zjn
1
- nebula 版本:2.0.1
- 部署方式(分布式):
- 是否为线上版本:Y
- 硬件信息
问题描述:
flink程序,拉kafka数据写入nebula集群。
nebula storaged conf配置了rate_limit=20.我手动执行了一次compact操作,用iotop查看磁盘在20M以内;但是flink入库nebula的速度非常慢,正常来说ssd的磁盘20M应该没多少影响,想问下compact操作除了磁盘读写,还有哪些资源是瓶颈?怎么配置可以确保再compact期间尽可能的不影响写入?
zjn
3
配置了磁盘限速,写入速率还是有较大影响,瓶颈有可能再别的方面吗?
读写速率限制为20MB/S。
–rate_limit=20 (in MB/s)
我们内测的时候,importer导入数据的时候磁盘写入可以达到30M,无索引 269016.77 rows/s, 有索引 59050.95 rows/s. 这个地方感觉还可以优化。
另外,建议导入数据时,关闭auto_compact, 当关闭compact时,初始导入性能会提升,但性能可能有衰减,这要看导入的数据量,是否能容忍短暂的性能衰减。
1 个赞
导入的并发线程是多少?导入的过程中CPU能跑满吗?
zjn
6
看了下rocksdb日志,发现出现stalls,这次我的限速是80M,跑满了 有什么优化建议吗?
zjn
7
我这的导入性能比较低好像是rocksdb出现stalls引起的
zjn
8
另外想问下,这个报错是rocksdb stalls期间出的,是因为storaged的写入性能受限引起的吗
这里有份rocksdb团队出的论文,总结了rocksdb多年来实践的经验,也阐述了其中一些不同场景下的负载和取舍。
https://www.usenix.org/system/files/fast21-dong.pdf
我想你关心的部分主要可能在:
- Table 2: System metrics for a typical use case from each
application category.
这个大概可以反映rocksdb在场景下各种资源的配比,仅供参考。
- Table 3: Write amplification, overhead and read I/O for three
major compaction …
我们当前采取Leveling的 Compaction方式(写放大较大),出现stall情况往往就是Compaction速度无法跟上,造成这个的原因也正是写放大(注:一般从L0以下的Compaction是写放大的主要来源)。
至于优化建议,我目前也与@bright-starry-sky意见一致。取决于你的数据量是否可以容忍L0的无限增长,以及读性能的可观降低。
我们会综合评估当前各种场景的需求,以规划减少导入过程中的资源开销,或许你可以把你场景的经验和经历更新在这里,帮助我们。
2 个赞
zjn
10
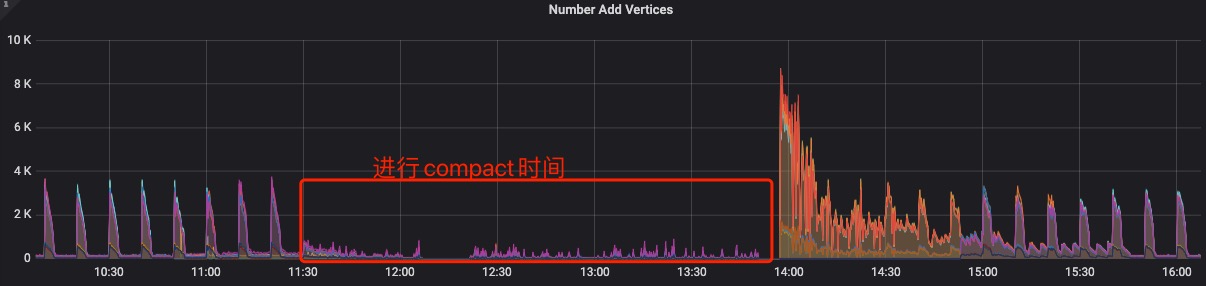
好的,我们的场景是 nebula库作为OLTP,数据需要实时入库, 可能是由于生产上有大量ttl数据,磁盘占用量过大,自动的compact并不能减少太多存储,需要手动compact(手动compact完能释放掉近一半空间)。
但再compact期间,数据还是会实时入库,怎样减少compact对入库的影响?
昨天和今天的测试发现,现在的问题应该是:我再rocksdb设置的磁盘限速80M,被flush和compact跑满了(如我截图的High和Low), 导致rocksdb stalls,写入被rocksdb限速
我会再做一些尝试,调整磁盘限速、调整放大比之类的,尽量减少compact期间对写入的影响。
另外,如果还有其他影响的参数,请告知
zjn
11
还有,有个小问题,compact完之后,leader会重新随机分配,还需要做下balance leader
system
关闭
13
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。