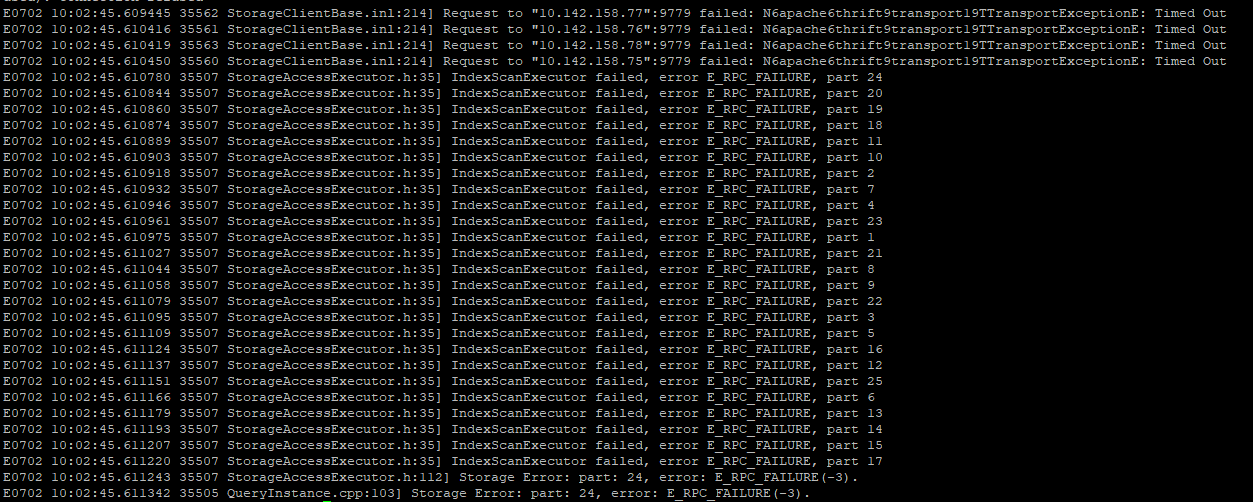
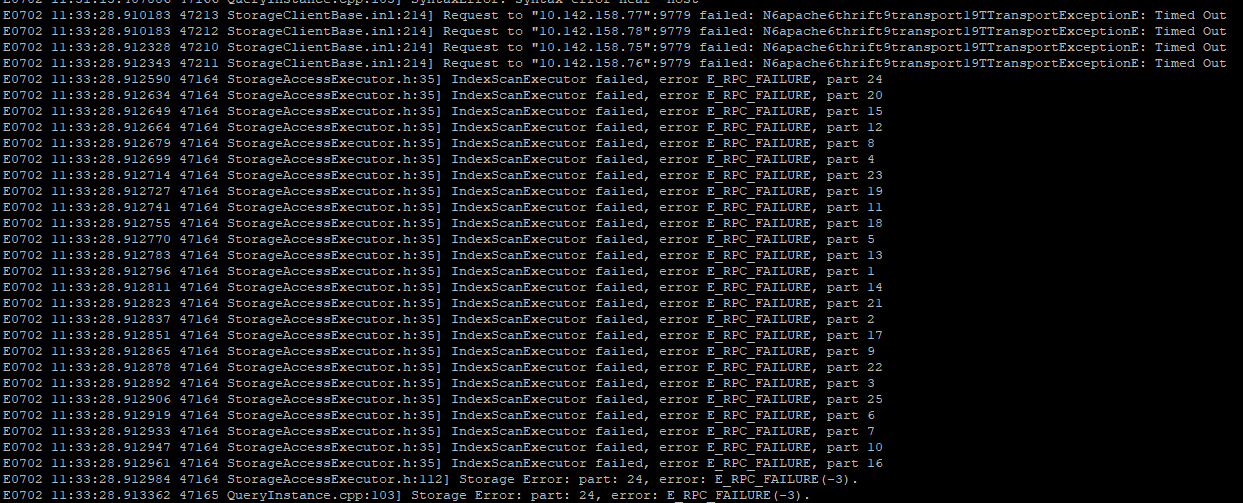
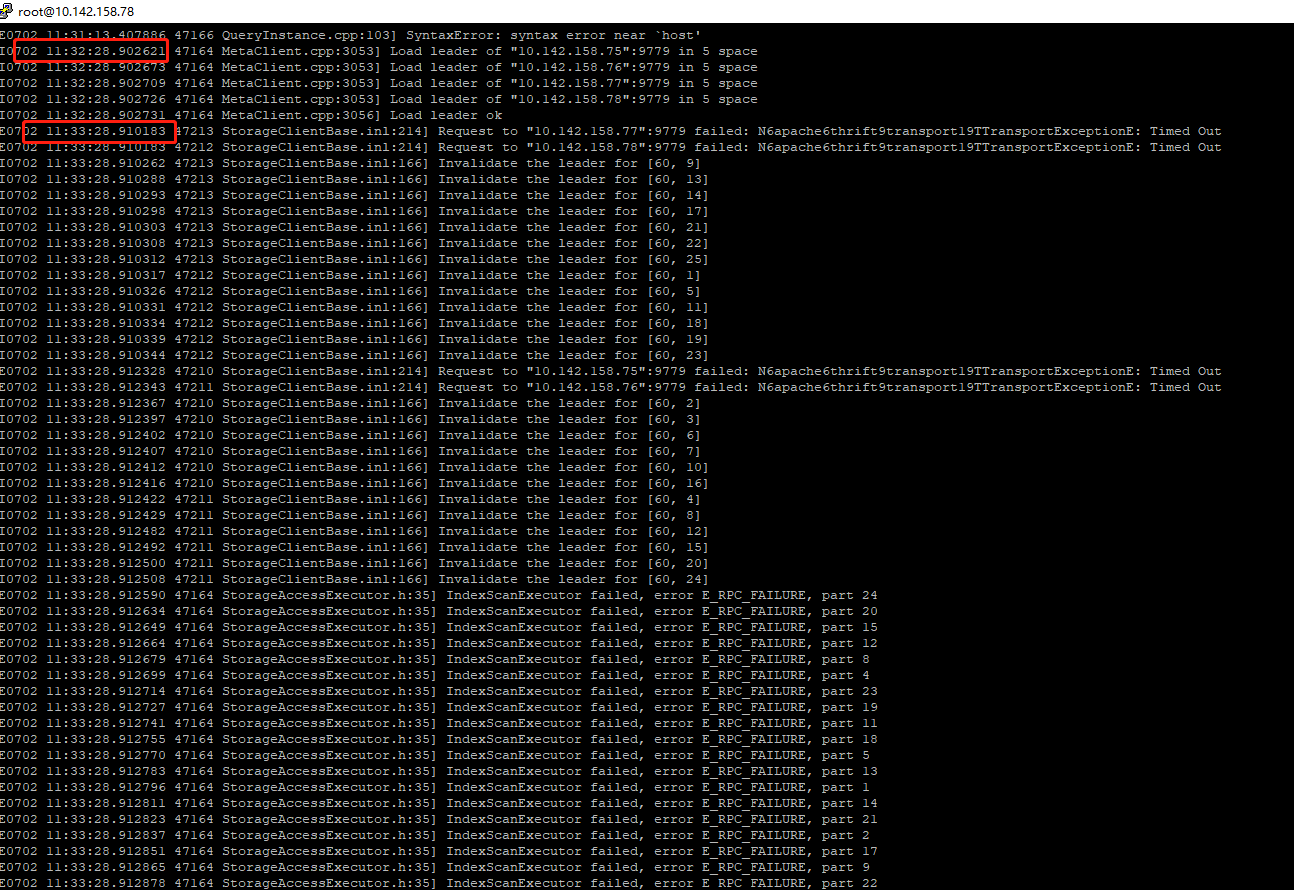
这是storaged.INFO的部分日志,重启之后先balance leader,查询差不多14:25分左右执行的
I0702 14:23:45.162096 69540 Host.cpp:149] [Port: 9780, Space: 60, Part: 10] [Host: 10.142.158.75:9780] This is the first time to send the logs to this host, lastLogIdSent = 15907614, lastLogTermSent = 31
I0702 14:23:45.162003 69587 RaftPart.cpp:1248] [Port: 9780, Space: 60, Part: 6] The partition is elected as the leader
I0702 14:23:45.162073 69581 RaftPart.cpp:1152] [Port: 9780, Space: 60, Part: 17] Partition is elected as the new leader for term 49
I0702 14:23:45.162195 69541 Host.cpp:149] [Port: 9780, Space: 60, Part: 9] [Host: 10.142.158.76:9780] This is the first time to send the logs to this host, lastLogIdSent = 15838164, lastLogTermSent = 41
I0702 14:23:45.162263 69581 RaftPart.cpp:1248] [Port: 9780, Space: 60, Part: 17] The partition is elected as the leader
I0702 14:23:45.162279 69542 Host.cpp:149] [Port: 9780, Space: 60, Part: 6] [Host: 10.142.158.77:9780] This is the first time to send the logs to this host, lastLogIdSent = 15776524, lastLogTermSent = 44
I0702 14:23:45.162279 69587 Part.cpp:191] [Port: 9780, Space: 60, Part: 1] Find the new leader "10.142.158.76":9780
I0702 14:23:45.162333 69561 Host.cpp:149] [Port: 9780, Space: 60, Part: 17] [Host: 10.142.158.76:9780] This is the first time to send the logs to this host, lastLogIdSent = 15707326, lastLogTermSent = 48
I0702 14:23:45.162320 69541 Host.cpp:149] [Port: 9780, Space: 60, Part: 9] [Host: 10.142.158.77:9780] This is the first time to send the logs to this host, lastLogIdSent = 15838164, lastLogTermSent = 41
I0702 14:23:45.162345 69482 RaftPart.cpp:422] [Port: 9780, Space: 32, Part: 2] Commit transfer leader to "10.142.158.78":9780
I0702 14:23:45.162400 69482 RaftPart.cpp:436] [Port: 9780, Space: 32, Part: 2] I am already the leader!
I0702 14:23:45.162351 69542 Host.cpp:149] [Port: 9780, Space: 60, Part: 6] [Host: 10.142.158.75:9780] This is the first time to send the logs to this host, lastLogIdSent = 15776524, lastLogTermSent = 44
I0702 14:23:45.162423 69561 Host.cpp:149] [Port: 9780, Space: 60, Part: 17] [Host: 10.142.158.77:9780] This is the first time to send the logs to this host, lastLogIdSent = 15707326, lastLogTermSent = 48
I0702 14:23:45.162468 69482 RaftPart.cpp:422] [Port: 9780, Space: 60, Part: 10] Commit transfer leader to "10.142.158.78":9780
I0702 14:23:45.162483 69482 RaftPart.cpp:436] [Port: 9780, Space: 60, Part: 10] I am already the leader!
I0702 14:23:45.162629 69482 RaftPart.cpp:422] [Port: 9780, Space: 60, Part: 17] Commit transfer leader to "10.142.158.78":9780
I0702 14:23:45.162639 69482 RaftPart.cpp:436] [Port: 9780, Space: 60, Part: 17] I am already the leader!
I0702 14:23:45.162648 69483 RaftPart.cpp:422] [Port: 9780, Space: 60, Part: 9] Commit transfer leader to "10.142.158.78":9780
I0702 14:23:45.162667 69483 RaftPart.cpp:436] [Port: 9780, Space: 60, Part: 9] I am already the leader!
I0702 14:23:45.162659 69481 RaftPart.cpp:422] [Port: 9780, Space: 60, Part: 6] Commit transfer leader to "10.142.158.78":9780
I0702 14:23:45.162694 69481 RaftPart.cpp:436] [Port: 9780, Space: 60, Part: 6] I am already the leader!
I0702 14:23:58.640892 69481 RaftPart.cpp:422] [Port: 9780, Space: 32, Part: 1] Commit transfer leader to "10.142.158.76":9780
I0702 14:23:58.640935 69481 RaftPart.cpp:442] [Port: 9780, Space: 32, Part: 1] I am Follower, just wait for the new leader!
I0702 14:23:58.955364 69481 RaftPart.cpp:422] [Port: 9780, Space: 60, Part: 1] Commit transfer leader to "10.142.158.76":9780
I0702 14:23:58.955391 69481 RaftPart.cpp:442] [Port: 9780, Space: 60, Part: 1] I am Follower, just wait for the new leader!
I0702 14:23:59.421893 69481 RaftPart.cpp:422] [Port: 9780, Space: 32, Part: 3] Commit transfer leader to "10.142.158.76":9780
I0702 14:23:59.421919 69481 RaftPart.cpp:442] [Port: 9780, Space: 32, Part: 3] I am Follower, just wait for the new leader!
I0702 14:33:06.375084 69585 FileBasedWal.cpp:738] [Port: 9780, Space: 60, Part: 15] Clean wals number 1
I0702 14:33:06.381273 69585 FileBasedWal.cpp:738] [Port: 9780, Space: 60, Part: 7] Clean wals number 1
I0702 14:33:06.386870 69585 FileBasedWal.cpp:738] [Port: 9780, Space: 60, Part: 2] Clean wals number 1
I0702 14:33:06.389310 69585 FileBasedWal.cpp:738] [Port: 9780, Space: 60, Part: 3] Clean wals number 1
I0702 14:33:06.395366 69585 FileBasedWal.cpp:738] [Port: 9780, Space: 60, Part: 10] Clean wals number 1
I0702 14:33:06.399804 69585 FileBasedWal.cpp:738] [Port: 9780, Space: 60, Part: 17] Clean wals number 1