V2.0.1 三节点,进行大量的插入操作时,graph日志提示No leader exists. Choose one in round-robin,客户端提示insert not complete。
1.1.0也在存在这个问题,请问为什么会找不到leader。插入时,graphd不是从meta那获取到的吗,看代码里,如果leader不存在就会随机选取一个,这样的话就会导致leader对。插入失败。
V2.0.1 三节点,进行大量的插入操作时,graph日志提示No leader exists. Choose one in round-robin,客户端提示insert not complete。
1.1.0也在存在这个问题,请问为什么会找不到leader。插入时,graphd不是从meta那获取到的吗,看代码里,如果leader不存在就会随机选取一个,这样的话就会导致leader对。插入失败。
你show host看一下
然后贴一下一下storage的log
show host 是正常的
17:55:04.123340 15878 EventListner.h:33] Rocksdb compact column family: default because of 1, status: OK, compacted 9 files into 5, base level is 0, output level is 1
17:55:04.721297 15849 InMemoryLogBuffer.h:27] [Port: 44501, Space: 57, Part: 1] InMemoryLogBuffer dtor, firstLogId 6902270
17:55:04.724191 15849 InMemoryLogBuffer.h:23] [Port: 44501, Space: 57, Part: 1] InMemoryLogBuffer ctor, firstLogId 6904045
17:55:05.936748 15845 InMemoryLogBuffer.h:27] [Port: 44501, Space: 57, Part: 3] InMemoryLogBuffer dtor, firstLogId 7082969
17:55:05.937855 15845 InMemoryLogBuffer.h:23] [Port: 44501, Space: 57, Part: 3] InMemoryLogBuffer ctor, firstLogId 7085425
17:55:06.060595 15849 InMemoryLogBuffer.h:27] [Port: 44501, Space: 57, Part: 2] InMemoryLogBuffer dtor, firstLogId 6894958
17:55:06.061110 15849 InMemoryLogBuffer.h:23] [Port: 44501, Space: 57, Part: 2] InMemoryLogBuffer ctor, firstLogId 6897515
17:55:06.265144 15848 InMemoryLogBuffer.h:27] [Port: 44501, Space: 57, Part: 1] InMemoryLogBuffer dtor, firstLogId 6903406
17:55:06.265388 15848 InMemoryLogBuffer.h:23] [Port: 44501, Space: 57, Part: 1] InMemoryLogBuffer ctor, firstLogId 6905196
17:55:06.711104 15864 Host.cpp:128] [Port: 44501, Space: 57, Part: 1] [Host: ] Too many requests are waiting, return error
17:55:06.912341 15855 Host.cpp:128] [Port: 44501, Space: 57, Part: 1] [Host: ] Too many requests are waiting, return error
17:55:07.026214 15862 Host.cpp:128] [Port: 44501, Space: 57, Part: 3] [Host: ] Too many requests are waiting, return error
17:55:07.155297 15859 Host.cpp:128] [Port: 44501, Space: 57, Part: 3] [Host: ] Too many requests are waiting, return error
17:55:07.277958 15857 Host.cpp:128] [Port: 44501, Space: 57, Part: 3] [Host: ] Too many requests are waiting, return error
17:55:07.317582 15844 InMemoryLogBuffer.h:27] [Port: 44501, Space: 57, Part: 3] InMemoryLogBuffer dtor, firstLogId 7084193
17:55:07.317865 15844 InMemoryLogBuffer.h:23] [Port: 44501, Space: 57, Part: 3] InMemoryLogBuffer ctor, firstLogId 7086518
17:55:07.389986 15873 Host.cpp:128] [Port: 44501, Space: 57, Part: 1] [Host: ] Too many requests are waiting, return error
17:55:07.583918 15849 InMemoryLogBuffer.h:27] [Port: 44501, Space: 57, Part: 2] InMemoryLogBuffer dtor, firstLogId 6896203
17:55:07.587036 15849 InMemoryLogBuffer.h:23] [Port: 44501, Space: 57, Part: 2] InMemoryLogBuffer ctor, firstLogId 6898731
17:55:07.791316 15842 InMemoryLogBuffer.h:27] [Port: 44501, Space: 57, Part: 1] InMemoryLogBuffer dtor, firstLogId 6904045
17:55:07.792845 15842 InMemoryLogBuffer.h:23] [Port: 44501, Space: 57, Part: 1] InMemoryLogBuffer ctor, firstLogId 6906417
17:55:08.748446 15845 InMemoryLogBuffer.h:27] [Port: 44501, Space: 57, Part: 3] InMemoryLogBuffer dtor, firstLogId 7085425
17:55:08.748971 15845 InMemoryLogBuffer.h:23] [Port: 44501, Space: 57, Part: 3] InMemoryLogBuffer ctor, firstLogId 7087714
17:55:09.043505 15842 InMemoryLogBuffer.h:27] [Port: 44501, Space: 57, Part: 2] InMemoryLogBuffer dtor, firstLogId 6897515
17:55:09.046562 15842 InMemoryLogBuffer.h:23] [Port: 44501, Space: 57, Part: 2] InMemoryLogBuffer ctor, firstLogId 6899923
17:55:09.239384 15843 InMemoryLogBuffer.h:27] [Port: 44501, Space: 57, Part: 1] InMemoryLogBuffer dtor, firstLogId 6905196
17:55:09.239943 15843 InMemoryLogBuffer.h:23] [Port: 44501, Space: 57, Part: 1] InMemoryLogBuffer ctor, firstLogId 6907590
17:55:10.203438 15846 InMemoryLogBuffer.h:27] [Port: 44501, Space: 57, Part: 3] InMemoryLogBuffer dtor, firstLogId 7086518
需要说明的是,show host所示,各个storage节点都在线,但是leader都在一个节点,且节点IO负载很高
那你需要balance leader一下,平衡一下负载
那请问为什么storage的都没提示leader 选举 但是graph却获取不了leader信息呢
leader是需要发心跳保持leadership的,负载太高可能心跳超时了
我设置的心跳都是五分钟同步一次,心跳不会超时才对。第二个meta肯定会有一个leader的吧,不会找不到的吧,只是插入的时候发现leader不对出错才对。一个vertexID hash出一个partition,这个partition会存在没有leader的情况?
你balance之后还有error么
看一下graph的log
I0814 20:11:51.529060 17792 RowWriter.cpp:241] Nothing to skip
I0814 20:11:51.529070 17792 RowWriter.cpp:241] Nothing to skip
I0814 20:11:51.529080 17792 RowWriter.cpp:241] Nothing to skip
I0814 20:11:51.529090 17792 RowWriter.cpp:241] Nothing to skip
I0814 20:11:51.529100 17792 RowWriter.cpp:241] Nothing to skip
I0814 20:11:51.529110 17792 RowWriter.cpp:241] Nothing to skip
I0814 20:11:51.529120 17792 RowWriter.cpp:241] Nothing to skip
I0814 20:11:51.529130 17792 RowWriter.cpp:241] Nothing to skip
I0814 20:11:51.529140 17792 RowWriter.cpp:241] Nothing to skip
I0814 20:11:51.529027 17798 StatsManager.cpp:88] The counter “xxxxxx” already exists
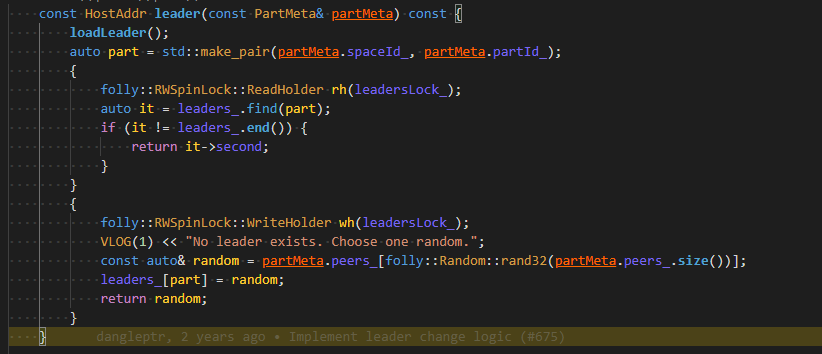
I0814 20:11:51.529158 17792 StorageClient.h:209] No leader exists. Choose one random.
I0814 20:11:51.529165 17798 ServerBasedSchemaManager.cpp:26] Get Tag Schema Space 57, TagID 60, Version -1
I0814 20:11:51.529170 17792 StorageClient.h:209] No leader exists. Choose one random.
I0814 20:11:51.529211 17798 RowWriter.cpp:241] Nothing to skip
I0814 20:11:51.529227 17792 StorageClient.cpp:57] requests size 3
I0814 20:11:51.529237 17798 RowWriter.cpp:241] Nothing to skip
I0814 20:11:51.529249 17798 RowWriter.cpp:241] Nothing to skip
I0814 20:11:51.529259 17798 RowWriter.cpp:241] Nothing to skip
I0814 20:11:51.529268 17319 ThriftClientManager.inl:21] Getting a client to x.x.x.x:44500
I0814 20:11:51.529270 17798 RowWriter.cpp:241] Nothing to skip
I0814 20:11:51.529307 17319 ThriftClientManager.inl:43] Connecting to x.x.x.x:44500 for 53 times
I0814 20:11:51.529314 17798 RowWriter.cpp:241] Nothing to skip
I0814 20:11:51.529342 17798 RowWriter.cpp:241] Nothing to skip
其中 x.x.x.x一直都是leader所在ip
你这个log不太对啊,是2.0.1?
1.1.0的,,,,, 2.0.1也有这个问题,但是2.0.1的日志删除了,只能贴一下1.1.0的日志
你把一个插入语句多试几次看一下结果
多试几次是可以成功的。但是如果批量插入就会有这种问题。不会一直失败,但是会有部分记录出现问题,我的疑问是为什么会出现这种找不到leader的问题。
假设搞并发的场景,导致storage负载很高,也有可能出现这种leader找不到的情况,找不到再随机找一个leader,这是不对的吧。
这个主要是storage client这里不知道谁是leader,所以需要重试来确定leader。重试直接暴露给用户确实不是一个好的行为,可以提个issue。
storage client的leader信息不是缓存在一个map里的吗,而这个map是从meta获取leader信息的,应该是会知道谁是leader的啊