-
nebula 版本:2.5.1
-
部署方式(分布式 / 单机 / Docker / DBaaS):单机
-
是否为线上版本:N
-
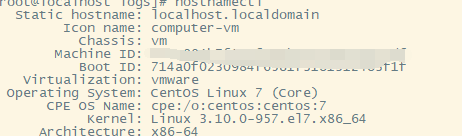
硬件信息
机器信息
内存状态
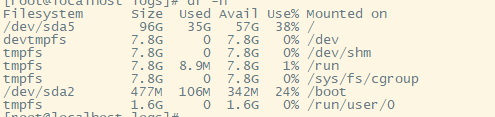
磁盘信息
-
问题的具体描述
查询的数据量:点的数量为 10000 个,边的数量为 13786480 条
执行的语句

match (v:user{name:"尔冬升"})<--(v2)<--(v3) return v2;
发生的问题:
执行语句后,内存变化如下
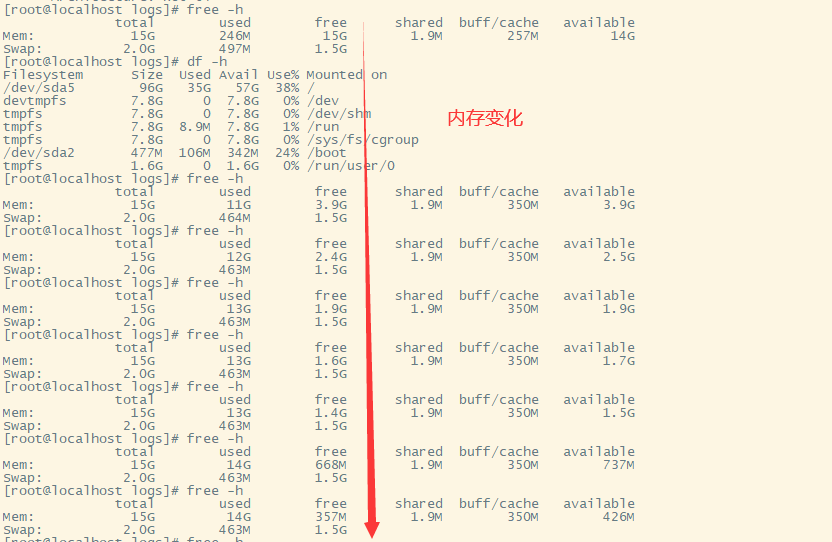
内存过大,超过设置的阈值,然后查看服务状态

nebula-graphd服务挂掉
 就是感觉有点奇怪,如果你就想体验下 demo 的话,我们有 playground 你可以去试玩下:
就是感觉有点奇怪,如果你就想体验下 demo 的话,我们有 playground 你可以去试玩下: