-
nebula 版本:2.5.0

-
部署方式(分布式 / 单机 / Docker / DBaaS):分布式
-
是否为线上版本:N
-
硬件信息: 16CPU、256G内存、10T HDD 磁盘
-
问题的具体描述:
通过如下方式创建、插入全文索引数据
CREATE FULLTEXT TAG INDEX nebula_index_10 ON player(name,alias);
LOOKUP ON player WHERE PREFIX(player.name, “Bluce”) YIELD player.name, player.alias, player.age;

全文索引生成的Elasticsearch中的index信息如下
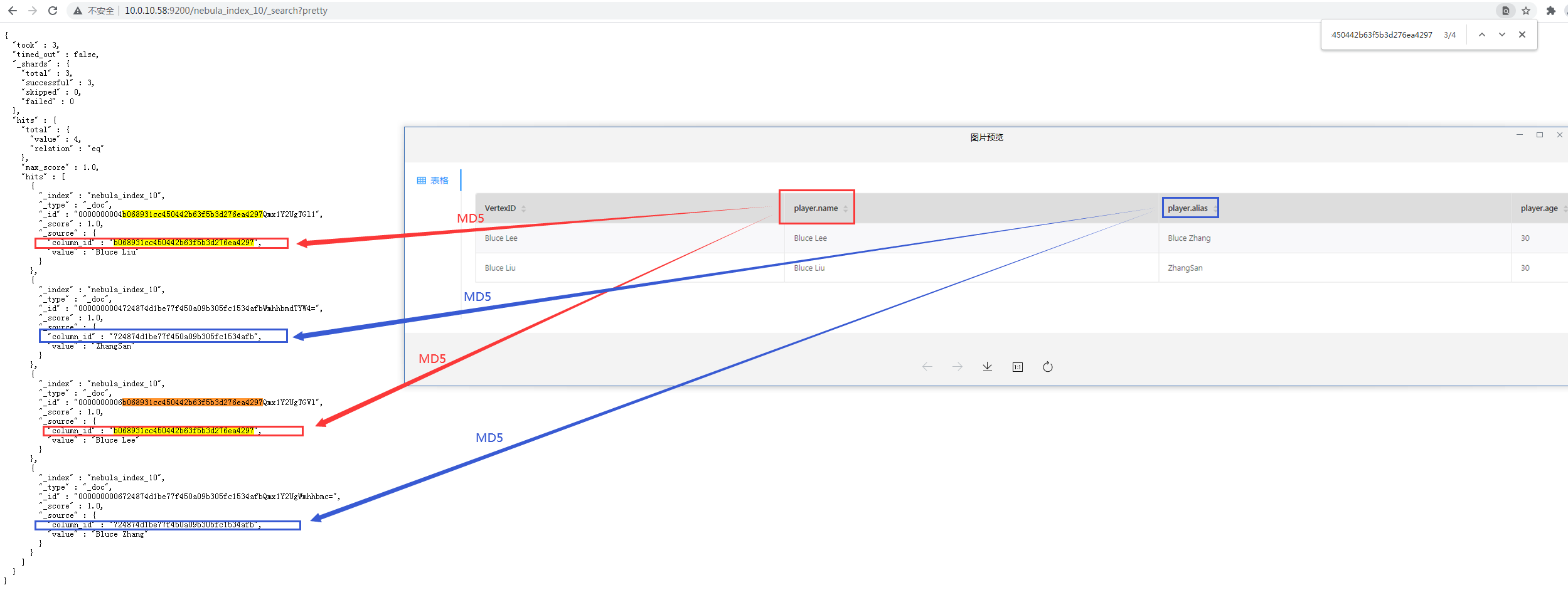
据观察了解到Elasticsearch的index中的column_id是根据字段name和alias按MD5加密生成的
请问Elasticsearch的index中的_id是根据什么来生成的?
是否能通过_id的值,查找到nebula中对应的数据?可以的话如何实现?