如果发生了leader切换,那需要通过心跳机制来更新,不是即时更新的
那不是应该有可以找到map里的key吗,不应该找不到啊,不更新也是找到的不对吧
没有找不到,找到了,但是不是leader,所以请求返回失败
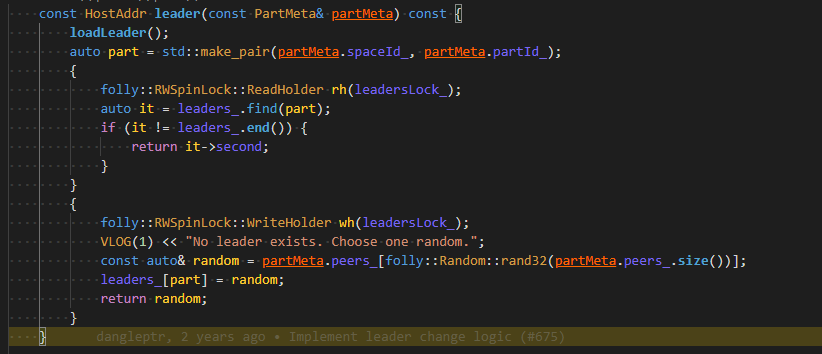
代码里的逻辑不是找到了就返回,找不到就随机选一个打印日志么
是的
这样不就是存在找不到leader吗 不是leader不对啊。
不是随机找了一个么
是随机找了一个,但是不应该出现随机找的情况。因为在map里每个partition都有leader才对,map的leader信息可能不是最新的,但是不应该没有leader吧
还有为什么会存在leader缺失的情况,storage都会同步leader信息给meta,storageclient从meta同步后根据每次的查询、插入去更新leader信息。出现随机找的情况,就是少了partition信息
如果发生了leader切换,那需要通过心跳机制来更新,不是即时更新的
没有即时更新的话,不是缓存旧的leader吗,有旧的leader信息,不就不需要随机找leader吗
旧的已经不是leader了
旧的不是leader了,所以要在所有的节点里重新找一个,找到leader,或者请求返回新的leader
这里的逻辑不是判断是不是最新的leader吧,前后逻辑是leaders信息不存在吧,这个代码的调用是在进行增删改查之前的
没找到就是leader已经失效了
失效了,meta就不会缓存这个partition的leader信息吗?storage心跳同步逾期会导致整个情况?
例如meta本来缓存的leader信息为
{(partition1,leader1),(partition2,leader2),(partition3,leader3)}
假设leader1所在的storage节点负载高,心跳同步逾期,meta就会把partition1的记录失效?
我的集群没有发生leader切换,只是leader所在节点 IO很忙
现在逻辑应该是请求leader异常会认为leader失效,leader节点很忙导致请求异常也是
storage client的leader信息不是从meta获取的么?