
开源之夏
开源软件供应链点亮计划 - 暑期 2021(下简称:开源之夏)是由中国科学院软件研究所与 openEuler 社区共同举办的一项面向高校学生的暑期活动,旨在鼓励在校学生积极参与开源软件的开发维护,促进优秀开源软件社区的蓬勃发展。中科院联合包括 Nebula Graph 在内的国内各大开源社区,针对重要开源软件的开发与维护提供项目,并向全球高校学生开放报名。学生在自由选择项目后,与社区导师沟通实现方案并撰写项目计划书。被选中的学生将在社区导师指导下,按计划完成开发工作,并将成果贡献给社区。根据项目的难易程度和完成情况,参与者将获得由主办方发放的 6,000 - 12,000 不等的项目奖金。
活动官网:https://summer.iscas.ac.cn/
本期分享来自 Nebula Graph 社区郑东阳同学(图数据库 Nebula Graph 支持 JDBC 协议)的项目经验。
项目信息
项目名称:图数据库 Nebula Graph 支持 JDBC 协议
项目详情
让 Nebula Graph 可以对接 JDBC 协议,实现 Nebula JDBC driver,实现 JDBC 的相关接口。要求:用户可直接使用 JDBC 驱动操作 Nebula 服务,项目 repo 有自动运行的单元测试。
Nebula Graph 简介
一个可靠的分布式、线性扩容、性能高效的图数据库;世界上唯一能够容纳千亿个顶点和万亿条边,并提供毫秒级查询延时的图数据库解决方案。Nebula Graph 特点
- 开源:致力于与社区合作, 普及及促进图数据库的发展;
- 安全:具有基于角色的权限控制,授权才能访问;
- 扩展性:支持 Spark、Hadoop、GraphX、Plato 等等多种周边生态工具;
- 高性能:Nebula Graph 在维持高吞吐量的同时依旧能做到低时延的读写;
- 扩容:基于 shared-nothing 分布式架 Nebula Graph 支持线性扩容;
- 兼容 openCypher:逐步兼容 openCypher9 ,Cypher 用户可轻松上手 Nebula Graph;
- 高可用:支持多种方式恢复异常数据,保证在局部失败的情况下服务的高可用性;
- 稳定发行版:经过一线互联网大厂,诸如京东、美团、小红书在生产环境上的业务考验。
Nebula Graph 具有活跃的社区与及时的技术支持,这是官网:https://nebula-graph.com.cn 和 GitHub 仓库:https://github.com/vesoft-inc/nebula,欢迎关注及使用 Nebula Graph,一起成为 Nebula Graph 的 Contributor,为图数据库的发展贡献力量!!!
项目落地
方案描述
前期了解 Nebula Graph 相关功能,掌握其基本使用;调研 JDBC 的驱动开发,阅读 JDBC 规范文档,了解一些需要实现的接口;中期参考 Neo4j 的 neo4j-jdbc:https://github.com/neo4j-contrib/neo4j-jdbc 实现,克隆 nebula-java:https://github.com/vesoft-inc/nebula-java 项目,学习源码,了解项目代码的主要逻辑和代码风格;后期利用已有的轮子 nebula-java:https://github.com/vesoft-inc/nebula-java 实现与数据库的通信,编写代码为 Nebula Graph 实现 JDBC 的相关接口, 编写单元测试。
实现描述
这个项目实现的思路很清晰:implements JDBC 规范中的一系列接口(主要位于 java.sql 包中),实现接口中的方法。JDBC 规范中所有的类加起来需要实现的方法有好几百个。JDBC 主要面向的数据库是传统的关系型数据库(RDB),而 Nebula Graph 作为新一代的图数据库,比起久经发展的关系型数据库来说没有它那么完备的功能特性,但是又比关系型数据库多出许多新的特点,所以 JDBC 规范中的方法对于 Nebula Graph 而言既有多余(不需要真正实现)也有不足。(需要实现但是没有在相关接口中定义)
在具体的实现中,定义出一些抽象类直接 implements 规范中的主要接口,再定义出具体的实现类实现接口中一些重要的方法,这样一来实现类中的方法在阅读时不会显得很杂很乱。对于接口中需要实现的方法:
for( method : 接口的方法 ){
if(method BELONG_TO 不需要具体实现的方法){
// 比如 Statement::getGeneratedKeys()
在该抽象类中 Override,方法体中抛出一个SQLFeatureNotSupportedException;
}else if(method BELONG_TO 需要实现但是不是核心方法){
// 比如 Statement::isClosed()
在该抽象类中 Override;
}else if(method BELONG_TO 需要实现且是核心方法){
// 比如 Statement::execute(String nGql)
在具体实现类中 Override
}else if(method BELONG_TO 在接口中没有定义但是需要实现){
// 比如 NebulaResult::getNode getEdge getPath (点,边,路径是图数据库特有概念)
在具体实现类中实现
}
}
项目中主要的一些 implements 和 extends 关系如下:(蓝色实线是类之间的 extends 关系,绿色实线是接口之间的 implements 关系,绿色虚线是抽象类与接口之间的 implements 关系)。
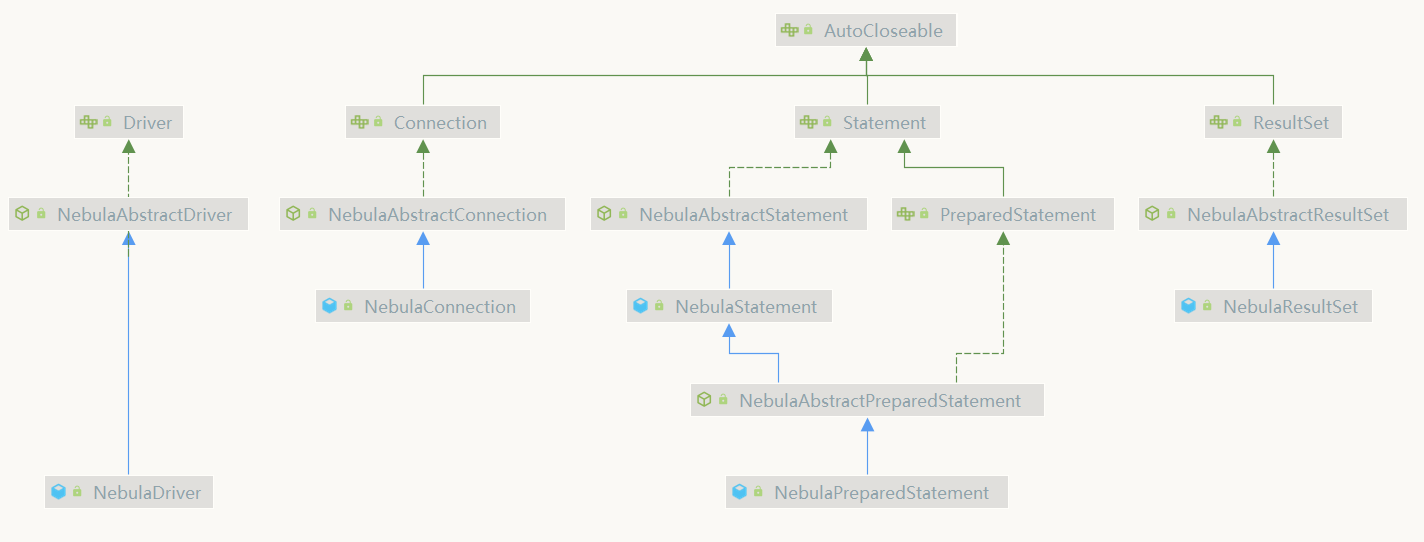
工作流程及类中主要方法分析:
// 用户首先通过 NebulaDriver 注册驱动,其中有 NebulaPool 属性,用于获取 Session 与数据库通信
// NebulaDriver 中提供两个构造函数,无参构造函数配置默认的 NebulaPool,接收一个 Properties 类型参数的构造函数可以自定义 NebulaPool 配置
public NebulaDriver() throws SQLException {
this.setDefaultPoolProperties();
this.initNebulaPool();
// 将自身注册到 DriverManager
DriverManager.registerDriver(this);
}
public NebulaDriver(Properties poolProperties) throws SQLException {
this.poolProperties = poolProperties;
this.initNebulaPool();
// 将自身注册到 DriverManager
DriverManager.registerDriver(this);
}
// 注册驱动后用户可以 DriverManager::getConnection(String url) 获取连接。在 NebulaConnection 的构造函数中会通过 NebulaDriver 中的 NebulaPool 获取 Session 接着连接访问在 url 中指定的图空间
// 获取到 Connection 后用户可以用 Connection::createStatement 和 Connection::prepareStatement 拿到 Statement 或者 PreparedStatement 对象,调用其中的 execute 方法向数据库发送命令,数据库执行此命令后的结果会封装在 NebulaResult 中,再调用其中各种获取数据的方法可以得到不同数据类型的数据
// 目前 NebulaResult 中实现的获取数据方法有以下这些,Nebula Graph 中不同的数据类型都有对应实现
public String getString();
public int getInt();
public long getLong();
public boolean getBoolean();
public double getDouble();
public java.sql.Date getDate();
public java.sql.Time getTime();
public DateTimeWrapper getDateTime();
public Node getNode();
public Relationship getEdge();
public PathWrapper getPath();
public List getList();
public Set getSet();
public Map getMap();
项目进度
已完成工作
- 部署 Nebula Graph 并掌握其基本使用;
- 阅读 JDBC:https://download.oracle.com/otn-pub/jcp/jdbc-4_2-mrel2-spec/jdbc4.2-fr-spec.pdf?AuthParam=1628844546_d5f078af230e42dcbe0ba3d183af7495 规范文档,明确实现要求;
- 学习 nebula-java:https://github.com/vesoft-inc/nebula-java 源码;
完成以下实现:
遇到的问题及解决方案
如何与数据库通信的问题:
项目前期过程中不知道如何与数据库通信,在研究友商 Neo4j 的 neo4j-jdbc 实现后利用 Http 框架通过 Nebula Graph 的 API (粗糙地)实现了与数据库的通信;完成后与导师联系询问该想法是否可行,导师告诉我可以用已有的轮子 nebula-java,通过 rpc 与 Nebula Graph 通信。
数据统计采用了计算复合指标的方法,计算得出各家企业在企业规模、社会影响、发展潜力和社会责任四个维度上的得分,加权平均后确定排名。
关于获取 Connection 的问题:
NebulaPoolConfig 类中的一些参数是可配置的,我的想法是以在连接字符串中指定的形式进行配置,如:“jdbc:nebula://ip:port/graphSpace?maxConnsSize=10&reconnect=true”。
咨询导师后导师建议可以让用户获取连接的时候,支持两种接口,一种是用默认配置,一种是让用户指定配置,如:
// default configuration
DriverManager.getConnection(url, username, password);
// customized configuration
DriverManager.getConnection(url, config);
关于 PreparedStatement 的问题:
关系型数据库支持查询语句预编译的功能,PreparedStatement 可以向 DBMS 发送 SQL 让其预编译然后再传参数,提高了性能且能防止 SQL 注入攻击;目前 Nebula Graph 暂无此功能, 所以在本地解析 nGQL 中的占位符再将参数填充进去,本质上与 Statement 相同。
nebula-java 版本问题:
一开始在项目中引入的依赖的 2.0.0 版本,在一次查询中发现其路径返回结果与控制台返回结果不一致,咨询导师后发现这是这个版本中的 bug,改用最新的 2.0.0-SNAPSHOT 版本。
updateCount 问题:
JDBC 接口中一些方法要求返回值是收到此方法影响的数据量 updateCount,但目前服务端没有 updateCount 统计返回给用户。假如用户一条插入语句里面同时插入多个点或者多条边,这里面可能有部分成功,但服务端只会返回告诉用户失败了,但是其实用户可能能查到部分数据。这个 updateCount 按照 0 返回,然后在接口添加注释说明不支持。
NebulaPool 初始化问题:
一开始我是在初始化 NebulaConnection 时初始化 NebulaPool 再获取 Session,而且搞混了对于 NebulaPool 的配置和对于 Session 的配置。这样的话用户每次获取 Connection 时都会重新初始化 NebulaPool,是不合理的,我提交代码到 Gitlab 导师 review 后指出了我的错误,建议我将 NebulaPool 的 初始化和关闭移到 NebulaDriver 中,再提高默认配置和自定义配置两种方式初始化 NebulaPool。
后续工作安排
- 完成接口中应该实现但未实现的方法 ;
- 完善代码注释 ;
- 完成单元测试 ;
- 编写使用说明 .
致谢
这次活动促进了开源软件的发展和优秀开源软件社区建设,增加开源项目的活跃度,推进开源生态的发展;感谢 @开源之夏主办方 为这次活动提供的平台与机会。
感谢导师 @laura.ding 在这过程中认真地 review 我 PR 的代码,予以我细致的指导让我知晓自己的不足;感谢 @NebulaGraph 运营小姐姐寄给我的社区周边,LUCKY!
以上,感谢阅读!