- nebula 版本:2.5
- 部署方式(分布式 / 单机 / Docker / DBaaS):单机
问题汇总:
1.程序执行在处理边数据时,报错Keys must be added in strict ascending order
2.生成的点SST数据导入后,数据量错误,且未有错误数据生成。
操作:
尝试使用exchange 进行sst数据导入,csv → sst ,数据为2个点表1个边表
第一次直接使用v2.5分支进行打包,运行程序,报错 Filesystem colsed 。
然后使用master最新代码打包,仍然一样的报错,
查看代码发现每次使用之后都会close,于是修改了代码,将hdfs的 FileSystem获取改成每次new一个
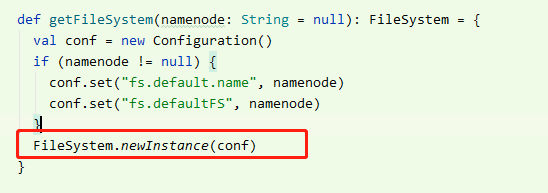
此时这个报错解决。
继续执行程序,发现报错Keys must be added in strict ascending order
org.rocksdb.RocksDBException: Keys must be added in strict ascending order.
at org.rocksdb.SstFileWriter.put(Native Method)
at org.rocksdb.SstFileWriter.put(SstFileWriter.java:132)
at com.vesoft.nebula.exchange.writer.NebulaSSTWriter.write(FileBaseWriter.scala:44)
at com.vesoft.nebula.exchange.processor.EdgeProcessor$$anonfun$process$3$$anonfun$apply$5.apply(EdgeProcessor.scala:251)
at com.vesoft.nebula.exchange.processor.EdgeProcessor$$anonfun$process$3$$anonfun$apply$5.apply(EdgeProcessor.scala:225)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at com.vesoft.nebula.exchange.processor.EdgeProcessor$$anonfun$process$3.apply(EdgeProcessor.scala:225)
at com.vesoft.nebula.exchange.processor.EdgeProcessor$$anonfun$process$3.apply(EdgeProcessor.scala:220)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:935)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
查看了spark的执行过程,以及报错位置发现是在处理边数据的时候报错的。
于是把配置文件的边表去掉,然后执行成功了!
然后手动下载SST文件到download文件夹,执行命令导入,也成功了。
I0916 23:07:02.503427 15564 NebulaStore.cpp:807] Ingesting extra file: data/storage/nebula/108/download/15/15-2.sst
I0916 23:07:03.170876 15564 EventListener.h:96] Ingest external SST file: column family default, the external file path data/storage/nebula/108/download/15/15-2.sst, the internal file path data/storage/nebula/108/data/001642.sst, the properties of the table: # data blocks=255; # entries=5112; # deletions=0; # merge operands=0; # range deletions=0; raw key size=1104192; raw average key size=216.000000; raw value size=46008; raw average value size=9.000000; data block size=218651; index block size (user-key? 0, delta-value? 0)=14538; filter block size=0; (estimated) table size=233189; filter policy name=N/A; prefix extractor name=nullptr; column family ID=N/A; column family name=N/A; comparator name=leveldb.BytewiseComparator; merge operator name=nullptr; property collectors names=[]; SST file compression algo=Snappy; SST file compression options=window_bits=-14; level=32767; strategy=0; max_dict_bytes=0; zstd_max_train_bytes=0; enabled=0; ; creation time=0; time stamp of earliest key=0; file creation time=0; DB identity=; DB session identity=;
I0916 23:07:03.170965 15564 NebulaStore.cpp:807] Ingesting extra file: data/storage/nebula/108/download/15/15-25.sst
I0916 23:07:03.180029 15564 EventListener.h:96] Ingest external SST file: column family default, the external file path data/storage/nebula/108/download/15/15-25.sst, the internal file path data/storage/nebula/108/data/001643.sst, the properties of the table: # data blocks=257; # entries=5131; # deletions=0; # merge operands=0; # range deletions=0; raw key size=1108296; raw average key size=216.000000; raw value size=46179; raw average value size=9.000000; data block size=218474; index block size (user-key? 0, delta-value? 0)=14409; filter block size=0; (estimated) table size=232883; filter policy name=N/A; prefix extractor name=nullptr; column family ID=N/A; column family name=N/A; comparator name=leveldb.BytewiseComparator; merge operator name=nullptr; property collectors names=[]; SST file compression algo=Snappy; SST file compression options=window_bits=-14; level=32767; strategy=0; max_dict_bytes=0; zstd_max_train_bytes=0; enabled=0; ; creation time=0; time stamp of earliest key=0; file creation time=0; DB identity=; DB session identity=;
E0916 23:07:03.180132 15564 StorageHttpIngestHandler.cpp:64] SSTFile ingest successfully
I0916 23:07:03.220342 5692 EventListener.h:30] Rocksdb compaction completed column family: default because of LevelL0FilesNum, status: OK, compacted 5 files into 1, base level is 0, output level is 1
I0916 23:07:03.223326 5692 EventListener.h:18] Rocksdb start compaction column family: default because of LevelL0FilesNum, status: OK, compacted 5 files into 0, base level is 0, output level is 1
I0916 23:07:03.223409 5692 CompactionFilter.h:66] Do default minor compaction!
I0916 23:07:03.558279 5692 EventListener.h:30] Rocksdb compaction completed column family: default because of LevelL0FilesNum, status: OK, compacted 5 files into 1, base level is 0, output level is 1
I0916 23:07:25.135828 15503 SlowOpTracker.h:33] [Port: 9780, Space: 6, Part: 5] total time:88ms, Write WAL, total 2
I0916 23:07:27.825093 15517 AdminTask.cpp:20] createAdminTask (113, 0)
I0916 23:07:27.825197 15517 AdminTaskManager.cpp:35] enqueue task(113, 0), con req=2147483647
I0916 23:07:27.825259 15569 AdminTaskManager.cpp:101] dequeue task(113, 0)
I0916 23:07:27.825428 15569 AdminTaskManager.cpp:139] run task(113, 0), 15 subtasks in 10 thread
I0916 23:07:27.825592 15569 AdminTaskManager.cpp:89] waiting for incoming task
看日志也执行成功了。
去控制台查看数据量,也做compact,再计算数据量,发现缺失很多

文件480w只写入80多条
文件200w,写入199w+,正常。
文件存在重复数据,但是重复量很少。
(执行的时候不知道怎么搞的,会打印出错的信息,hs的log日志和core的文件,后来又不出来了…)