提问参考模版:
- nebula 版本:2.0.1
- 部署方式(分布式 / 单机 / Docker / DBaaS):分布式
- 是否为线上版本:Y
- 硬件信息
- 磁盘( 推荐使用 SSD)
- CPU、内存信息 16核心,32G
- 问题的具体描述
目前使用了三台服务器部署的集群,配置文件只修改了server_ip和local_ip,三台服务器都启动了graphd,metad,storaged,目前插入所有点大概需要10分钟,删除所有点大概40分钟,删除的时候查看top进程发现只有一台机器的cpu单核利用率100%,storaged进程,另外2台无进程。这是什么原因呢,或者怎么进行调优呢
可以先show hosts, 查看一下是不是三台服务器的 graphd, metad, storaged 服务是否正常启动
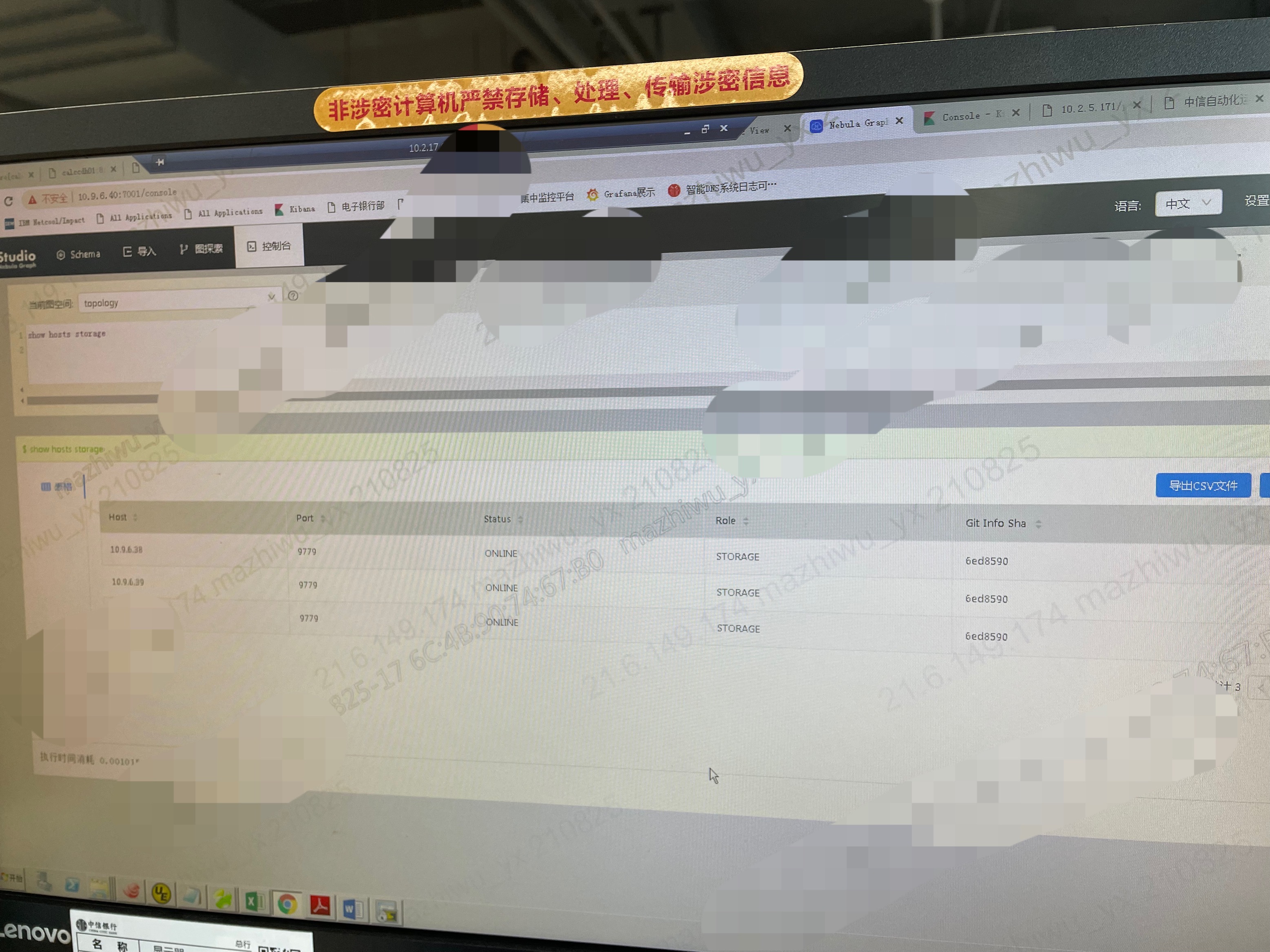
show hosts storage, 不是说有两个没有storage 没有进程吗?你看看是不是正常服务
删除过程中使用top去查看发现只有一台服务器的storaged进程单cpu利用率百分百,另外两台top没有发现该进程
ps -aux | grep nebula 试试看有这个进程吗?
都有的,三台服务器的graph进程都是正常的,和./nebula.service start all启动后的查询到的进程一致,现在就是想知道为什么插入或者删除的时候没有充分利用我的多核心资源,集群好像也并没有利用到,或者我应该修改什么参数
steam
8
你把 SHOW HOSTS STORAGE; 的结果贴一下
steam
10
嗯嗯,先看下是不是服务都起来了,你下周拿到返回结果了来更新下帖子
从这个图上看 三个 Storage 节点都是ONLINE状态 是启动了的
如果想要提高写入与删除性能可以考虑使用批量操作的方式
min.wu
15
system
关闭
16
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。