- nebula 版本:1.x(nebula 仓最新 master 版本), 之前使用的1.1.0版本和目前neblua 1.x 仓库上master 上最新的都有这个问题
- 部署方式(分布式 / 单机 / Docker / DBaaS):Docker
- 是否为线上版本 N
- 硬件信息
-SSD
- 问题的具体描述:
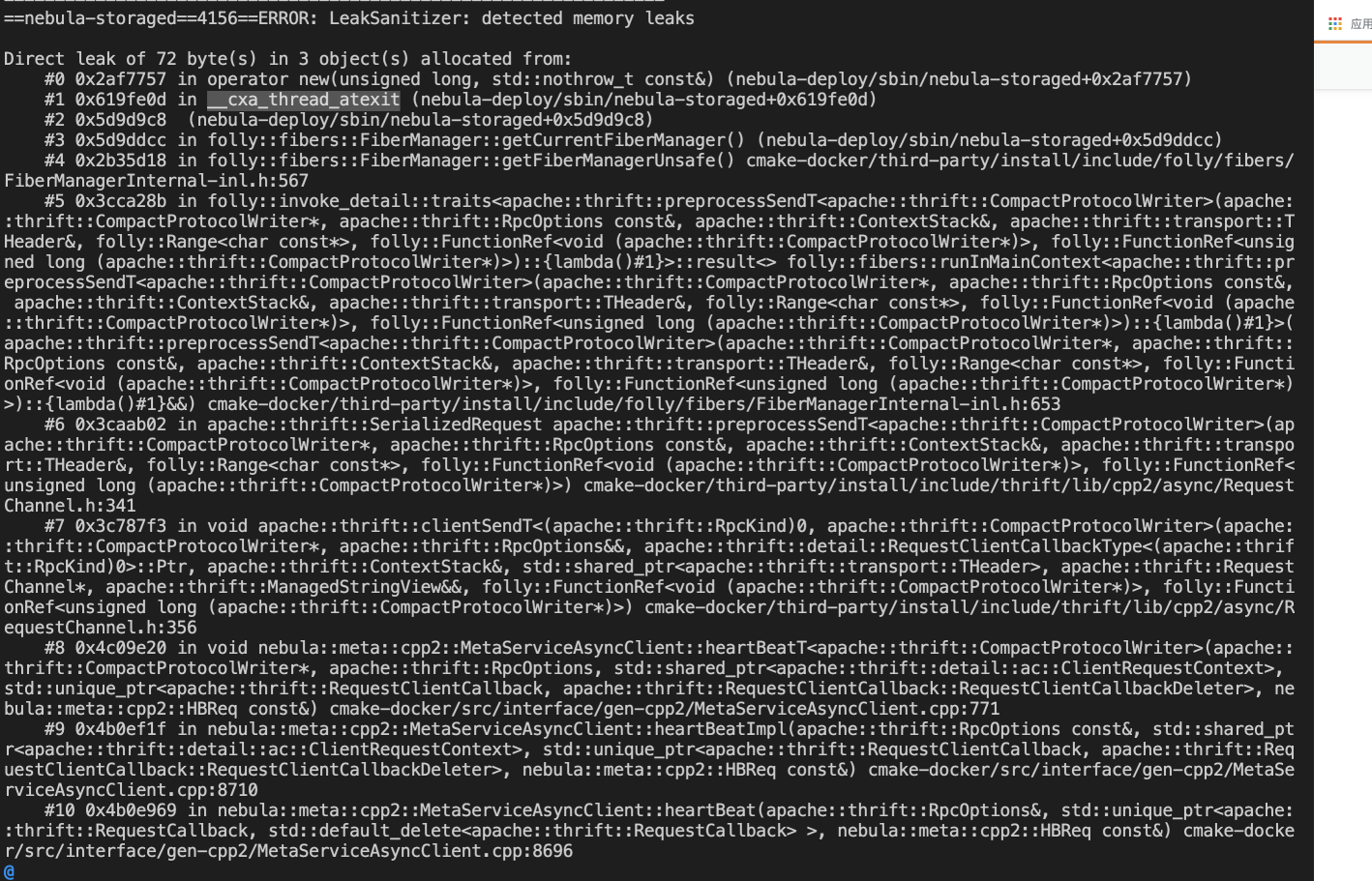
在AddressSanitizer 进行内存检测的时候发现有内存泄漏的情况, 主要都是__cxa_thread_atexit 造成的
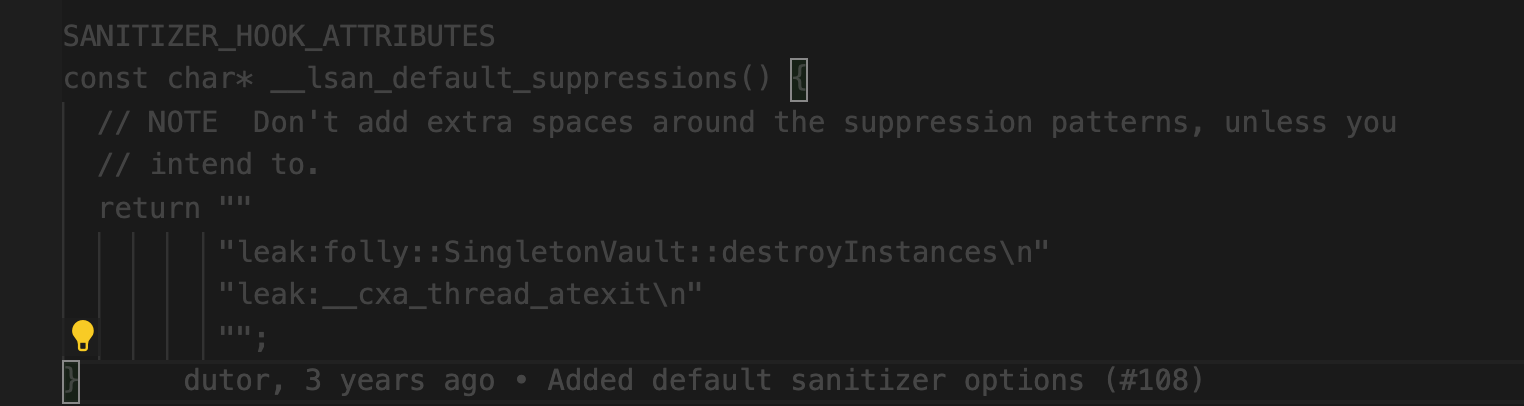
发现目前新代码中检测的时候默认是会把__cxa_thread_atexit 限制不检测的。
想请教下忽略__cxa_thread_atexit 这个不检测的原因,这个实际上会不会造成内存泄漏的?
因为目前起一个空的storaged,发现内存还是会比较缓慢的增长,所以想要排查下原因
如果是一天大概100M这样子。主要想了解的是看到代码里添加了忽略__cxa_thread_atexit 这个函数的内存泄漏检查,但实际测试出来这里会发生泄漏的,想了解这个原因?
folly有点问题,这个地方问题不大的,之前分析过。
这个泄漏主要是由folly 的多线程造成的吗?泄漏的数据量主要和什么因素有关系的?这边线上环境的感觉内存增长比空的增长快很多,不知道这个和数据量有关系的不
是一些静态数据。线上环境内存增长跟缓存有关,rocksdb的cache,jemalloc的cache。
rocksdb 的cache 有进行配置了,想问下jemalloc 的cache 有哪个参数可以配置的吗?
另外想再请教下,这些增长的静态数据是会一直增,还是会有个上限的?
大佬另外请教请教下,这边看了下内存的估计,发现需要点和边数量15 字节,这个是为了什么的?看了下代码,没有找到相关的需要这部分的逻辑。如果点的属性cache ,好像也是可以配置的,也不用点边数量15 字节。 不知道这个和内存的增加有没有关系,因为线上环境的数据确实是比较多的。
image
system
关闭
19
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。