提问参考模版:
- nebula 版本:2.5.0
- 部署方式(分布式 / rpm
- 是否为线上版本:Y
- 硬件信息
- 磁盘ssd 500G
- CPU 16C、32G 内存信息
- 问题的具体描述
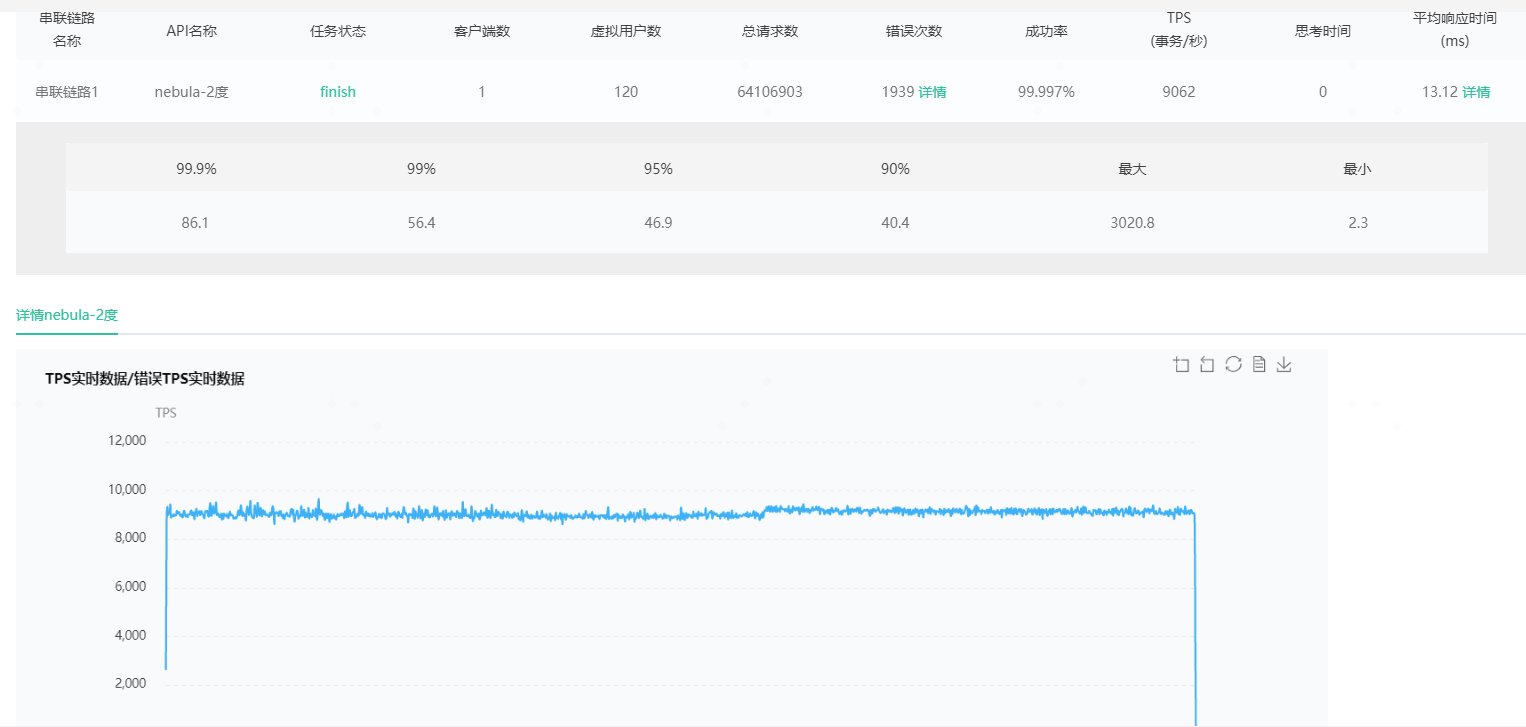
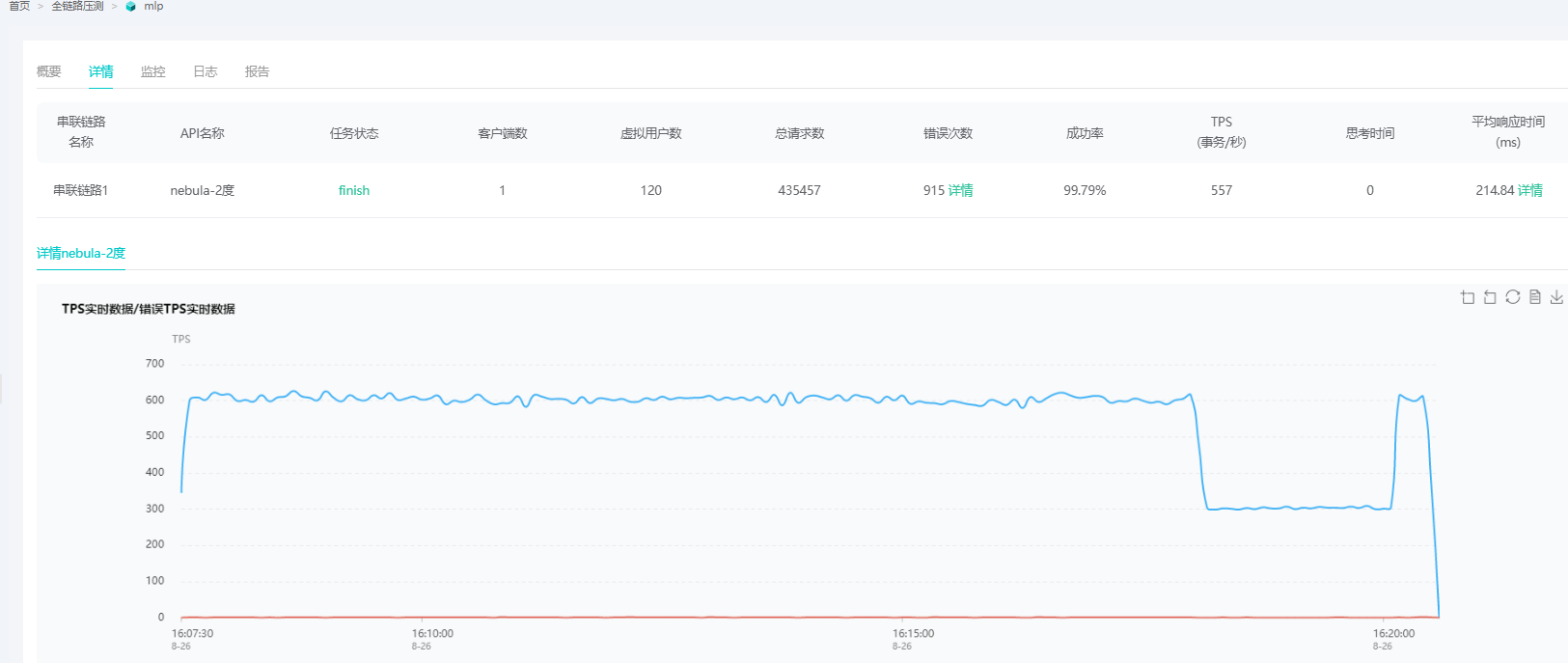
nebualGraph 2.5.0 压力测试比2.0.1 慢很多 数据量1.2亿节点,5亿边
提问参考模版:
Query 发下看看呢
单独查询还行,并发压测就变慢了
LOOKUP ON Thing WHERE Thing.Thing_name == “杭州市违法建设处理办法” | GO 2 STEPS FROM $-.VertexID OVER Thing_type YIELD $$.Thing.Thing_name |limit 100
从你数据上看,相差有 10 倍以上,这个相差太大了,我们自己对比没有这么大的差距。
你可不可以再多跑 2 次 2.5.0 的压测,会不会你跑 2.0.1 的时候,数据已经预热到内存里了?
我压测了好久的有几个小时的一样的时间
你们官方的时间相差多少,之前20ms ,现在200ms 就是我这边去掉一下网络不稳定啥的100ms ,也也要100ms还是慢很多,还有那些配置需要提供的,这个性能还是慢了,帮分析一下什么原因
配置是一模一样的?
日志都关着?
配置都一样的,直接升级用的就是2.5.0 的默认配置
我们自己测的只有在 500 并发下,相差大概 60%。
100 并发差不多的,25ms 左右
GO 2 STEP FROM {} OVER KNOWS yield $$.Person.firstName
不过每个环境都不太一样,我们后面比一下 lookup + pipe 的情况
应该用你之前的配置啊,默认配置都是线下测试用的,或者用生产配置
我都用的是默认生产的配置文件,不是测试配置文件
那些配置参数可以增加查询性能的呀告诉我一下。
还有你们官方文档的配置说明可以在写的完善一点吗,把那些参数配置可以增加性能啥的标注一下,我看文档只是简单说明了一下,没有很清楚的描述该参数到底有啥作用,用户看了也不知道该调配那些有用参数
怎么把我的这个贴子给取消公开了啊?????
先不管帖子公布公开问题,我关心的是我这边2.5.0性能慢了,希望你们帮分析一下原因,这边生产急用不然这边只能回退到2.0.1 了
LOOKUP ON Thing WHERE Thing.Thing_name == “杭州市违法建设处理办法” | yield count(*)
大概多少量级?
数据量1.2亿节点,5亿边
有几个问题,要关注一下。