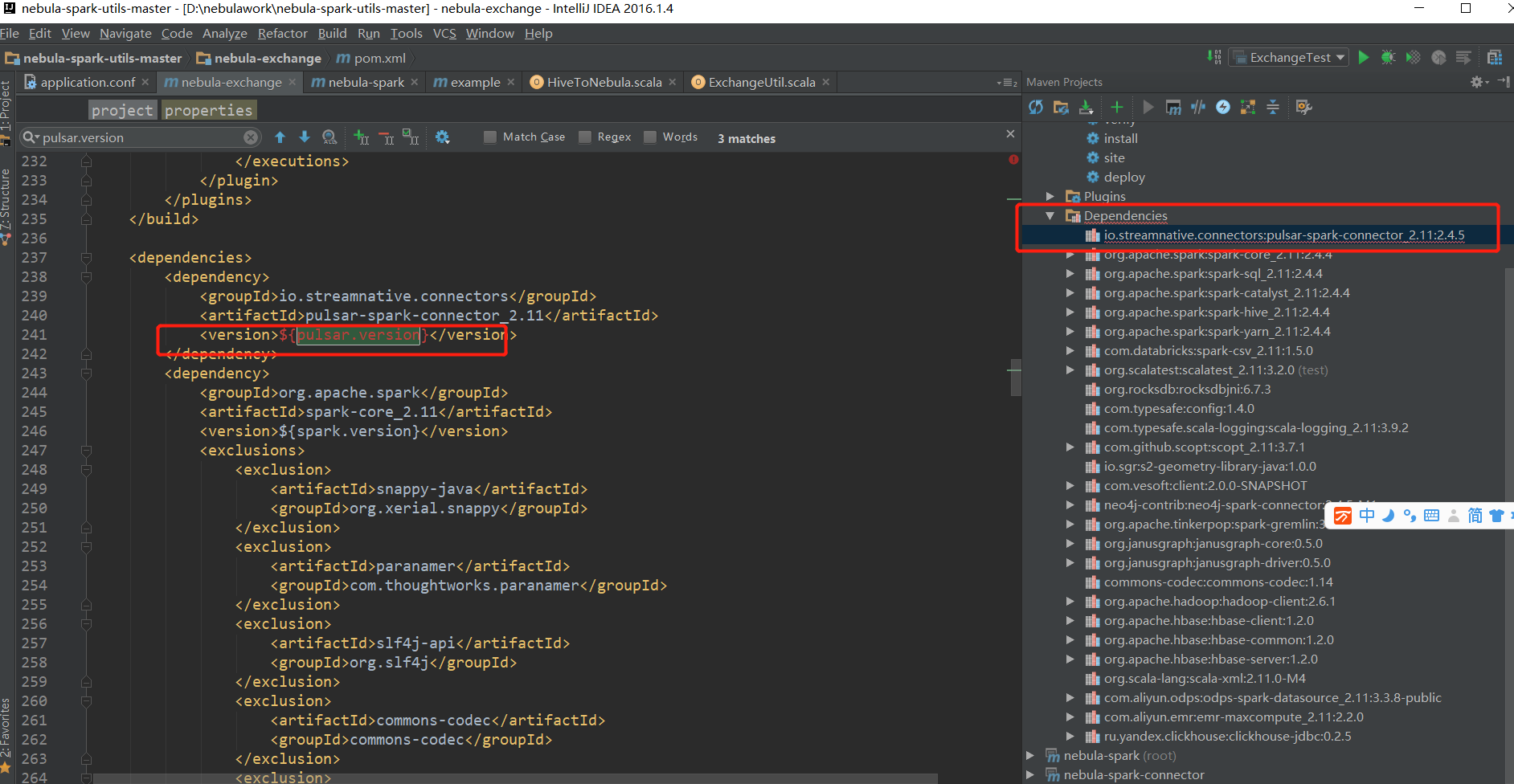
一:问题描述,本地程序读取远程HIVE库数据时报错。本地和HIVE库网络通,MYSQL存储HIVE元数据正确,程序走到 session.sql(sentence) 这步报错。
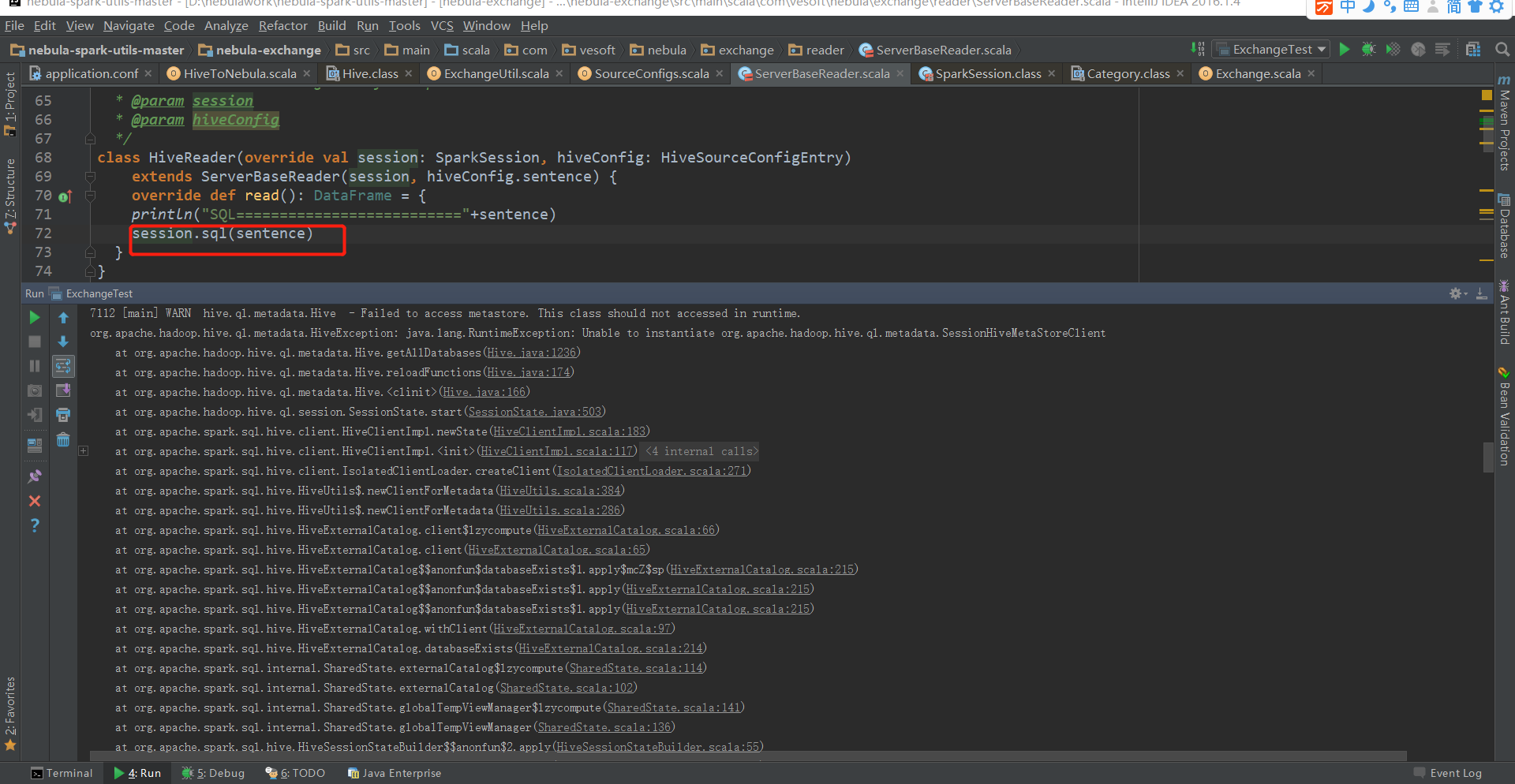
代码:
package com.vesoft.nebula.exchange.reader
class HiveReader(override val session: SparkSession, hiveConfig: HiveSourceConfigEntry)
extends ServerBaseReader(session, hiveConfig.sentence) {
override def read(): DataFrame = {
println("SQL=========================="+sentence)
**session.sql(sentence)**
}
}
日志打印:
SQL==========================select sid,age,name from hivetest.students
5219 [main] INFO org.apache.spark.sql.internal.SharedState - Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir ('hdfs://192.168.43.134:9000/user/hive/warehouse/').
5219 [main] INFO org.apache.spark.sql.internal.SharedState - Warehouse path is 'hdfs://192.168.43.134:9000/user/hive/warehouse/'.
5229 [main] INFO org.spark_project.jetty.server.handler.ContextHandler - Started o.s.j.s.ServletContextHandler@3f92c349{/SQL,null,AVAILABLE,@Spark}
5229 [main] INFO org.spark_project.jetty.server.handler.ContextHandler - Started o.s.j.s.ServletContextHandler@769a58e5{/SQL/json,null,AVAILABLE,@Spark}
5230 [main] INFO org.spark_project.jetty.server.handler.ContextHandler - Started o.s.j.s.ServletContextHandler@66ba7e45{/SQL/execution,null,AVAILABLE,@Spark}
5230 [main] INFO org.spark_project.jetty.server.handler.ContextHandler - Started o.s.j.s.ServletContextHandler@70e02081{/SQL/execution/json,null,AVAILABLE,@Spark}
5232 [main] INFO org.spark_project.jetty.server.handler.ContextHandler - Started o.s.j.s.ServletContextHandler@cb0f763{/static/sql,null,AVAILABLE,@Spark}
5816 [main] INFO org.apache.spark.sql.execution.streaming.state.StateStoreCoordinatorRef - Registered StateStoreCoordinator endpoint
6318 [main] INFO org.apache.spark.sql.hive.HiveUtils - Initializing HiveMetastoreConnection version 1.2.1 using Spark classes.
7092 [main] INFO org.apache.hadoop.hive.metastore.HiveMetaStore - 0: Opening raw store with implemenation class:org.apache.hadoop.hive.metastore.ObjectStore
7112 [main] WARN hive.ql.metadata.Hive - Failed to access metastore. This class should not accessed in runtime.
org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.ql.metadata.Hive.getAllDatabases(Hive.java:1236)
at org.apache.hadoop.hive.ql.metadata.Hive.reloadFunctions(Hive.java:174)
at org.apache.hadoop.hive.ql.metadata.Hive.<clinit>(Hive.java:166)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:503)
at org.apache.spark.sql.hive.client.HiveClientImpl.newState(HiveClientImpl.scala:183)
at org.apache.spark.sql.hive.client.HiveClientImpl.<init>(HiveClientImpl.scala:117)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.spark.sql.hive.client.IsolatedClientLoader.createClient(IsolatedClientLoader.scala:271)
at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:384)
at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:286)
at org.apache.spark.sql.hive.HiveExternalCatalog.client$lzycompute(HiveExternalCatalog.scala:66)
at org.apache.spark.sql.hive.HiveExternalCatalog.client(HiveExternalCatalog.scala:65)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply$mcZ$sp(HiveExternalCatalog.scala:215)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:215)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:215)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:97)
at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:214)
at org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:114)
at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:102)
at org.apache.spark.sql.internal.SharedState.globalTempViewManager$lzycompute(SharedState.scala:141)
at org.apache.spark.sql.internal.SharedState.globalTempViewManager(SharedState.scala:136)
at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anonfun$2.apply(HiveSessionStateBuilder.scala:55)
at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anonfun$2.apply(HiveSessionStateBuilder.scala:55)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.globalTempViewManager$lzycompute(SessionCatalog.scala:91)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.globalTempViewManager(SessionCatalog.scala:91)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.isTemporaryTable(SessionCatalog.scala:736)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.isRunningDirectlyOnFiles(Analyzer.scala:747)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.resolveRelation(Analyzer.scala:681)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$$anonfun$apply$8.applyOrElse(Analyzer.scala:713)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$$anonfun$apply$8.applyOrElse(Analyzer.scala:706)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1$$anonfun$apply$1.apply(AnalysisHelper.scala:90)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1$$anonfun$apply$1.apply(AnalysisHelper.scala:90)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1.apply(AnalysisHelper.scala:89)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1.apply(AnalysisHelper.scala:86)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:194)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$class.resolveOperatorsUp(AnalysisHelper.scala:86)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsUp(LogicalPlan.scala:29)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1$$anonfun$1.apply(AnalysisHelper.scala:87)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1$$anonfun$1.apply(AnalysisHelper.scala:87)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$4.apply(TreeNode.scala:329)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:187)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:327)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1.apply(AnalysisHelper.scala:87)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1.apply(AnalysisHelper.scala:86)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:194)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$class.resolveOperatorsUp(AnalysisHelper.scala:86)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsUp(LogicalPlan.scala:29)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.apply(Analyzer.scala:706)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.apply(Analyzer.scala:652)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:87)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:84)
at scala.collection.LinearSeqOptimized$class.foldLeft(LinearSeqOptimized.scala:124)
at scala.collection.immutable.List.foldLeft(List.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:76)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:76)
at org.apache.spark.sql.catalyst.analysis.Analyzer.org$apache$spark$sql$catalyst$analysis$Analyzer$$executeSameContext(Analyzer.scala:127)
at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:121)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:106)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:105)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:201)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:105)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:57)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:55)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:47)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:78)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:642)
at com.vesoft.nebula.exchange.reader.HiveReader.read(ServerBaseReader.scala:72)
at com.vesoft.nebula.exchange.ExchangeUtil$.com$vesoft$nebula$exchange$ExchangeUtil$$createDataSource(ExchangeUtil.scala:234)
at com.vesoft.nebula.exchange.ExchangeUtil$$anonfun$importData$1.apply(ExchangeUtil.scala:120)
at com.vesoft.nebula.exchange.ExchangeUtil$$anonfun$importData$1.apply(ExchangeUtil.scala:106)
at scala.collection.immutable.List.foreach(List.scala:392)
at com.vesoft.nebula.exchange.ExchangeUtil$.importData(ExchangeUtil.scala:106)
at com.vesoft.nebula.exchange.HiveToNebula$.hiveDataImport(HiveToNebula.scala:24)
at com.vesoft.nebula.exchange.HiveToNebula$.main(HiveToNebula.scala:10)
at com.vesoft.nebula.exchange.HiveToNebula.main(HiveToNebula.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)
Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1523)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:86)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:132)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:104)
at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:3005)
at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:3024)
at org.apache.hadoop.hive.ql.metadata.Hive.getAllDatabases(Hive.java:1234)
... 85 more
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1521)
... 91 more
Caused by: java.lang.NoClassDefFoundError: org/antlr/runtime/RecognitionException
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.hadoop.hive.metastore.MetaStoreUtils.getClass(MetaStoreUtils.java:1489)
at org.apache.hadoop.hive.metastore.RawStoreProxy.getProxy(RawStoreProxy.java:63)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.newRawStore(HiveMetaStore.java:593)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.getMS(HiveMetaStore.java:571)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.createDefaultDB(HiveMetaStore.java:620)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.init(HiveMetaStore.java:461)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.<init>(RetryingHMSHandler.java:66)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.getProxy(RetryingHMSHandler.java:72)
at org.apache.hadoop.hive.metastore.HiveMetaStore.newRetryingHMSHandler(HiveMetaStore.java:5762)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.<init>(HiveMetaStoreClient.java:199)
at org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient.<init>(SessionHiveMetaStoreClient.java:74)
... 96 more
Caused by: java.lang.ClassNotFoundException: org.antlr.runtime.RecognitionException
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at org.apache.spark.sql.hive.client.IsolatedClientLoader$$anon$1.doLoadClass(IsolatedClientLoader.scala:226)
at org.apache.spark.sql.hive.client.IsolatedClientLoader$$anon$1.loadClass(IsolatedClientLoader.scala:215)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 109 more
7121 [main] INFO org.apache.hadoop.hive.metastore.HiveMetaStore - 0: Opening raw store with implemenation class:org.apache.hadoop.hive.metastore.ObjectStore
Exception in thread "main" org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient;
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:106)
at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:214)
at org.apache.spark.sql.internal.SharedState.externalCatalog$lzycompute(SharedState.scala:114)
at org.apache.spark.sql.internal.SharedState.externalCatalog(SharedState.scala:102)
at org.apache.spark.sql.internal.SharedState.globalTempViewManager$lzycompute(SharedState.scala:141)
at org.apache.spark.sql.internal.SharedState.globalTempViewManager(SharedState.scala:136)
at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anonfun$2.apply(HiveSessionStateBuilder.scala:55)
at org.apache.spark.sql.hive.HiveSessionStateBuilder$$anonfun$2.apply(HiveSessionStateBuilder.scala:55)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.globalTempViewManager$lzycompute(SessionCatalog.scala:91)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.globalTempViewManager(SessionCatalog.scala:91)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.isTemporaryTable(SessionCatalog.scala:736)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.isRunningDirectlyOnFiles(Analyzer.scala:747)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.resolveRelation(Analyzer.scala:681)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$$anonfun$apply$8.applyOrElse(Analyzer.scala:713)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$$anonfun$apply$8.applyOrElse(Analyzer.scala:706)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1$$anonfun$apply$1.apply(AnalysisHelper.scala:90)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1$$anonfun$apply$1.apply(AnalysisHelper.scala:90)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1.apply(AnalysisHelper.scala:89)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1.apply(AnalysisHelper.scala:86)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:194)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$class.resolveOperatorsUp(AnalysisHelper.scala:86)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsUp(LogicalPlan.scala:29)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1$$anonfun$1.apply(AnalysisHelper.scala:87)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1$$anonfun$1.apply(AnalysisHelper.scala:87)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$4.apply(TreeNode.scala:329)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:187)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:327)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1.apply(AnalysisHelper.scala:87)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveOperatorsUp$1.apply(AnalysisHelper.scala:86)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:194)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$class.resolveOperatorsUp(AnalysisHelper.scala:86)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsUp(LogicalPlan.scala:29)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.apply(Analyzer.scala:706)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.apply(Analyzer.scala:652)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:87)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:84)
at scala.collection.LinearSeqOptimized$class.foldLeft(LinearSeqOptimized.scala:124)
at scala.collection.immutable.List.foldLeft(List.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:76)
at scala.collection.immutable.List.foreach(List.scala:392)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:76)
at org.apache.spark.sql.catalyst.analysis.Analyzer.org$apache$spark$sql$catalyst$analysis$Analyzer$$executeSameContext(Analyzer.scala:127)
at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:121)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:106)
at org.apache.spark.sql.catalyst.analysis.Analyzer$$anonfun$executeAndCheck$1.apply(Analyzer.scala:105)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:201)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:105)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:57)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:55)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:47)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:78)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:642)
at com.vesoft.nebula.exchange.reader.HiveReader.read(ServerBaseReader.scala:72)
at com.vesoft.nebula.exchange.ExchangeUtil$.com$vesoft$nebula$exchange$ExchangeUtil$$createDataSource(ExchangeUtil.scala:234)
at com.vesoft.nebula.exchange.ExchangeUtil$$anonfun$importData$1.apply(ExchangeUtil.scala:120)
at com.vesoft.nebula.exchange.ExchangeUtil$$anonfun$importData$1.apply(ExchangeUtil.scala:106)
at scala.collection.immutable.List.foreach(List.scala:392)
at com.vesoft.nebula.exchange.ExchangeUtil$.importData(ExchangeUtil.scala:106)
at com.vesoft.nebula.exchange.HiveToNebula$.hiveDataImport(HiveToNebula.scala:24)
at com.vesoft.nebula.exchange.HiveToNebula$.main(HiveToNebula.scala:10)
at com.vesoft.nebula.exchange.HiveToNebula.main(HiveToNebula.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)
Caused by: java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:522)
at org.apache.spark.sql.hive.client.HiveClientImpl.newState(HiveClientImpl.scala:183)
at org.apache.spark.sql.hive.client.HiveClientImpl.<init>(HiveClientImpl.scala:117)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.spark.sql.hive.client.IsolatedClientLoader.createClient(IsolatedClientLoader.scala:271)
at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:384)
at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:286)
at org.apache.spark.sql.hive.HiveExternalCatalog.client$lzycompute(HiveExternalCatalog.scala:66)
at org.apache.spark.sql.hive.HiveExternalCatalog.client(HiveExternalCatalog.scala:65)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply$mcZ$sp(HiveExternalCatalog.scala:215)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:215)
at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:215)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:97)
... 67 more
Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1523)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:86)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:132)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:104)
at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:3005)
at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:3024)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:503)
... 82 more
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1521)
... 88 more
Caused by: java.lang.NoClassDefFoundError: org/antlr/runtime/RecognitionException
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.hadoop.hive.metastore.MetaStoreUtils.getClass(MetaStoreUtils.java:1489)
at org.apache.hadoop.hive.metastore.RawStoreProxy.getProxy(RawStoreProxy.java:63)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.newRawStore(HiveMetaStore.java:593)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.getMS(HiveMetaStore.java:571)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.createDefaultDB(HiveMetaStore.java:620)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.init(HiveMetaStore.java:461)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.<init>(RetryingHMSHandler.java:66)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.getProxy(RetryingHMSHandler.java:72)
at org.apache.hadoop.hive.metastore.HiveMetaStore.newRetryingHMSHandler(HiveMetaStore.java:5762)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.<init>(HiveMetaStoreClient.java:199)
at org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient.<init>(SessionHiveMetaStoreClient.java:74)
... 93 more
Caused by: java.lang.ClassNotFoundException: org.antlr.runtime.RecognitionException
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at org.apache.spark.sql.hive.client.IsolatedClientLoader$$anon$1.doLoadClass(IsolatedClientLoader.scala:226)
at org.apache.spark.sql.hive.client.IsolatedClientLoader$$anon$1.loadClass(IsolatedClientLoader.scala:215)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 106 more
7136 [Thread-1] INFO org.apache.spark.SparkContext - Invoking stop() from shutdown hook
7144 [Thread-1] INFO org.spark_project.jetty.server.AbstractConnector - Stopped Spark@aa5455e{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
7146 [Thread-1] INFO org.apache.spark.ui.SparkUI - Stopped Spark web UI at http://zanjw:4040
7157 [dispatcher-event-loop-1] INFO org.apache.spark.MapOutputTrackerMasterEndpoint - MapOutputTrackerMasterEndpoint stopped!
7168 [Thread-1] INFO org.apache.spark.storage.memory.MemoryStore - MemoryStore cleared
7168 [Thread-1] INFO org.apache.spark.storage.BlockManager - BlockManager stopped
7174 [Thread-1] INFO org.apache.spark.storage.BlockManagerMaster - BlockManagerMaster stopped
7177 [dispatcher-event-loop-0] INFO org.apache.spark.scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint - OutputCommitCoordinator stopped!
7185 [Thread-1] INFO org.apache.spark.SparkContext - Successfully stopped SparkContext
7186 [Thread-1] INFO org.apache.spark.util.ShutdownHookManager - Shutdown hook called
7186 [Thread-1] INFO org.apache.spark.util.ShutdownHookManager - Deleting directory C:\Users\zanjw\AppData\Local\Temp\spark-a1165ed8-0e4c-4b47-b11f-ec3428981d63
Process finished with exit code 1
二 配置文件:application.conf
{
# Spark relation config
spark: {
app: {
name: Nebula Exchange 2.0
}
master:local
driver: {
cores: 1
maxResultSize: 1G
}
executor: {
memory:1G
}
cores:{
max: 16
}
}
# if the hive is hive-on-spark with derby mode, you can ignore this hive configure
# get the config values from file $HIVE_HOME/conf/hive-site.xml or hive-default.xml
# hive: {
# warehouse: "hdfs://NAMENODE_IP:9000/apps/svr/hive-xxx/warehouse/"
# connectionURL: "jdbc:mysql://your_ip:3306/hive_spark?characterEncoding=UTF-8"
# connectionDriverName: "com.mysql.jdbc.Driver"
# connectionUserName: "user"
# connectionPassword: "password"
# }
hive: {
warehouse: "hdfs://192.168.43.134:9000/user/hive/warehouse/"
connectionURL: "jdbc:mysql://192.168.43.134:3306/hive_spark?characterEncoding=UTF-8"
connectionDriverName: "com.mysql.jdbc.Driver"
connectionUserName: "root"
connectionPassword: "123456"
}
# Nebula Graph relation config
nebula: {
address:{
graph:["192.168.43.133:9669"]
meta:["192.168.43.133:9559"]
}
user: root
pswd: nebula
space: hivetest
# parameters for SST import, not required
# path:{
# local:"/tmp"
# remote:"/sst"
# hdfs.namenode: "hdfs://name_node:9000"
# }
# nebula client connection parameters
connection {
# socket connect & execute timeout, unit: millisecond
timeout: 30000
}
error: {
# max number of failures, if the number of failures is bigger than max, then exit the application.
max: 32
# failed import job will be recorded in output path
output: /tmp/errors
}
# use google's RateLimiter to limit the requests send to NebulaGraph
rate: {
# the stable throughput of RateLimiter
limit: 1024
# Acquires a permit from RateLimiter, unit: MILLISECONDS
# if it can't be obtained within the specified timeout, then give up the request.
timeout: 1000
}
}
# 处理点
tags: [
# 设置Tag player相关信息。
{
# Nebula Graph中对应的Tag名称。
name: students
type: {
# 指定数据源文件格式,设置为hive。
source: hive
# 指定如何将点数据导入Nebula Graph:Client或SST。
sink: client
}
# 设置读取数据库basketball中player表数据的SQL语句
exec: "select sid,age,name from hivetest.students"
# 在fields里指定player表中的列名称,其对应的value会作为Nebula Graph中指定属性。
# fields和nebula.fields里的配置必须一一对应。
# 如果需要指定多个列名称,用英文逗号(,)隔开。
fields: [age,name]
nebula.fields: [age,name]
# 指定表中某一列数据为Nebula Graph中点VID的来源。
vertex:{
field:sid
}
# 单批次写入 Nebula Graph 的最大数据条数。
batch: 256
# Spark 分区数量
partition: 32
}
# 设置Tag 学校相关信息。
{
name: schools
type: {
source: hive
sink: client
}
exec: "select school_id,school_name from hivetest.schools"
fields: [school_name]
nebula.fields: [school_name]
vertex: {
field: school_id
}
batch: 256
partition: 32
}
]
# 处理边数据
edges: [
# 设置Edge type follow相关信息
{
# Nebula Graph中对应的Edge type名称。
name: relations
type: {
# 指定数据源文件格式,设置为hive。
source: hive
# 指定边数据导入Nebula Graph的方式,
# 指定如何将点数据导入Nebula Graph:Client或SST。
sink: client
}
# 设置读取数据库basketball中follow表数据的SQL语句。
exec: "select src_student,dst_student,guanxi from hivetest.relations"
# 在fields里指定follow表中的列名称,其对应的value会作为Nebula Graph中指定属性。
# fields和nebula.fields里的配置必须一一对应。
# 如果需要指定多个列名称,用英文逗号(,)隔开。
fields: [guanxi]
nebula.fields: [guanxi]
# 在source里,将follow表中某一列作为边的起始点数据源。
# 在target里,将follow表中某一列作为边的目的点数据源。
source: {
field: src_student
}
target: {
field: dst_student
}
# 单批次写入 Nebula Graph 的最大数据条数。
batch: 256
# Spark 分区数量
partition: 32
}
# 设置Edge 学习时间相关信息
{
name: learn
type: {
source: hive
sink: client
}
exec: "select sid ,school_id ,start_year ,end_year from hivetest.learn"
fields: [start_year,end_year]
nebula.fields: [start_year,end_year]
source: {
field: sid
}
target: {
field: school_id
}
batch: 256
partition: 32
}
]
}