
贴一下完整的,看下前面tag 和edge的, 你这个reimport的内容有可能是 error.output目录中原有的内容。
你也可以自己用sparksql读一下hive的数据,看是不是乱码, exchange内部没做啥编码或转换的
我用的是exchange2.5.1. 通过HIVE生成SST导入后,相关属性为乱码。且HIVE查询结果正常。请问怎么解决?
在space下执行命令show charset:
(root@nebula) [gan_test25]> show charset;
+---------+-----------------+-------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+-----------------+-------------------+--------+
| "utf8" | "UTF-8 Unicode" | "utf8_bin" | 4 |
+---------+-----------------+-------------------+--------+
Got 1 rows (time spent 402/1333 us)
界面查询结果如下图

那几个带问号的乱码的数据是中文么? Exchange 和Nebula是支持中文导入的,你要用spark-shell 看下读出来的hive中的数据是什么样子的。

importer是发送graph请求导入的,sst是直接生成底层的SST文件,不经过graph服务的。 我们测过sst导入是支持中文的, 你可以用Exchange 的client 模式导入试下,是否还是乱码。
试过了,还是乱码。
那就是Exchange读出来的数据就是乱码了, client模式不会对数据做任何编码和转码的。你可以在本地编译器debug 看一下,把断点打在Exchange 文件的这一行
val data = createDataSource(spark, tagConfig.dataSourceConfigEntry)
通过代码调试后,确实显示中文异常了,但是通过spark-shell,执行spark.sql终端显示是正常的,难不成包问题?
extends ServerBaseReader(session, hiveConfig.sentence) {
private[this] val LOG = Logger.getLogger(this.getClass)
override def read(): DataFrame = {
LOG.info("===============sentence:"+sentence)
val data = session.sql(sentence)
data.show(10)
data
}
}
异常如下:

你的Exchange是采用什么模式提交的, 你的spark 版本和hive meta版本与Exchang的版本一致么。
我修改了spark对应的CDH版本。目前测试结果是:
1.yarn-cluster提交session.sql乱码。(且提交时已指定Driver,Executor等编码)
2.yarn-client提交后生成SST过程中乱码,session.sql查询出的结果是正常的,但是在生成SST前后已经乱码了,我还在调试,都调哭了。。。  )
)
大神,这是我yarn client提交后调试日志。

------------update:
经过最终测试,Driver端正常展示,而Executor则乱码,查阅相关资料后已经指定编码,仍旧没有解决。请问这个有碰到类似问题么?
/bin/spark-submit --master yarn --deploy-mode client --class com.vesoft.nebula.exchange.Exchange --files $CONFIG_FILE --conf spark.driver.extraJavaOptions="-Dfile.encoding=utf-8" --conf spark.executor.extraJavaOptions="-Dfile.encoding=utf-8" --conf spark.serializer=org.apache.spark.serializer.JavaSerializer --conf spark.sql.shuffle.partitions=2 --conf "spark.executor.extraJavaOptions=-XX:MaxPermSize=1025M" --driver-java-options -XX:MaxPermSize=2048m --driver-memory 4g --executor-memory 12g --executor-cores 8 --num-executors 4 --conf spark.driver.extraClassPath=/opt/cloudera/parcels/CDH/lib/spark/jars/guava-14.0.1.jar --conf spark.executor.extraClassPath=/opt/cloudera/parcels/CDH/lib/spark/jars/guava-14.0.1.jar debug_nebula-exchange-2.5.1.jar -c $CONFIG_FILE -h
查了资料看到是CDH集群中yarn也要加对应的编码配置:
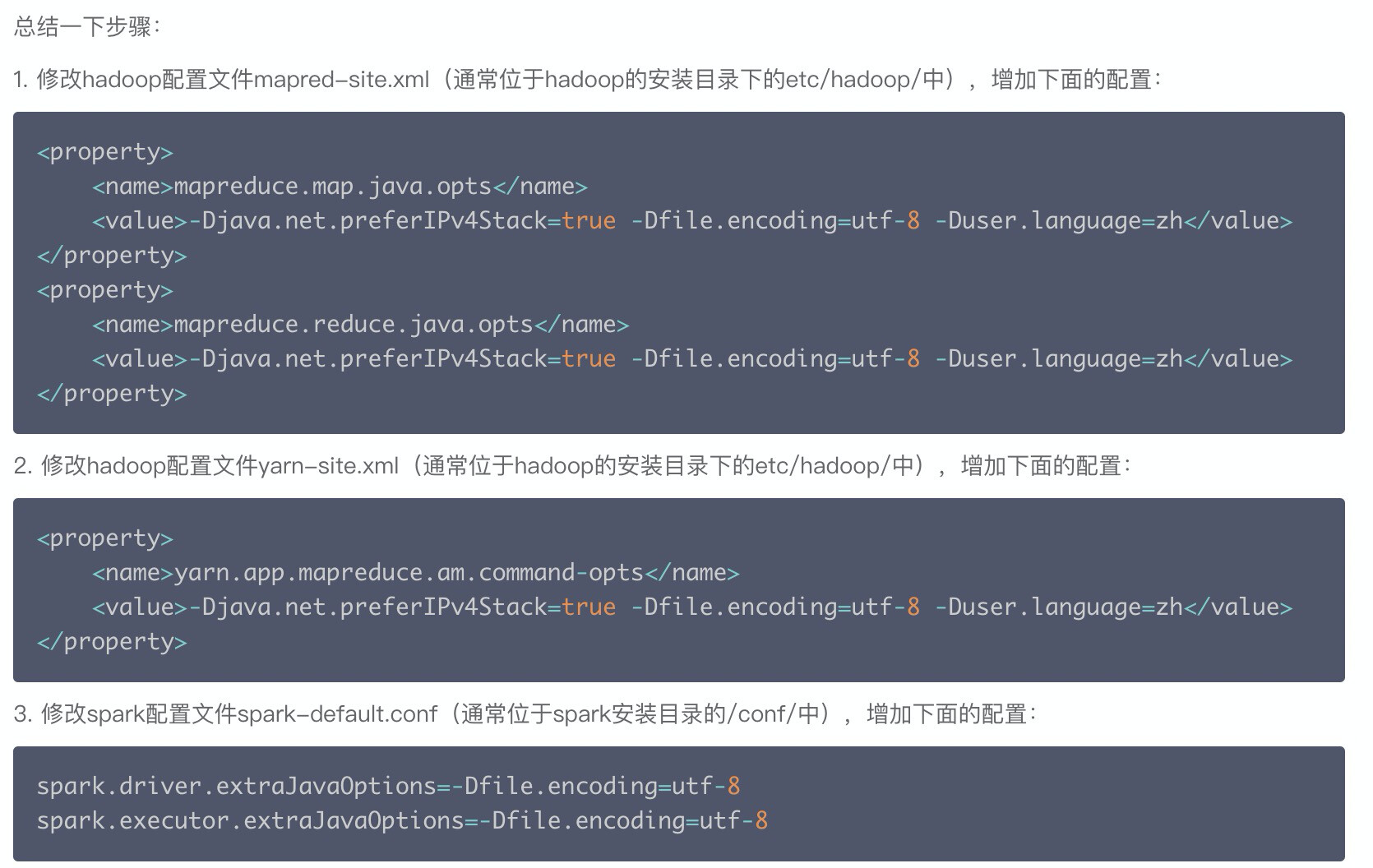
参考资料:CDH在yarn上运行程序乱码_yarn中文乱码 cdh-CSDN博客
ps:如果你的spark配置目录下有copy hadoop的部分配置文件,注意也同步更改下
是的,这个帖子我也看到了,正在调试。
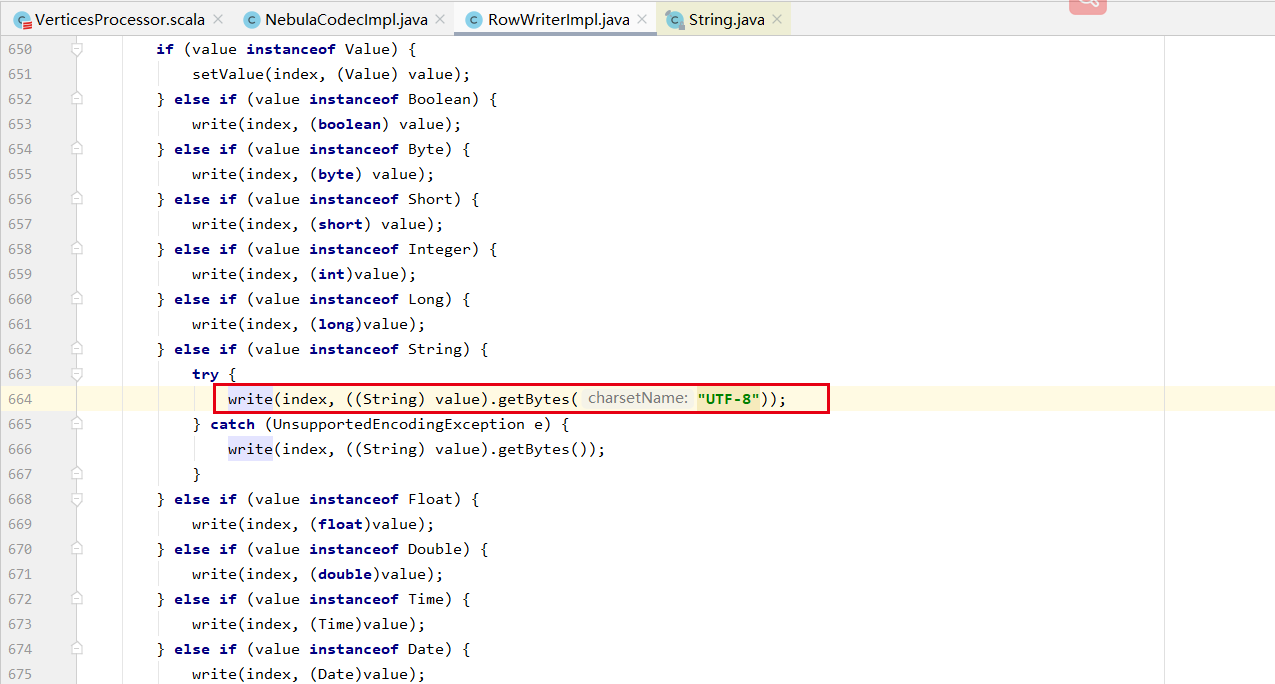
这是你改之后的代码, 不应该直接将"UTF-8" 指定给getBytes, 你可以看一下getBytes()源码里面在encode时会基于运行时环境的file.encoding来决定采用那种编码。
在执行程序时,是可以去指定file.encoding是UTF-8还是GBK的。 还是要看下你的集群系统中的file.encoding 是不是非UTF_8的。
嗯嗯,很奇怪的问题,我通过spark.sql模拟你们核心程序然后进行打印,其客户端及节点编码都是UTF-8.但是用你们的程序client提交时是UTF-8,Executor 相关task都变为ANSI了,而我相关的系统,JDK,集群,运行时参数都设置了UTF-8,但是最终执行是还是ANSI。跑了,跑了,跑了,定位问题太费时间了,最终能正常展示就好。谢谢大神。
 解决问题了就好, 后续有时间也可以帮忙看下原因 贴上来,方便遇到相同问题的其他用户借鉴哈~
解决问题了就好, 后续有时间也可以帮忙看下原因 贴上来,方便遇到相同问题的其他用户借鉴哈~