nebula版本 2.0.1 exchange 2.1.0 导入hive数据 字段中有中文 然后graphd.ERROR日志全部乱码
", ’
E0820 13:47:17.497861 170302 QueryInstance.cpp:103] SyntaxError: syntax error near v13� E0820 13:47:17.498091 170302 QueryInstance.cpp:103] SyntaxError: syntax error near “, 1000’
E0820 13:47:17.498358 170302 QueryInstance.cpp:103] SyntaxError: syntax error near W!:;:ァ E0820 13:47:17.498677 170302 QueryInstance.cpp:103] SyntaxError: syntax error near |12615”,’
E0820 13:47:17.498929 170302 QueryInstance.cpp:103] SyntaxError: syntax error near "2021-08' E0820 13:47:17.499222 170302 QueryInstance.cpp:103] SyntaxError: syntax error near 3’
E0820 13:47:17.499301 170278 QueryInstance.cpp:103] SyntaxError: syntax error near 4' E0820 13:47:17.499508 170278 QueryInstance.cpp:103] SyntaxError: syntax error near 201’
E0820 13:47:17.499758 170278 QueryInstance.cpp:103] SyntaxError: syntax error near 8", 400,' E0820 13:47:17.499792 170302 QueryInstance.cpp:103] SyntaxError: syntax error near o�6�’
E0820 13:47:17.500384 170302 QueryInstance.cpp:103] SyntaxError: syntax error near �:1ァ E0820 13:47:17.500650 170302 QueryInstance.cpp:103] SyntaxError: syntax error near ��Q’
E0820 13:47:17.501159 170302 QueryInstance.cpp:103] SyntaxError: syntax error near � 21' E0820 13:47:17.501482 170302 QueryInstance.cpp:103] SyntaxError: syntax error near wn@:I
E0820 13:47:17.502897 170302 QueryInstance.cpp:103] SyntaxError: syntax error near t�32ァ E0820 13:47:17.503197 170302 QueryInstance.cpp:103] SyntaxError: syntax error near "G��’
E0820 13:47:17.504768 170302 QueryInstance.cpp:103] SyntaxError: syntax error near �", " E0820 13:47:17.505137 170302 QueryInstance.cpp:103] SyntaxError: syntax error near "t��’
E0820 13:47:17.507226 170302 QueryInstance.cpp:103] SyntaxError: syntax error near `>��
你的 vid 用的是什么类型,然后执行下这个命令呢 SHOW CHARSET
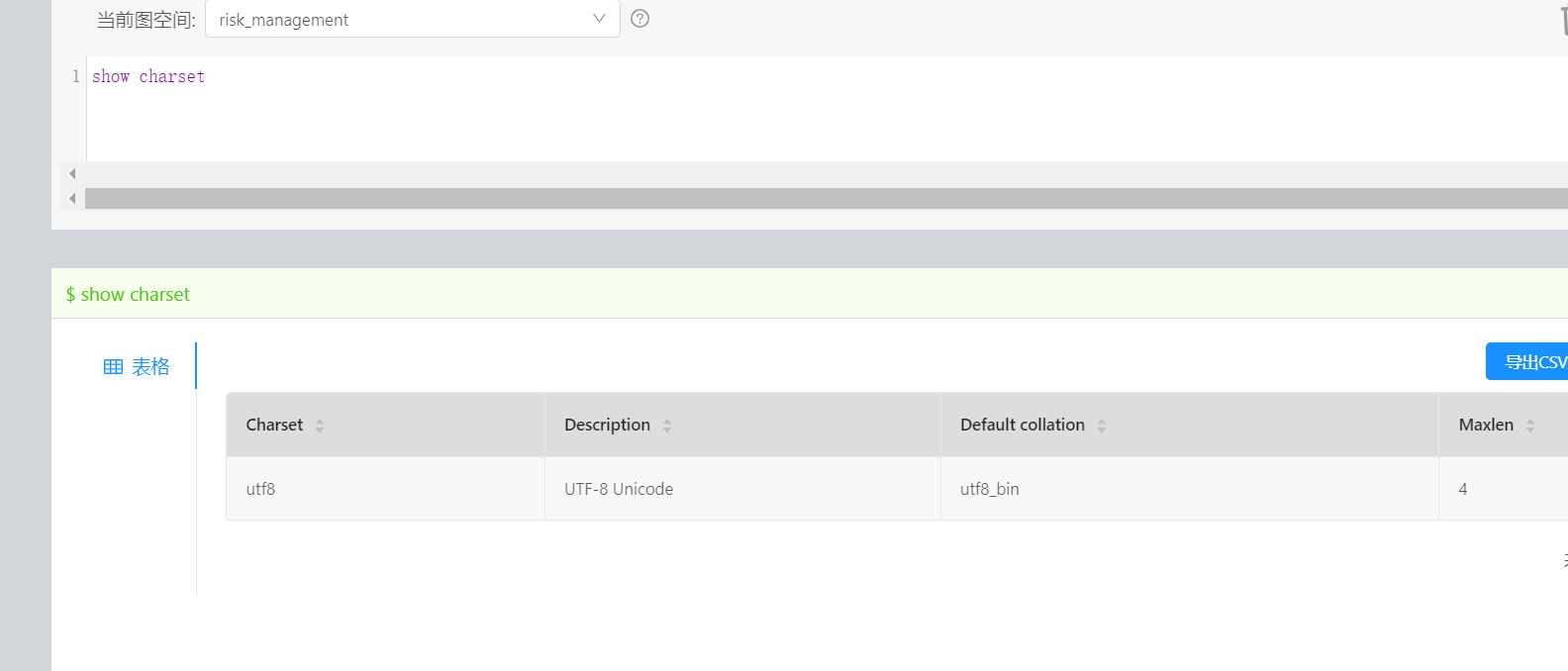
该中文字段是作为顶点属性的
string-64
并且 还有一个字段 是中文 作为另外一个属性 写入是没问题的
同样的问题 +1, vid_type为string64, charset为utf8,有三个字段是中文
nebula-exchange version: 2.0.1
nebula version: 2.0.1
我的理解,你使用了一个中文字符作为 prop 的属性名是吗?
不是 属性名 是属性值

嗯 是属性值 不是标签属性名称
我现在怀疑是某种脏数据造成的 因为我这边 有3亿数据 前2亿都没问题进去了 后边1亿开始报错 但是我又在想 这个底层不是spark的 df么 数据的值是啥 应该不是拼的 NGsql吧
nGQL ,G 是图 Graph 的意思。我让研发同学来看看
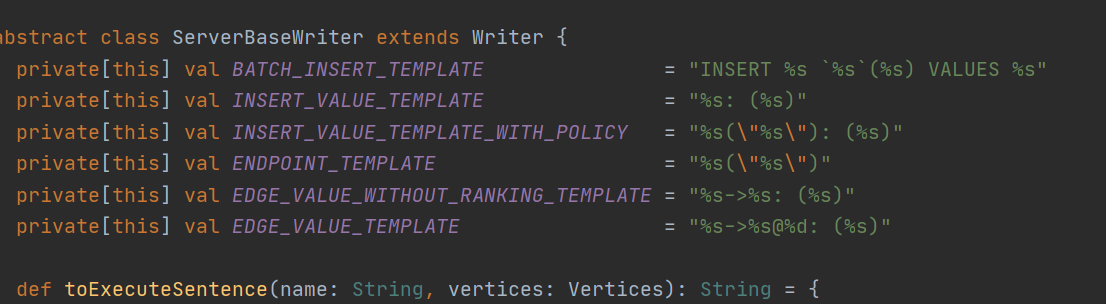
就是spark读取hive数据,统一处理成ngql语句发给Nebula graph服务的,读出来的vid数据应该就是乱码数据
我去hive查 是没问题的 而且 你看到没 目前是报错 语法错误
这个是spark 拼的 ngql 不可能语法错误
那你要看下Exchange的日志,这里只能看到语法错误,Exchange 日志里面有ngql语句的,你贴到console中执行下看看 (也贴到这看一下吧)
exchange日志? 去spark上面看吗?
你跑Exchange任务的时候 在控制台就会有日志。
如果你用yarn模式提交的,只要知道跑的exchange任务id就还能看日志 yarn -logs applicationId <application_id>