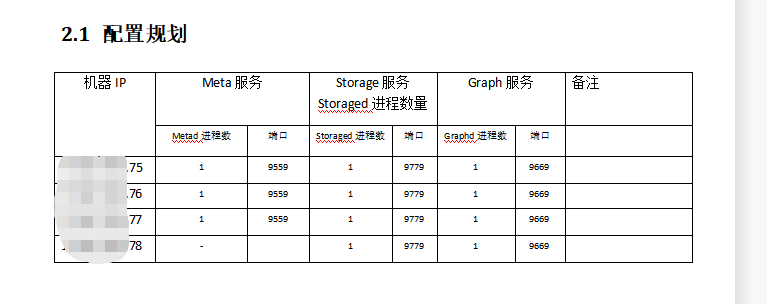
这个是我的部署情况
这个是日志
I0702 21:01:01.425348 3747 MetaClient.cpp:3053] Load leader of "10.142.158.75":9779 in 5 space
I0702 21:01:01.425400 3747 MetaClient.cpp:3053] Load leader of "10.142.158.76":9779 in 5 space
I0702 21:01:01.425431 3747 MetaClient.cpp:3053] Load leader of "10.142.158.77":9779 in 5 space
I0702 21:01:01.425451 3747 MetaClient.cpp:3053] Load leader of "10.142.158.78":9779 in 5 space
I0702 21:01:01.425457 3747 MetaClient.cpp:3056] Load leader ok
I0702 21:53:53.966553 3592 StorageClientBase.inl:147] Update the leader for [60, 20] to "10.142.158.76":9779
E0702 21:57:50.173939 3746 StorageAccessExecutor.h:35] GetVerticesExecutor failed, error E_LEADER_CHANGED, part 20
E0702 21:57:50.174208 3745 QueryInstance.cpp:103] Storage Error: The leader has changed. Try again later
发现问题了,这次是storage crash了
[root@A5-306-HW-2488HV5-2019-011 logs]# dmesg |grep nebula
[1922276.128930] nebula-storaged invoked oom-killer: gfp_mask=0x201da, order=0, oom_score_adj=0
[1922276.128936] nebula-storaged cpuset=/ mems_allowed=0-3
[1922276.128940] CPU: 28 PID: 89277 Comm: nebula-storaged Kdump: loaded Tainted: P OE ------------ 3.10.0-1127.el7.x86_64 #1
[1922276.129758] [101619] 0 101619 205172 2678 25 8 0 nebula-importer
[1922276.129777] [88273] 0 88273 161795 59560 229 6174 0 nebula-metad
[1922276.129779] [88283] 0 88283 153616529 115912318 258347 43013 0 nebula-graphd
[1922276.129781] [88293] 0 88293 29178434 10089095 48529 16525 0 nebula-storaged
[1922276.129789] Out of memory: Kill process 88283 (nebula-graphd) score 852 or sacrifice child
[1922276.129836] Killed process 88283 (nebula-graphd), UID 0, total-vm:614466116kB, anon-rss:463649272kB, file-rss:0kB, shmem-rss:0kB
full-scan 的 OLAP query 情况下,可能 graphD 和 storageD 跑在不同的 host 的时候相当于两个的可用内存就会多一些。
针对内存的优化我们还在做, 包括 limit 的 storage 下推,还在抓紧做,那样的话,这样 query 里加上 limit 可以缓解。
另外,您的场景能用where限制一下query条件么?
问下这边也是导入数据后,查询出现Storage Error: The leader has changed. Try again later
这个问题怎么解决是手动banlance leader ,还是nebual 回自动平衡, Try again later 是要等多久
请勿一个问题多处分发浪费他人的回复精力,问题以 用spark 导入数据后,查询数据出现 Storage Error: The leader has changed. Try again later 的回复为主
可以用where限制,我限制一下数据量看看。 full-scan的时候,内存会占用的很厉害吗?有没有哪个参数是限制内存量的。 感觉执行的时候,机器的内存还没吃满就oom了
手动执行了balance leader。 是查询立刻就出现the leader has changed了吗? 这种情况差不多最多1,2个心跳周期。 我的情况是,query执行了可能1个小时,然后报这个错
fullscan 的话,目前在没有优化完的情况下是拿到所有的点数据返回给 query engine 的。
相比起来 lookup 没有把属性全都返回,会省一些内存,不过您的这个query似乎用 lookup 没法表达。
storage 读的内存可以调的主要是 block cache和bloom filter,rocksdb参考文档https://github.com/facebook/rocksdb/wiki/Memory-usage-in-RocksDB
参考帖子
nebula-storage 内存与性能的问题 - #2,来自 valseek
把–rocksdb_block_cache调成了all memory,出现了这个错误。 看3个日志都没记录。内存也的确几乎吃满了,这个也和内存是有关系的吗
2021/07/09 15:36:22 [ERROR] Failed to reconnect, Failed to open transport, error: dial tcp 10.142.158.78:9669: con
nect: connection refused
2021/07/09 15:36:22 Loop error, Failed to open transport, error: dial tcp 10.142.158.78:9669: connect: connection
refused
Bye root!
Fri, 09 Jul 2021 15:36:22 CST
panic: Loop error, Failed to open transport, error: dial tcp 10.142.158.78:9669: connect: connection refused
goroutine 1 [running]:
log.Panicf(0x646161, 0xe, 0xc00014de78, 0x1, 0x1)
/opt/hostedtoolcache/go/1.16.4/x64/src/log/log.go:361 +0xc5
main.main()
/home/runner/work/nebula-console/nebula-console/main.go:419 +0x4f3
该话题在最后一个回复创建后30天后自动关闭。不再允许新的回复。