1.目前已经将数据导入了nebula建立了索引,python也可以连接nebula。目前想通过python将nebula数据取出来,利用graphX在python的graphframes包进行图计算,请问如何将读取的nebula数据转为如何转换可进行图计算的GraphFrame?
2.请问python取出来的nebula数据现在支持什么图计算框架吗?
3.nebula Algorithm配置文件中从nebula读数据,labels可以是多个边类型吗?上面写的多个labels时,多个边的数据将合并是什么意思?
- 我们目前提供的algorithm是基于Spark-conenctor 与Nebula进行数据关联的,Spark-Connector提供的是scala接口,可以在java中使用的。 没有pySpark接口。
- python取出来的nebula数据,你可以使用Networkx去计算的,中间数据要自己处理一下。
- labels可以支持多个边, 多个labels 会进行数据合并(union),就是会把多个edge type中的数据 作为一个大的边数据。

- 不知道你的nebula版本号和部署方式,给不出更多建议
- maxIter:最大迭代次数
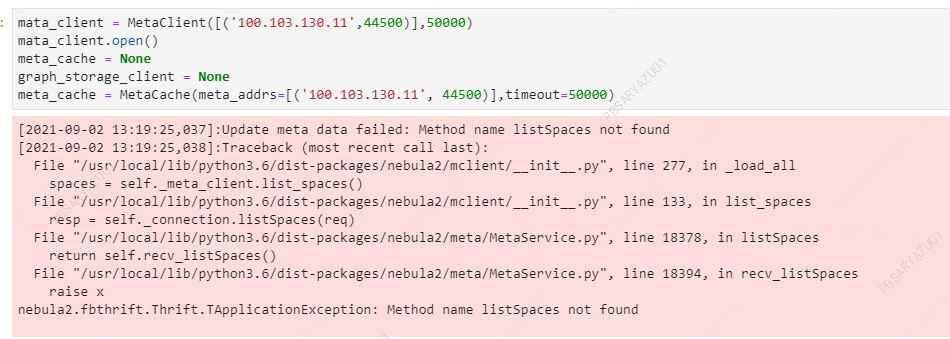
nebula是docker做的分布式部署,我不是root用户。Nebula是2.x版本,Nebula studio看到的版本号是v2.2.1
图空间的replica_factor=1,直接在studio里查到的host有3个;当时用nebula exchange从hive中导入数据时,只设置了图中报错的meta服务的ip和端口
Nebula 2.x, meta port是44500么, 那你把studio中查到的meta hosts贴出来。
大哥你是来逗我的么, 这是44500么  不是45500嘛
不是45500嘛
 不好意思,原来我看错了,我还看了好久源码
不好意思,原来我看错了,我还看了好久源码
我用scan_edge函数取数据, 用下面代码存数据:
while resp.has_next():
result = resp.next()
,请问报这个错是为什么?
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。