提问参考模版:
- nebula 版本:2.0.1
- 部署方式(分布式 / 单机 / Docker / DBaaS):单机
- 是否为线上版本:N
- 硬件信息
- 磁盘( 推荐使用 SSD):SSD
- CPU、内存信息:略
- 问题的具体描述:见正文
- 相关的 meta / storage / graph info 日志信息:默认(未修改)
我的数据集合是这样的:
create tag class(name string);
create tag field(name string, type string);
create edge subclassOf();
create edge supperclassOf();
create edge fieldOf();
create edge hasField();
insert vertex class(name) values "A":("A"),"B":("B"),"C":("c");
insert vertex field(name, type) values "a1":("a1","string"),"a2":("a2","string"),"a3":("a3","string"),"b1":("b1","string"),"b2":("b2","string"),"c1":("c1","string"),"c2":("c2","string");
insert edge subclassOf() values "B"->"A":(),"C"->"B":();
insert edge supperclassOf() values "A"->"B":(),"B"->"C":();
insert edge fieldOf() values "a1"->"A":(),"a2"->"A":(),"a3"->"A":(),"b1"->"B":(),"b2"->"B":(),"c1"->"C":(),"c2"->"C":();
insert edge hasField() values "A"->"a1":(),"A"->"a2":(),"A"->"a3":(),"B"->"b1":(),"B"->"b2":(),"C"->"c1":(),"C"->"c2":();
可视化展示出来
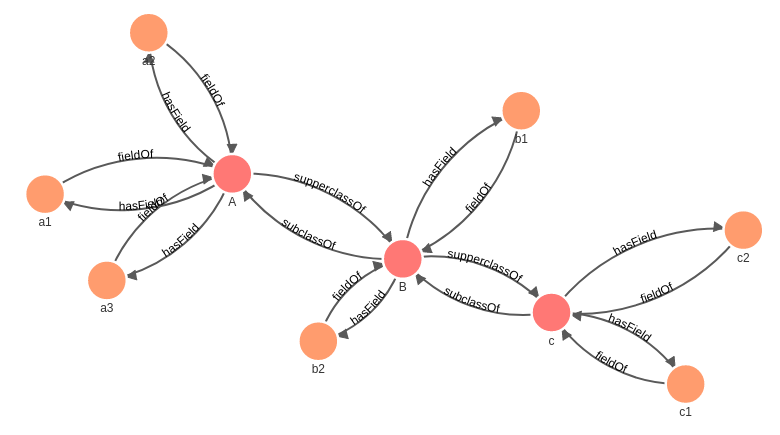
我现在想查询C,以及通过边subclassOf的0到n跳到达的所有其他节点.在这里的结果就是A,B,C.最终再通过hasField查询A,B,C的所有field.最终结果在这个数据集里是a1,a2,a3,b1,b2,c1,c2.
(1)查询C,以及通过边subclassOf的0到n跳到达的所有其他节点
MATCH p=(v)-[:subclassOf*..10]->(s) WHERE id(v) == 'C' UNWIND nodes(p) AS n RETURN n | WITH DISTINCT $-.n AS c RETURN c
(2)查询A,B,C的所有field
MATCH (c:class)-[:hasField]->(f:field) WHERE id(c) IN ["C", "B", "A"] RETURN f
我现在想把这两个查询整合到一起.
尝试1:
MATCH p=(v)-[:subclassOf*..10]->(s) WHERE id(v) == 'C' UNWIND nodes(p) AS n RETURN n | WITH DISTINCT $-.n AS c RETURN c | MATCH p=(c_)-[:hasField]->(f) WHERE id(c_) == id($-.c) RETURN f
这种ID匹配不行,那我在管道中传集合呢
尝试2:
MATCH p=(v)-[:subclassOf*..10]->(s) WHERE id(v) == 'C' UNWIND nodes(p) AS n RETURN n | WITH DISTINCT $-.n AS c RETURN c | WITH id($-.c) AS cid RETURN collect(cid) as cids | MATCH p=(c_)-[:hasField]->(f) WHERE id(c_) IN $-.cids RETURN f一样的问题.那我用go,直接写上ID,不是在where里面写.
尝试3:
MATCH p=(v)-[:subclassOf*..10]->(s) WHERE id(v) == 'C' UNWIND nodes(p) AS n RETURN n | WITH DISTINCT $-.n AS c RETURN c | WITH id($-.c) AS cid RETURN cid | GO FROM $-.cid OVER hasField;管道怎么没把值传过去.要不我通过接合的方式传过去试试.
尝试4:
MATCH p=(v)-[:subclassOf*..10]->(s) WHERE id(v) == 'C' UNWIND nodes(p) AS n RETURN n | WITH DISTINCT $-.n AS c RETURN c | WITH id($-.c) AS cid RETURN collect(cid) as cids | GO FROM $-.cids OVER hasField;几经尝试.
正式向大佬们求助了.
用什么查询语句都可以.只要能写成一句.
当然,这里我用UNION可以这样查出来:
尝试5:
GO FROM "C" OVER hasField YIELD DISTINCT $$.field.name AS f UNION MATCH p=(v)-[:subclassOf*..10]->(s)-[:hasField]->(f) WHERE id(v) == 'C' RETURN f.name AS f;

这里返回的是节点的
name字段.我想返回整个节点怎么处理.因为go的field里必须指定具体的属性.GO FROM "C" OVER hasField YIELD DISTINCT $$.field AS f;
当然
尝试6:
GO FROM "C" OVER hasField YIELD hasField._dst AS fid | FETCH PROP ON field $-.fid UNION MATCH p=(v)-[:subclassOf*..10]->(s)-[:hasField]->(f) WHERE id(v) == 'C' RETURN f AS vertices_;
虽然出来了.这里面有两个瑕疵
(1)表头只能用vertices_
(2)从GO管道到FETCH.这里不知道是不是性能最佳的.