bai
2021 年9 月 17 日 05:31
1
nebula版本:2.0.1
请问有什么好的解决方案吗?
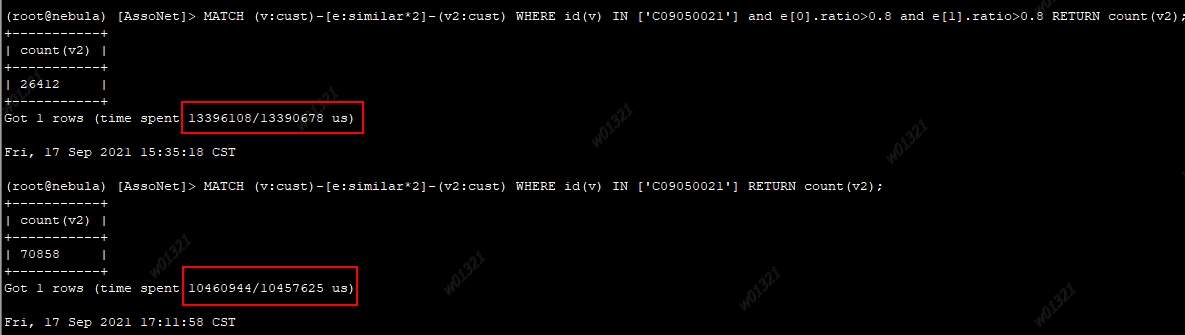
下图是通过VID查询得到某客户的效果图:
steam
2021 年9 月 17 日 08:07
2
bai:
慢到无法应用的程度(花费14s)
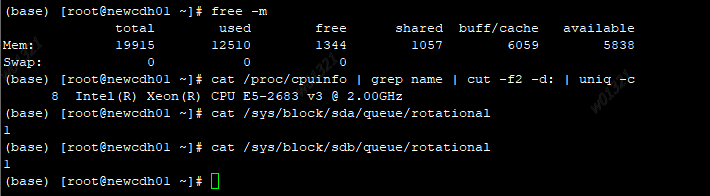
涉及性能问题,把硬件配置贴一下,磁盘类型,CPU 核数和内存大小
bai
2021 年9 月 17 日 09:28
5
nebula是3台的集群
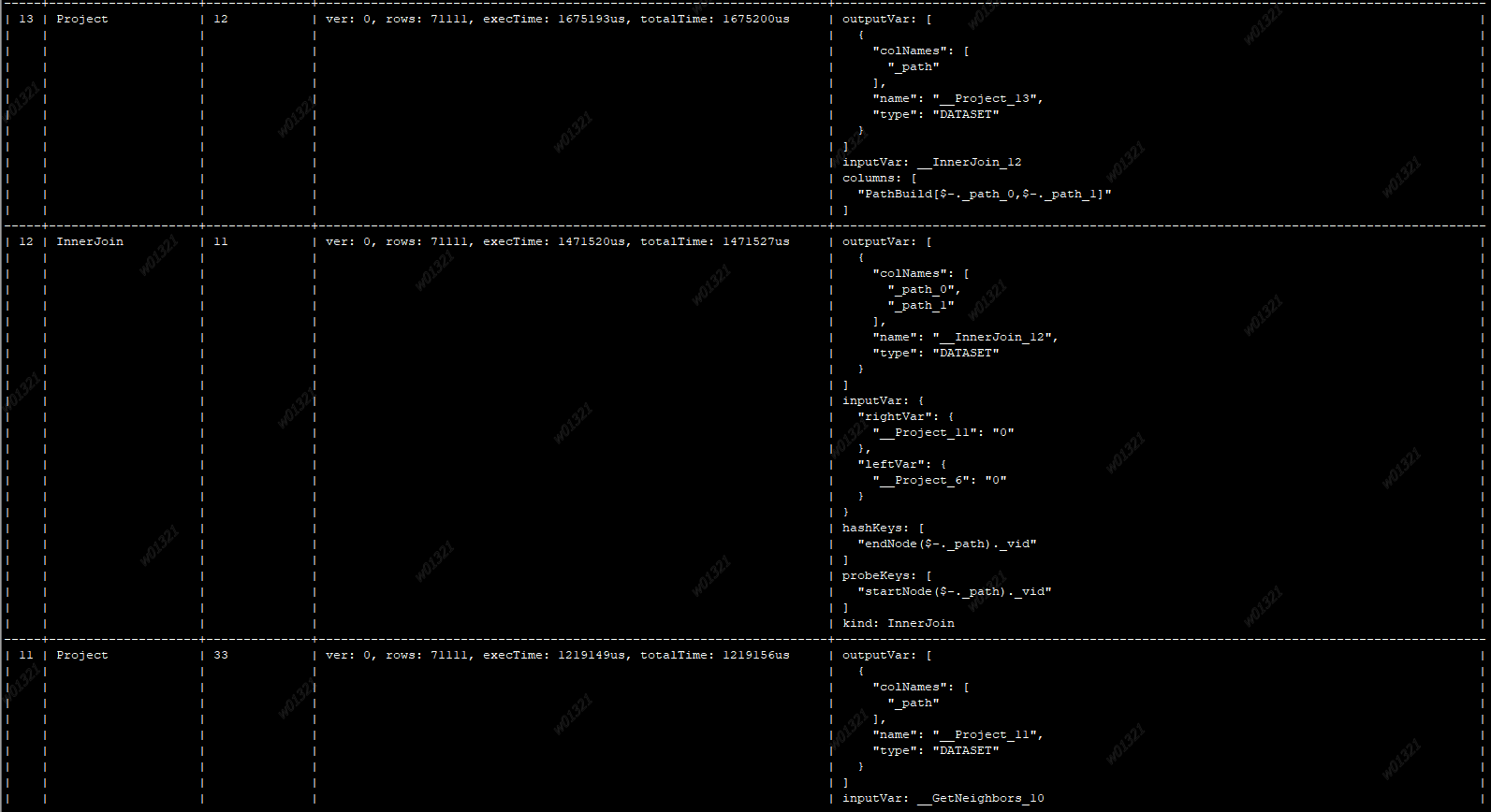
后台查询结果:
情况说明:
看看有没有优化空间?
bai
2021 年9 月 17 日 09:31
6
基本都是两两相连。遍历的路径有些多,但是需要统计不重复的v2其实也不多。
kyle
2021 年9 月 22 日 03:36
7
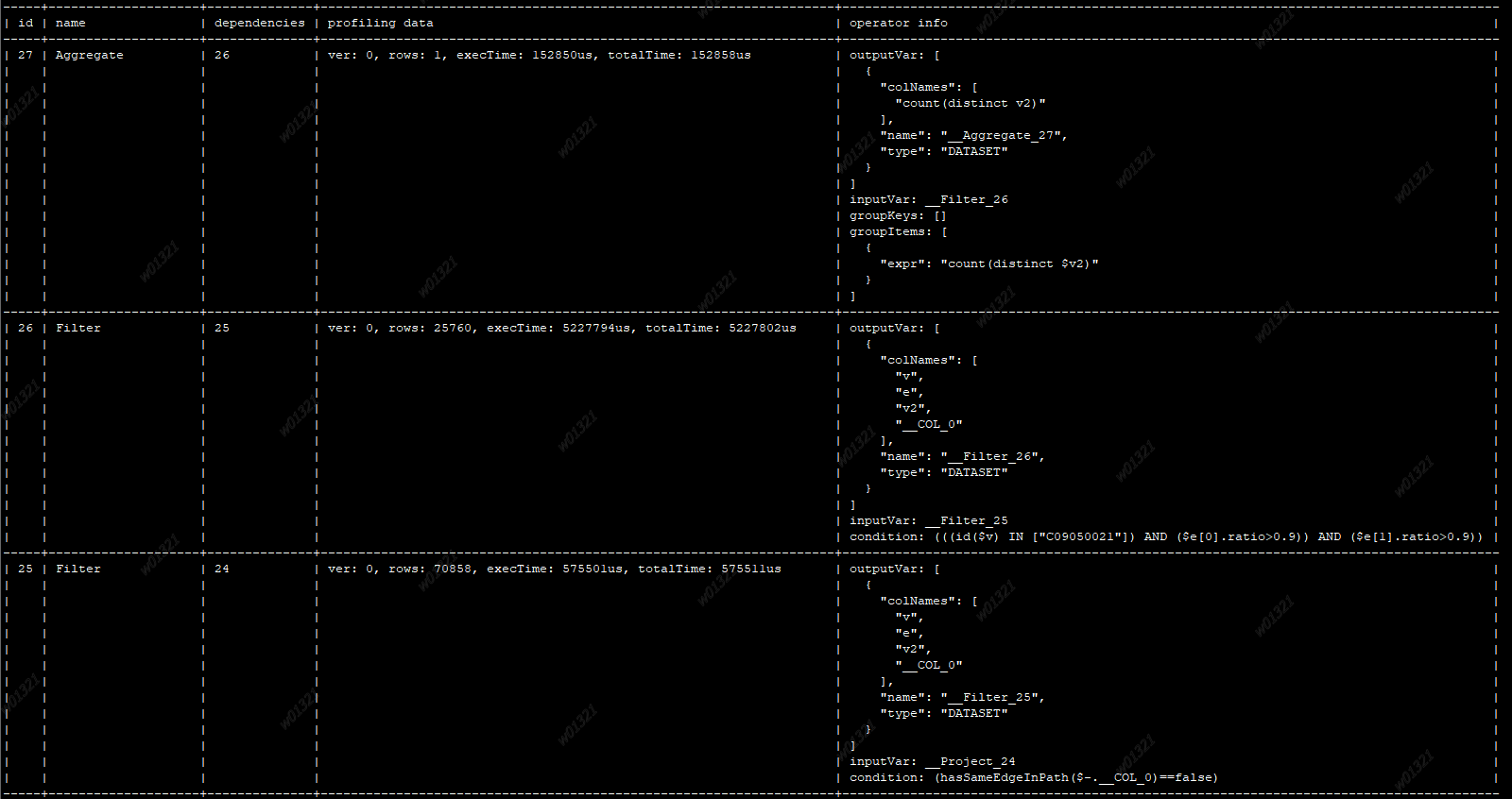
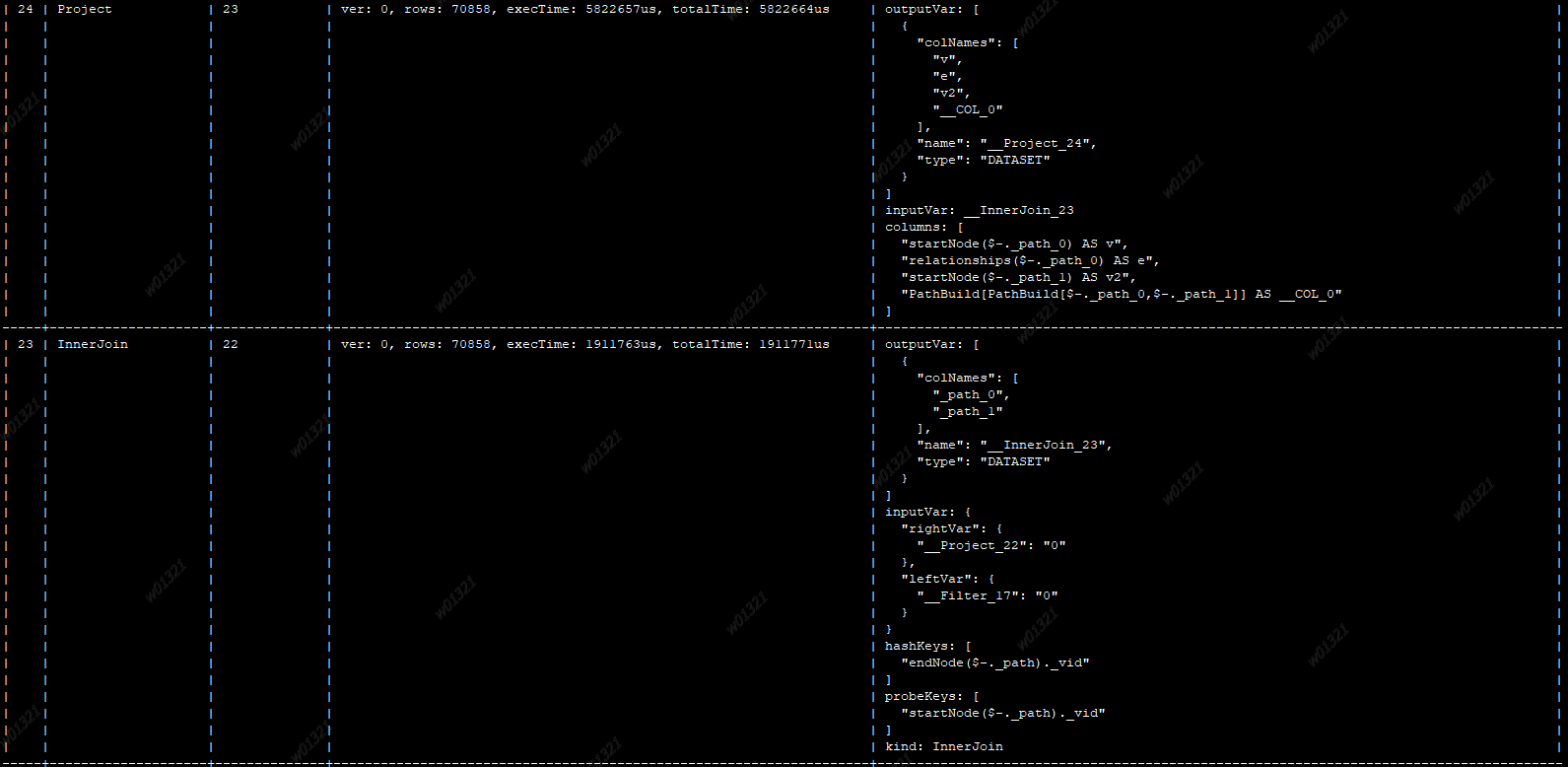
你在后台运行语句前面加个 profile,看一下执行计划具体耗时
kyle
2021 年9 月 22 日 08:04
9
Filter 性能退化在 2.0.1 是已知问题,最新的 release 版本已经修复。
bai
2021 年9 月 22 日 08:11
10
除了Filter耗时外,还有project、innerjoin等也比较耗时,升级到最新版本2.5.0,估计类似的场景下,这个请求还是无法达到3秒以内
kyle
2021 年9 月 22 日 08:20
11
对的,project 的性能问题也是已知的,我们已经开始做相关的重构和优化,但是 2.5.0 还没有解决 project 的问题,后续版本会有改进。
bai
2021 年9 月 22 日 08:25
12
OK,谢谢答疑,我们就等project得到一定的优化之后,升级尝试吧。
kyle
2021 年9 月 22 日 09:01
13
@bai 可以麻烦您提个 issue 然后把链接贴到这边吗?
wey
2021 年9 月 30 日 03:27
15
system
2021 年10 月 30 日 03:27
16
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。