本文整理自同花顺知识图谱团队在 nMeetup·杭州场的演讲
这次分享主要站在(意向)用户角度讲下技术团队选择数据库产品时,会有哪些考量点。在同花顺知识图谱团队开启知识图谱战略之后,一开始使用的是 Neo4j,但在使用过程中发现随着金融业务的增长,Neo4j 并不能很好地应对增长的业务。所以,技术团队出了一个解决方案:数据库和应用层之间增加多级缓存。虽然缓存能一定程度缓解问题提升性能,但是它其实会引发更多的问题。
于是,我们开始思考有没有一款图数据库能满足目前的业务需求之外,还能应对未来的业务增长。至此,知识图谱团队开始了选型之旅。
如何选图数据库

选型这块,主要分为了:How 怎么选、What 选什么、Why 为什么这三部分内容,此外最后讲述下同花顺这块的知识图谱团队和团队业务。
选型依据这块,主要分为:
- 功能强大:具备极佳的性能
- 商用成熟:产品成熟
- 社区活跃
- 数据量大:能应对目前的业务量,以及未来的业务增长
- 开源优先
- 技术支持
- 国产优先
选图数据库和选股票类似,我们会考虑一些消息面、基本面和技术面,当然二者之间还是有区别的。图数据库的三面主要是下面几点:
- 消息面:是否满足选型依据
- 基本面:是否能够稳定持久
- 技术面:是否达到技术要求
消息面
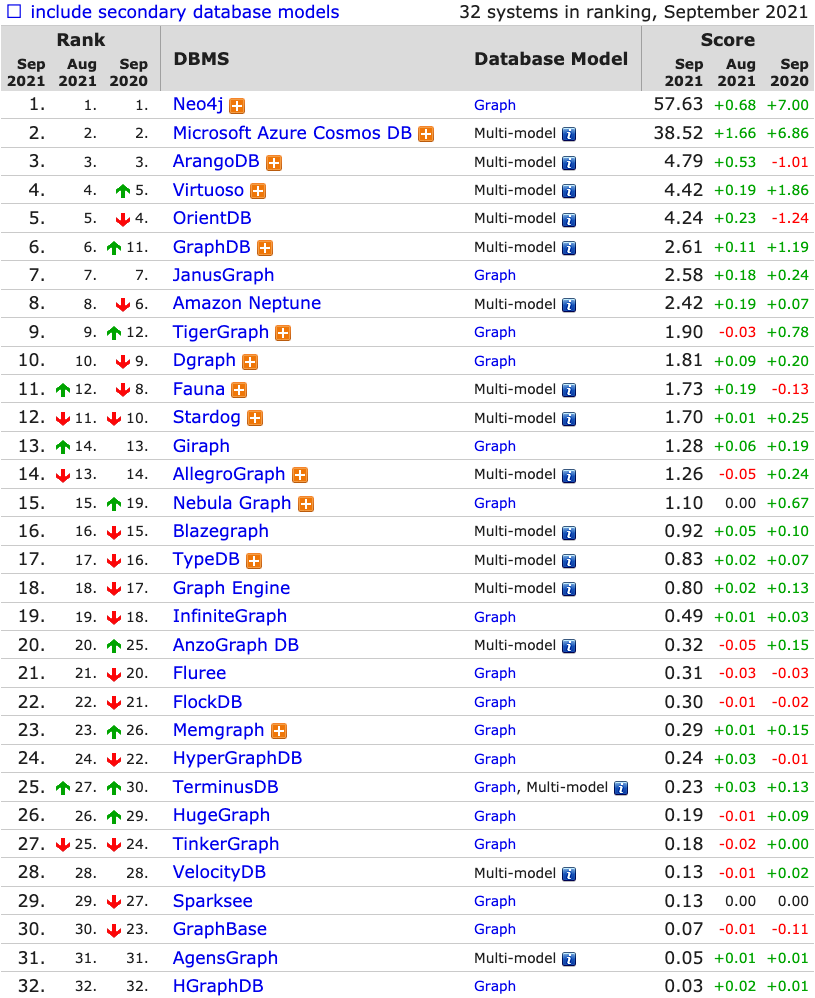
在图数据库消息面这块,一般我们会上一个网站:DB-Engine,可以看到排名第一的是 Neo4j,毕竟是最早的一款图数据库相对成熟。一圈调研下来,发现他们营销做得不错:在百度或者 Google 上面搜索图数据库,就能看到他们的广告。
在这个 DB-Engine 排名上,可以看到其他的像是比较出名的(排名第七)JanusGraph,我们如何在这么多的数据库中确定我们最终使用的数据库呢?

插个题外话,这里说下 DB-Engine 的排名规则,它的排序依据是 Google、Bing 搜索引擎的搜索结果,Google Trends 里的关键词趋势,像 Stack Overflow、DBA Stack Exchange 上的讨论,Indeed 之类的招聘网站的招聘数,Linkedin 里的职位数以及社交网络主要是 Twitter 的讨论量。
我们可以发现一个问题:上面的网站要么是国内无法访问的或者是相对小众的网站。
所以 DB-Engine 上面的排名,对国内的一些产品来说,其实是有失偏颇的,至少它的数据肯定是不能反映它的一些真实情况的。如果考虑到国内的一些使用情况的话,这 DB-Engine 里百度出品的 HugeGraph,以及 Nebula Graph 排名肯定是要上升好多档。
说完 DB-Engine,再说下我们针对 DB-Engine 上的信息做得简单筛选:
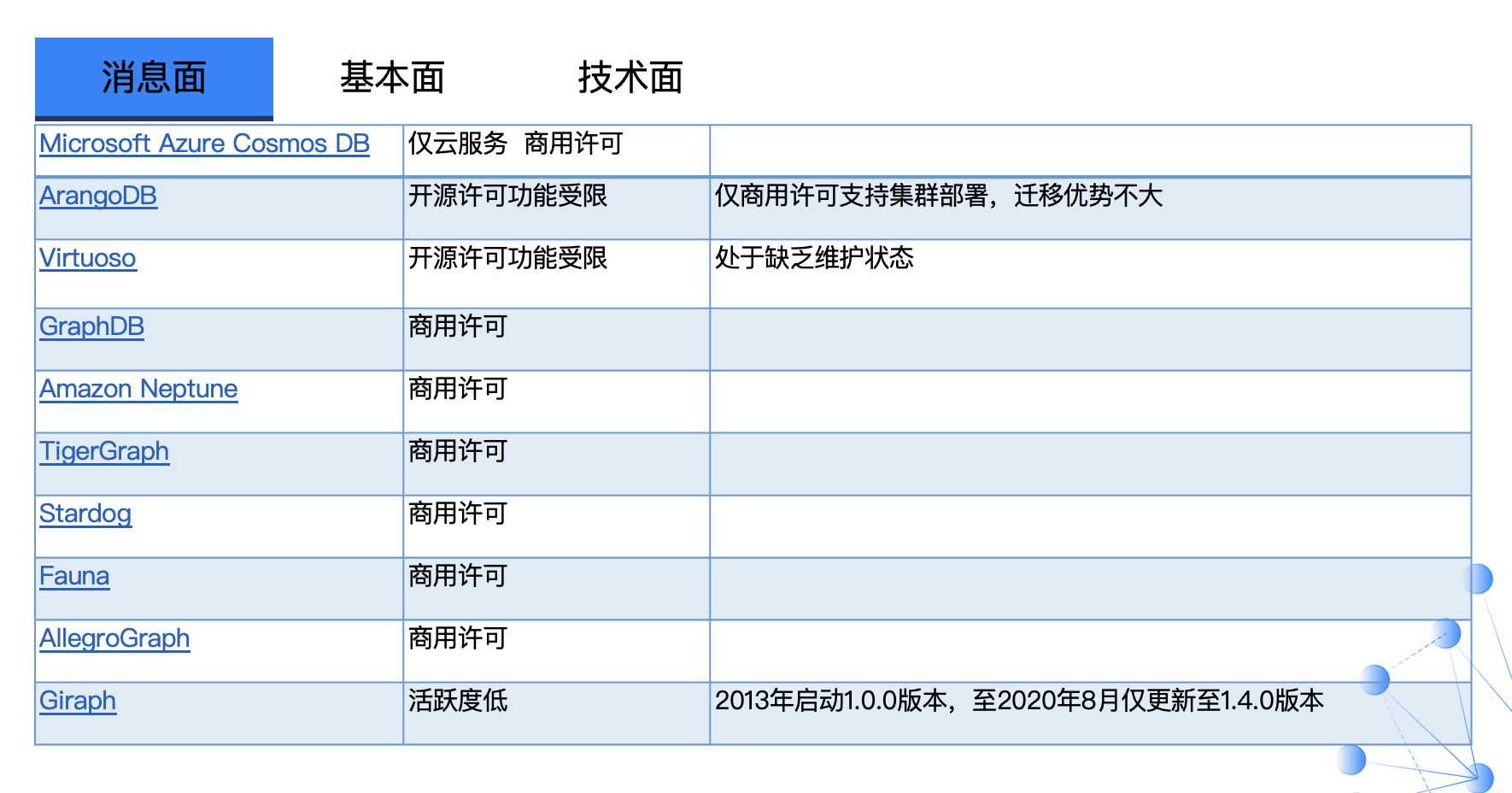
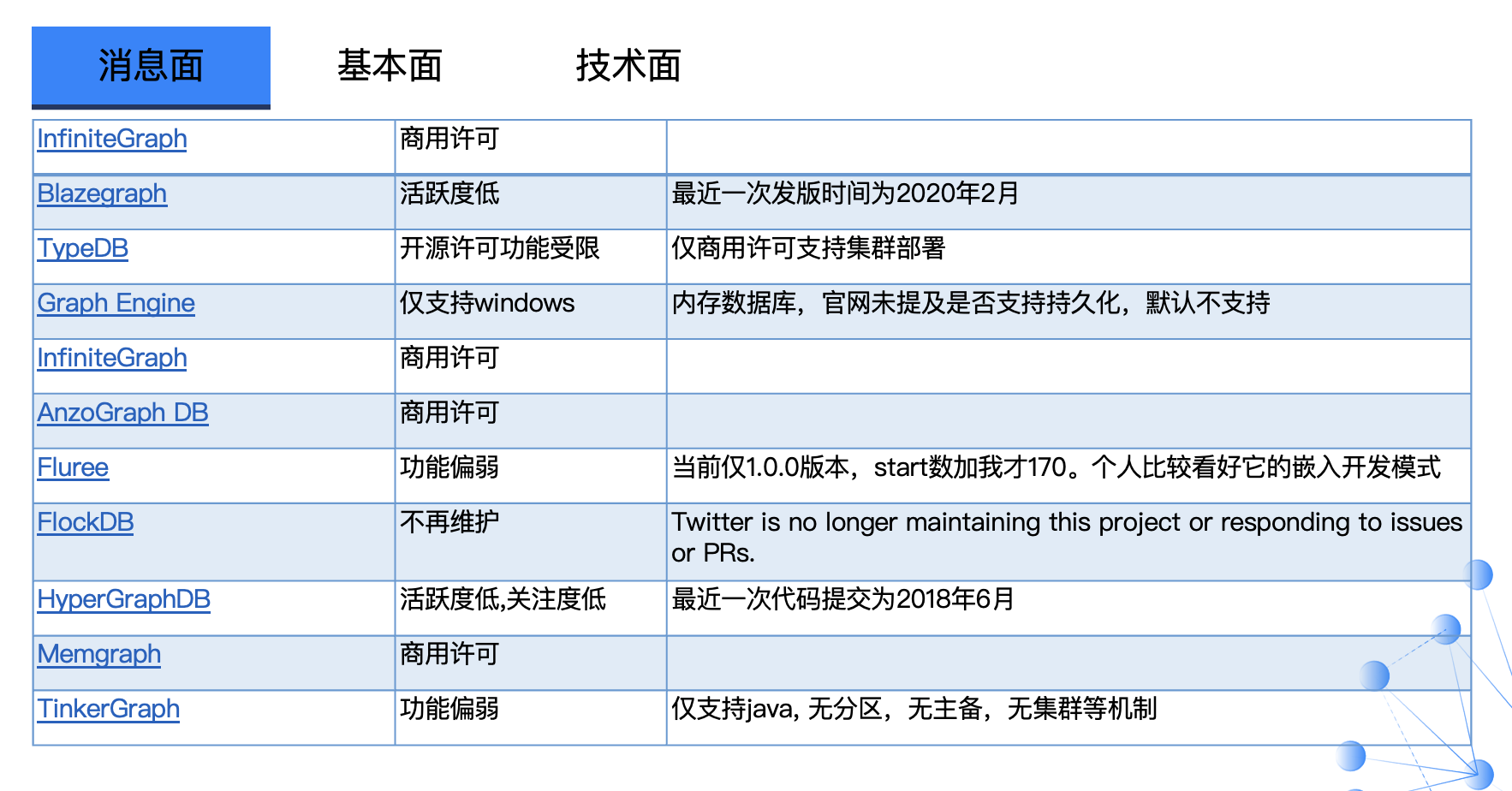
上面这些数据库从消息面上是不满足同花顺知识图谱团队的需求。而这份结果也再次证明了 DB-Engine 的排名结果并非精准,比如:排名在 Nebula Graph 之上的一些数据库已经是一些不活跃、不再更新的产品了。以上截图信息都来源于 DB-Engine 公开信息。
基本面
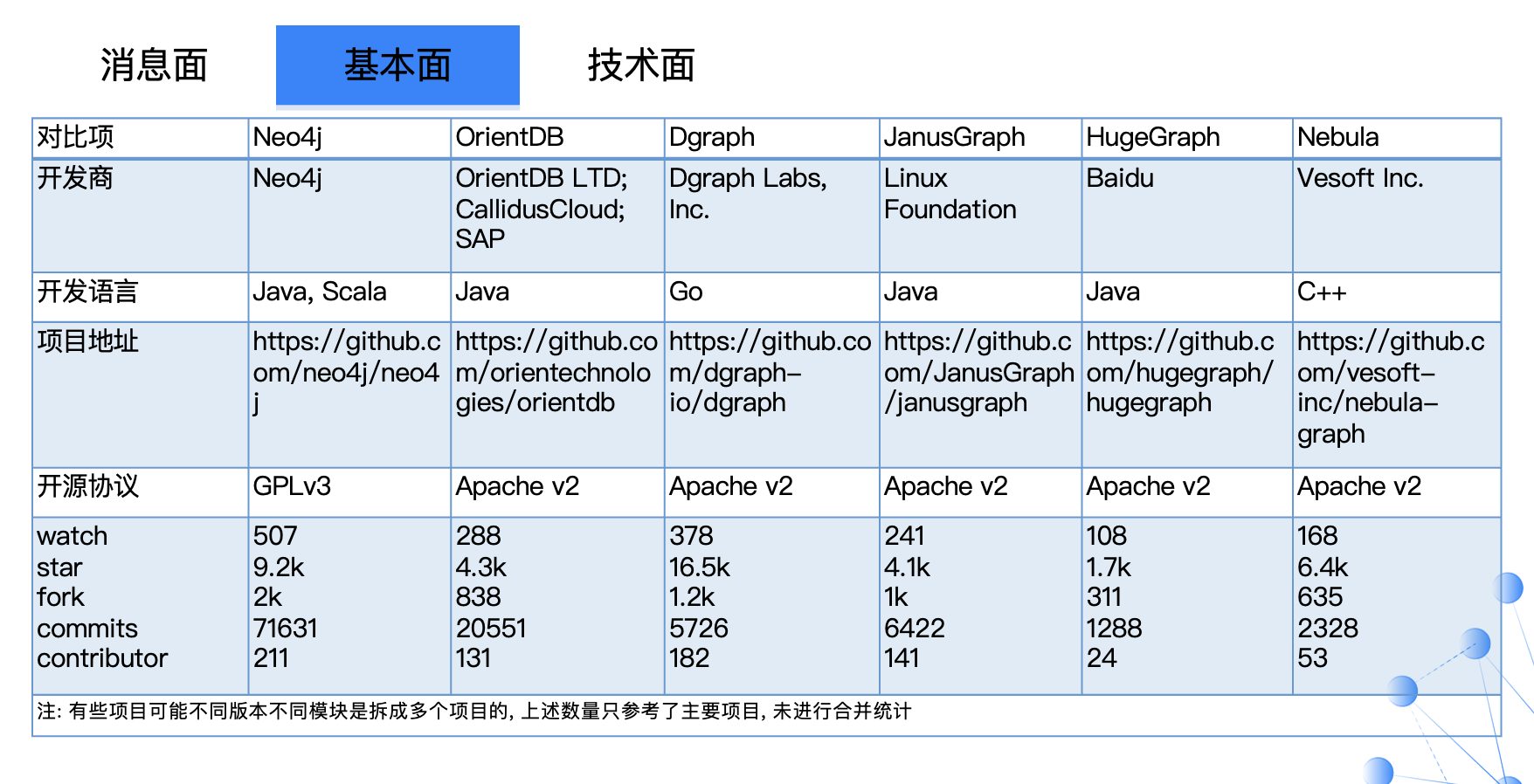

经过消息面之后,我们筛选出了 Neo4j、Orient DB、Dgraph、JanusGraph、HugeGraph、Nebula 等 6 款图数据库产品,这 6 款产品相对活跃,支持多语言。
按照产品的最早发布时间,排在最前面的是 07 年发布的 Neo4j,然后依次是 OrientDB、Dgraph、JanusGraph、HugeGraph,以及 19 年发布的 Nebula Graph。排名越靠前的数据库产品,它的支持语言程度越高,系统功能也会相对更加完善。这块也是“后起之秀”新数据库需要去完善、改进的地方。
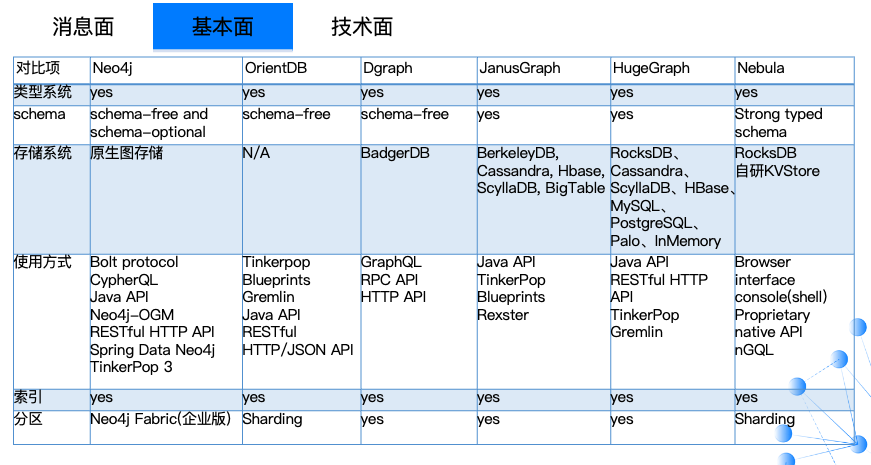
而像 HugeGraph、Neo4j 很多产品功能只是在商业版本(企业版)才会支持,我们还需要了解他们的商用版本内容以及报价。

上面这张图比较有意思,它指出了各类图数据库在不同场景下支持的数量级:比如 Neo4j 是支持十亿的点、万亿的边,毫秒级的响应时间。OrientDB 的数据就比较有意思了,支持无限量级的数据,我不知道它是如何做到这个数值。Dgraph 并没有明确数据量情况,只是说提供了一个 Google 生产级别的数据,支持实时查询,以及 TB 级别的结构化数据。
后面两款一个是百度开源的 HugeGraph,一个 Nebula Graph,Nebula 这边还是比较占优势的——它提供千亿级别、万亿边关系的数据量支持情况。
技术面

经过消息面、基本面,其实没有一个非常明确的胜出者。我们看下技术面这块,由于 HugeGraph 和 JanusGraph 架构类似,OrientDB 技术支持一般,所以在技术面这块我们着重考察:Neo4j、HugeGraph、Nebula Graph 这 3 款图数据库。
Neo4j 只支持同构部署,不支持异构部署,所以不能发挥每台机器的特异性,比如:有的机器它可能是计算型的,有的机器 IO 强,如果按照 Neo4j 的部署设定,这就要求每台机器情况等同。Neo4j 的分析能力和性能提升,主要依靠两个 Fabric 组成的虚拟机提供区域分区能力(上图绿色部分)。
在架构层面,Nebula Graph 和 HugeGraph 的存储计算分离的架构更有优势,至少使用者可以针对业务部门的实际情况搭配机器配置。
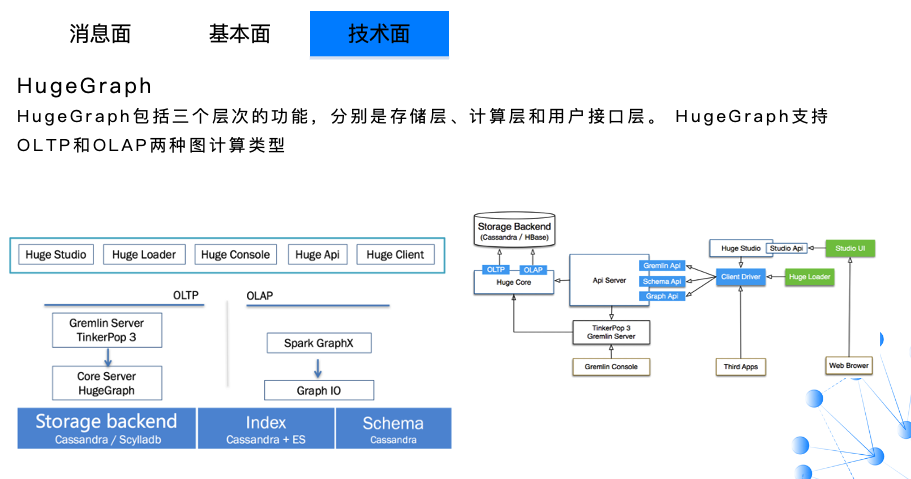
HugeGraph 在存储这块支持多种存储引擎,可对接多种第三方引擎,然后在此基础之上加上了一个计算框架,在计算框架之上是接口层,例如:Huge Console、Huge Loader 等等。
在计算这块,主要基于底部的存储引擎提供了 OLTP 和 OLAP 能力。这里 HugeGraph 的存储引擎不是用自己的存储引擎,主要还是依赖于其他的存储引擎,这里可能不如 Nebula 用自己的存储引擎。举个例子,我们用的第三方存储引擎是 HBase,HBase 的实时性是非常差的,这时候用它做存储引擎就会影响到上一层的性能。
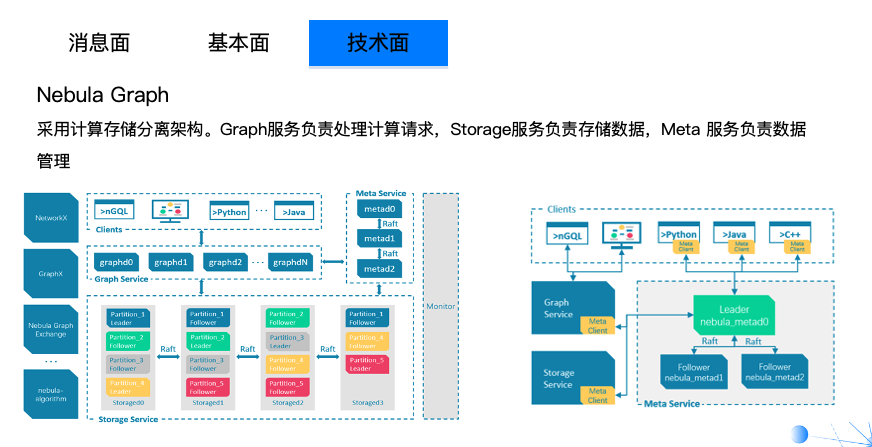
Nebula Graph 这里也是一个存储和计算分离的一个架构,每一层都可无限扩展,你的存储不够就加存储,计算不够就加计算,相对而言还是一个比较先进的架构。
讲完架构之后,同花顺这边参考了其他技术团队的测试结果:
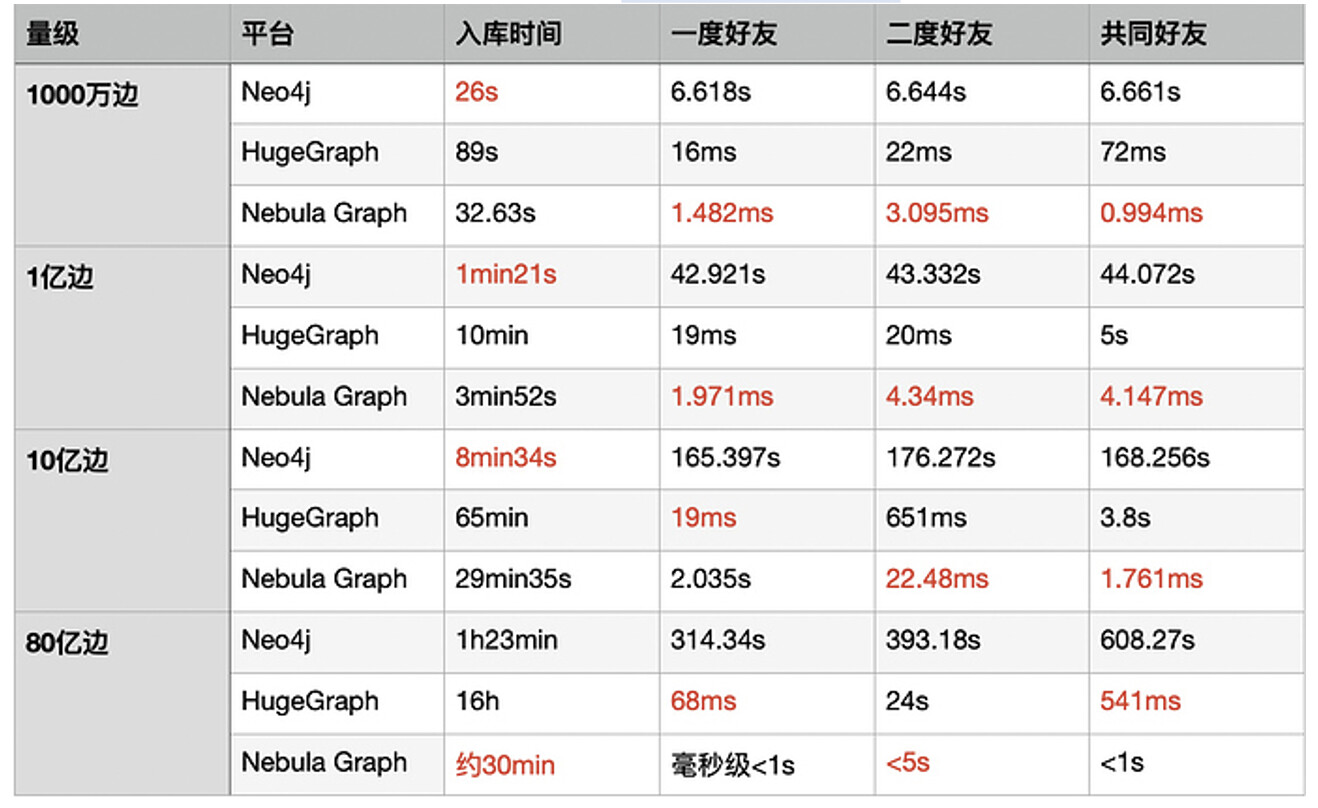
这是腾讯云安全团队在 v1.x 版本的性能测试。
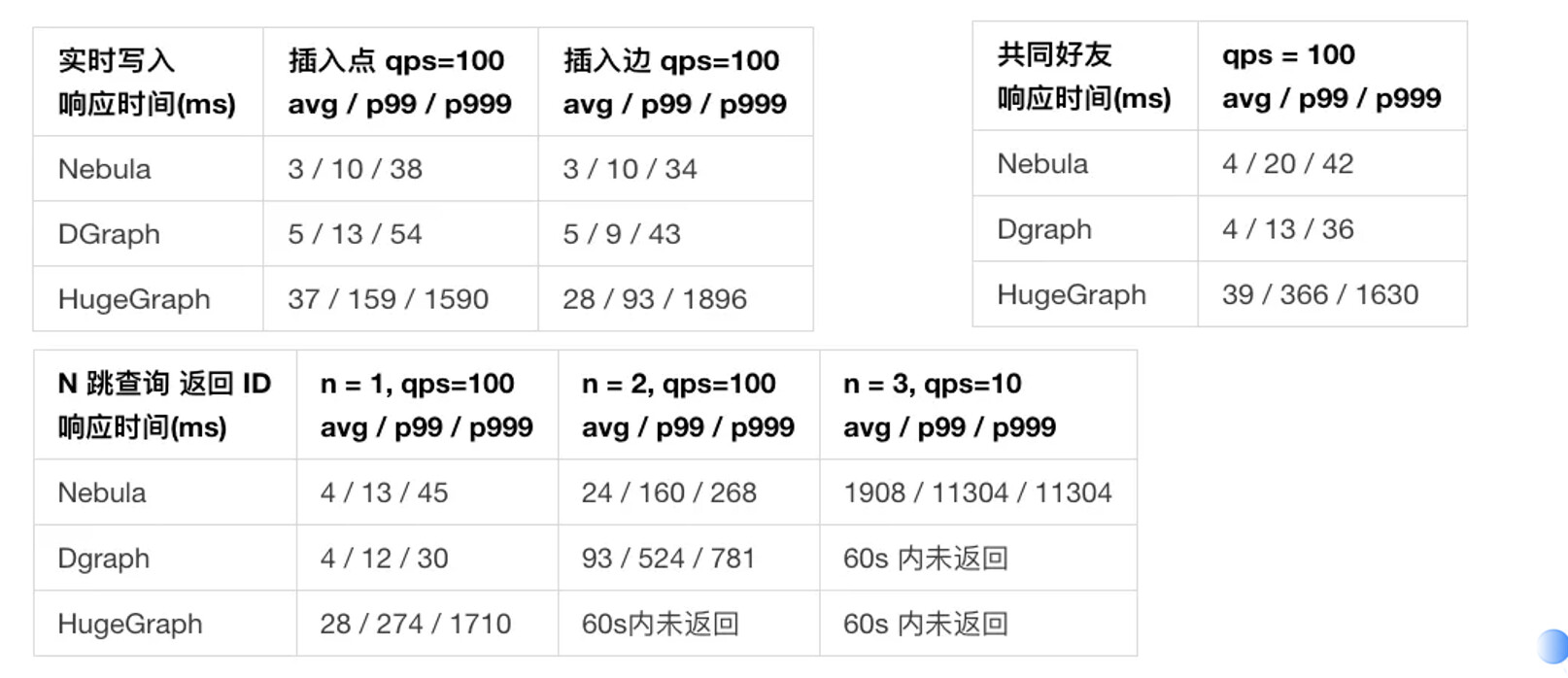
这是美团 NLP 团队做的 Nebula、Dgraph、HugeGraph 的性能对比:在这里,HugeGraph 的存储引擎用的是 HBase,而 Dgraph 和 Nebula Graph 用的是 RocksDB,就像之前说的那样 HBase 在实时性这块是一个短板。如果数据库存储引擎层面,3 个数据库都是用的 KV 存储引擎的话,结果不会产生如此大的一个量级差距;
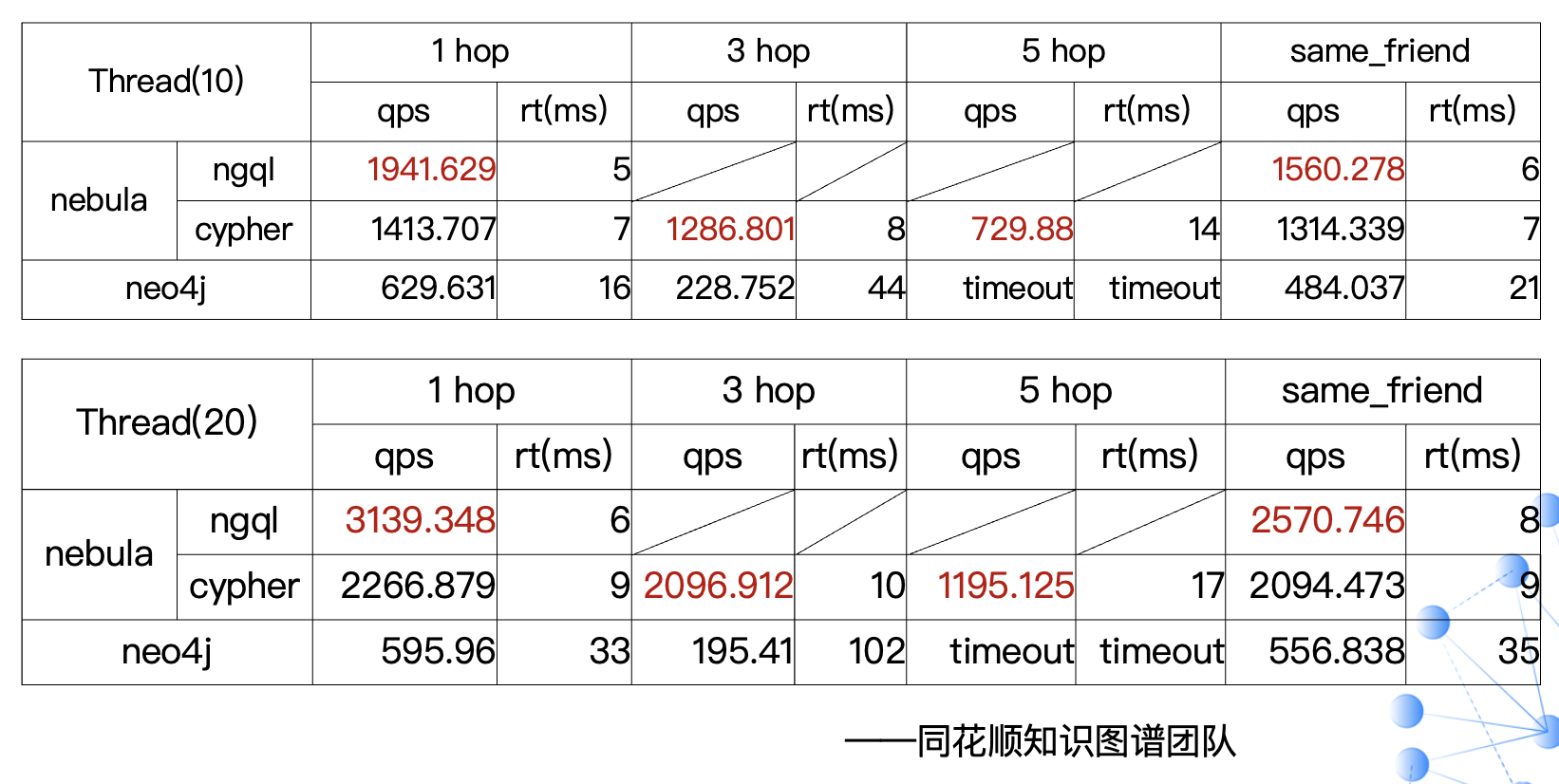
下面是同花顺的一个性能测试结果:我们不仅对比不同图数据库,还对比了 Nebula Graph 两种查询语言(原生 nGQL 和兼容 openCypher 的 nGQL)。
从数据上可以看到原生的查询语言 nGQL 会表现更好点(上图的 nebula-ngql 和 nebula-cypher)。而在多跳查询中,可以看到基本上在 5 跳以上的查询,Neo4j 都是处于一个超时的状态。
在性能上,Nebula 相对 Neo4j 还是有比较大性能优势的。

综合考虑架构、性能、社区支持情况等等因素,我们还是会选择更适合我们的图数据库——Nebula Graph。虽然在使用的过程中发现了一些小问题:
- 不支持中文标识符
- 语法错误提示不友好
- Java 不支持参数化查询
- GO 查询必须指定起点 ID
但,总的来说还是满足我们的业务要求的。
同花顺·知识图谱团队介绍
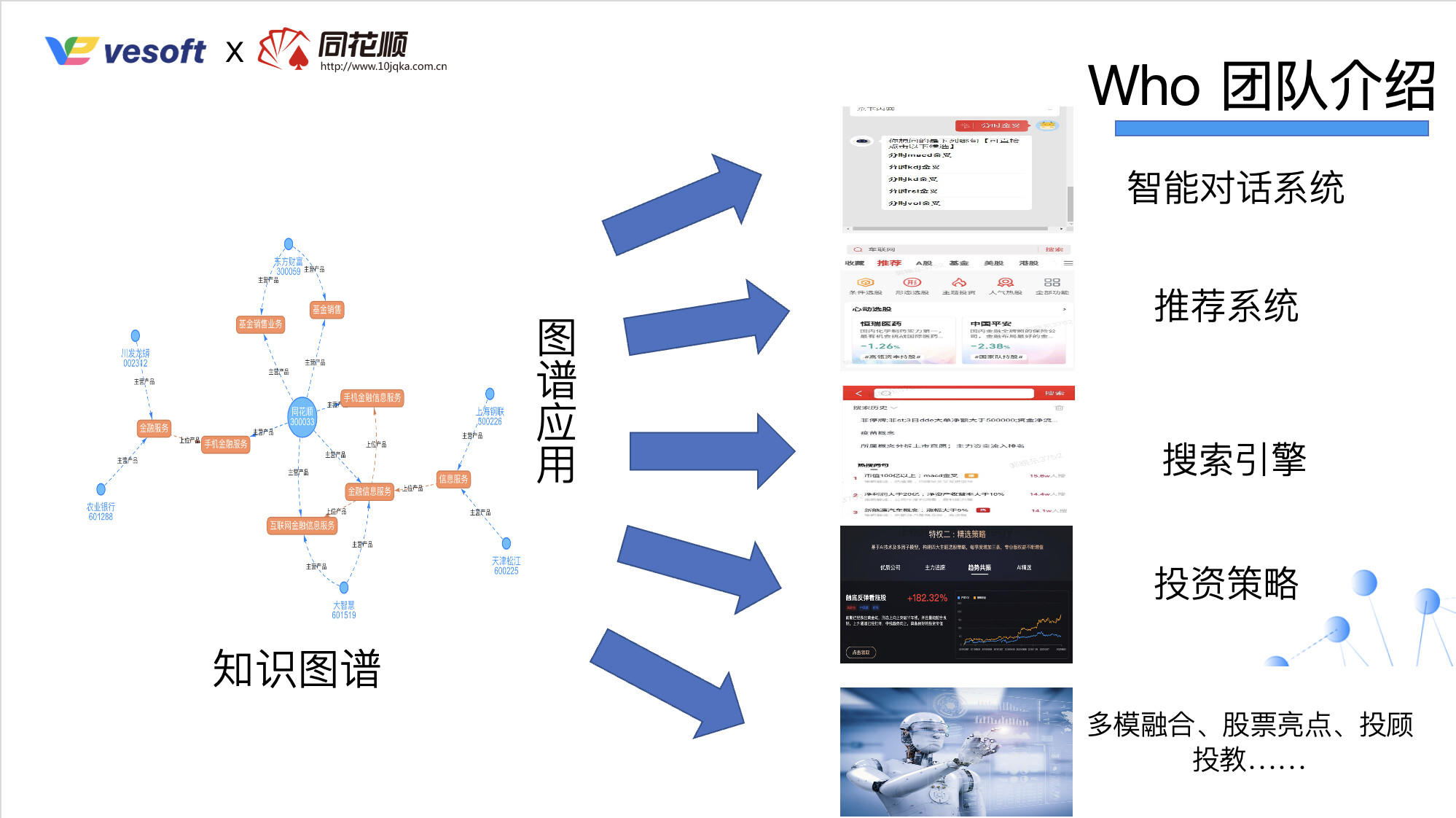
最后来介绍下我们的团队——同花顺知识图谱团队,主要面向的业务是:智能对话、推荐系统、搜索引擎、投资策略以及多模融合、股票亮点、投顾投教这样的一些业务,后面可能接入更多的业务场景。
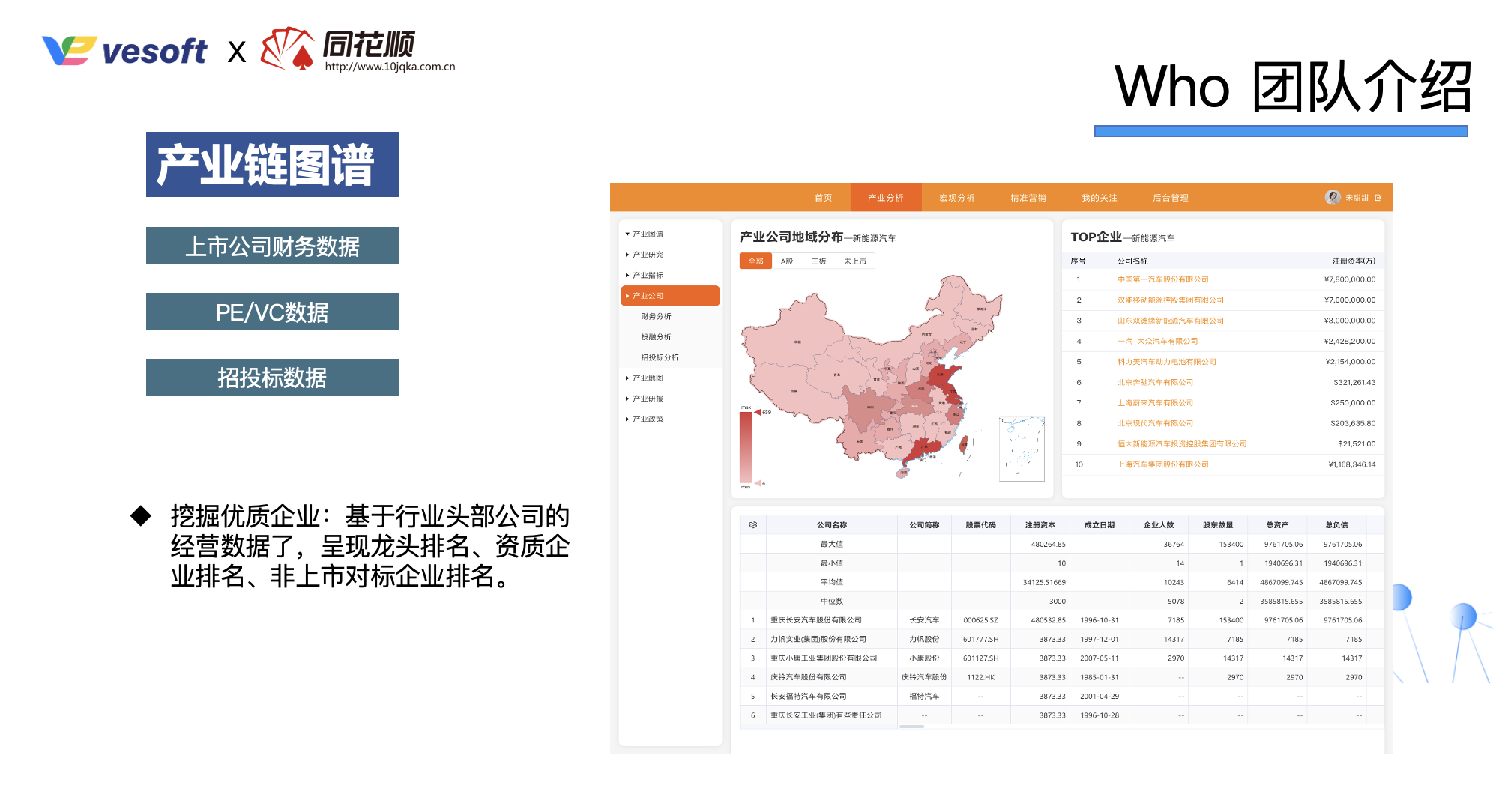
当前我们维护了这么几个图谱,一个是产业链的图谱,就是数据来源于一些公开的数据。通过语义抽取,构建出来的产业链图谱;

还有供应链图谱。

人物关系图谱

以及企业图谱
从而满足同花顺这边金融投资的需求。
交流图数据库技术?报名参与 Nebula 交流会,NUC·2021 报名传送门,我们在北京等你来交流~~
这是一个从 https://nebula-graph.com.cn/posts/reason-to-choose-a-graph-database/ 下的原始话题分离的讨论话题