- nebula 版本:v2.0.1
- 部署方式(分布式 / 单机 / Docker / DBaaS):分布式
- 是否为线上版本:Y
- 硬件信息
- 磁盘( 推荐使用 SSD): SSD 3.7T
- CPU、内存信息: 32核 128G
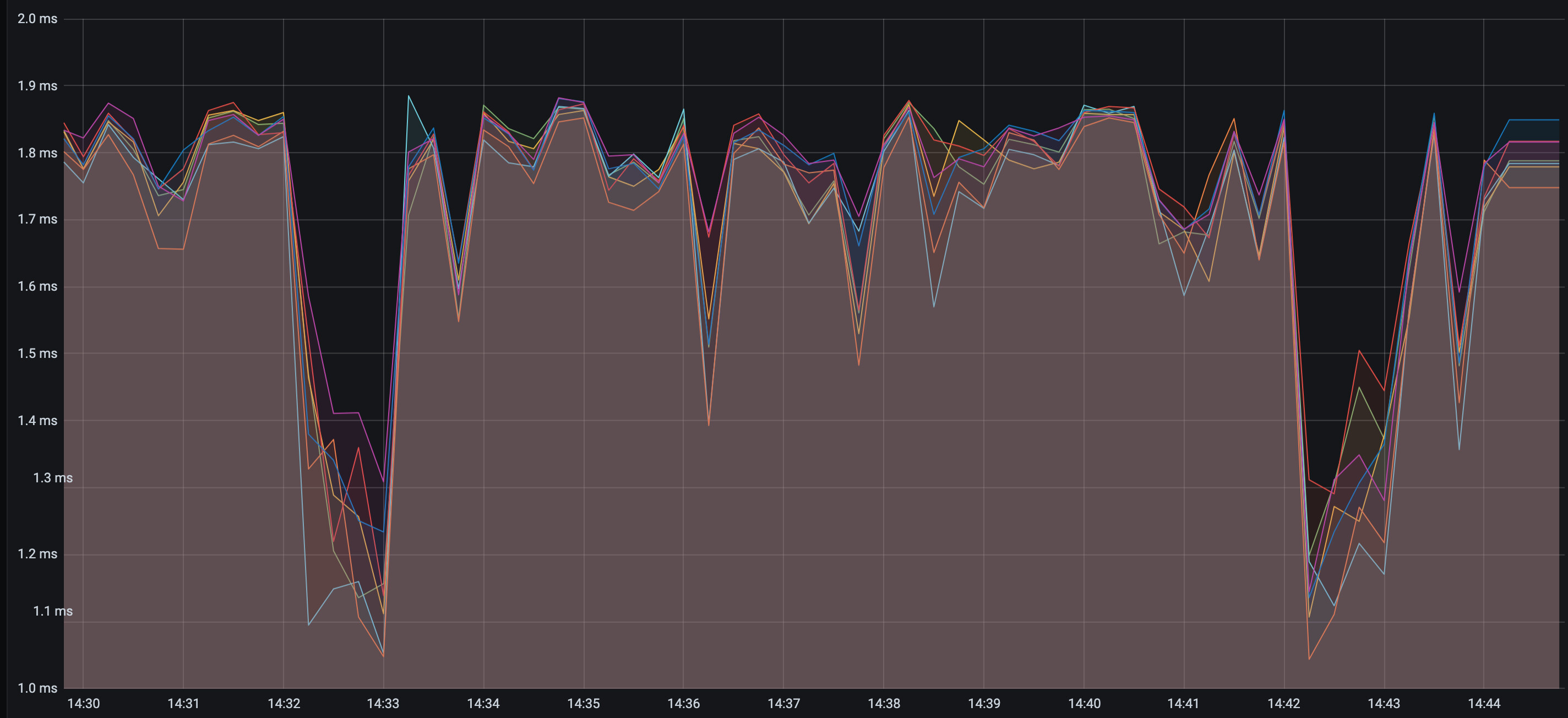
- Graphd的毛刺很多、很高,不过storaged的指标表现比较正常 (查看过log,错误基本只有vertex/edge conflict,符合预期)。想问问有什么可以调优的方向减少graphd的毛刺?
Graphd:

Storaged:
Graphd:
Storaged:
这个要看你的query,和query涉及 的数据量的。你可以看下这些毛刺是不是涉及大点,或者步长较长。
我们的场景是,数据是通过flink消费kafka消息写入,然后线上读取。
是不是开了自动 compact?
我们底层是 Rocksdb,基于 LSM tree 的。
一直写的场景,当达到触发条件,会自动 compact,然后这个时候 graphd 的 latency 就高了。
可以关闭自动 compact,然后在写不频繁的时候,手动 compact。
就是说把disable_auto_compactions设置为TRUE,然后在QPS低的时段进行手动全量compaction?
是的。
不过这样的话,没有 compact 的时候,数据都在 L0,有可能读的性能变慢。
另外 flink 是用的我们的 connector 还是自己实现的,如果自己实现的话,不要一条就请求一次。
insert 按批去插入,这样也会好一些。
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。