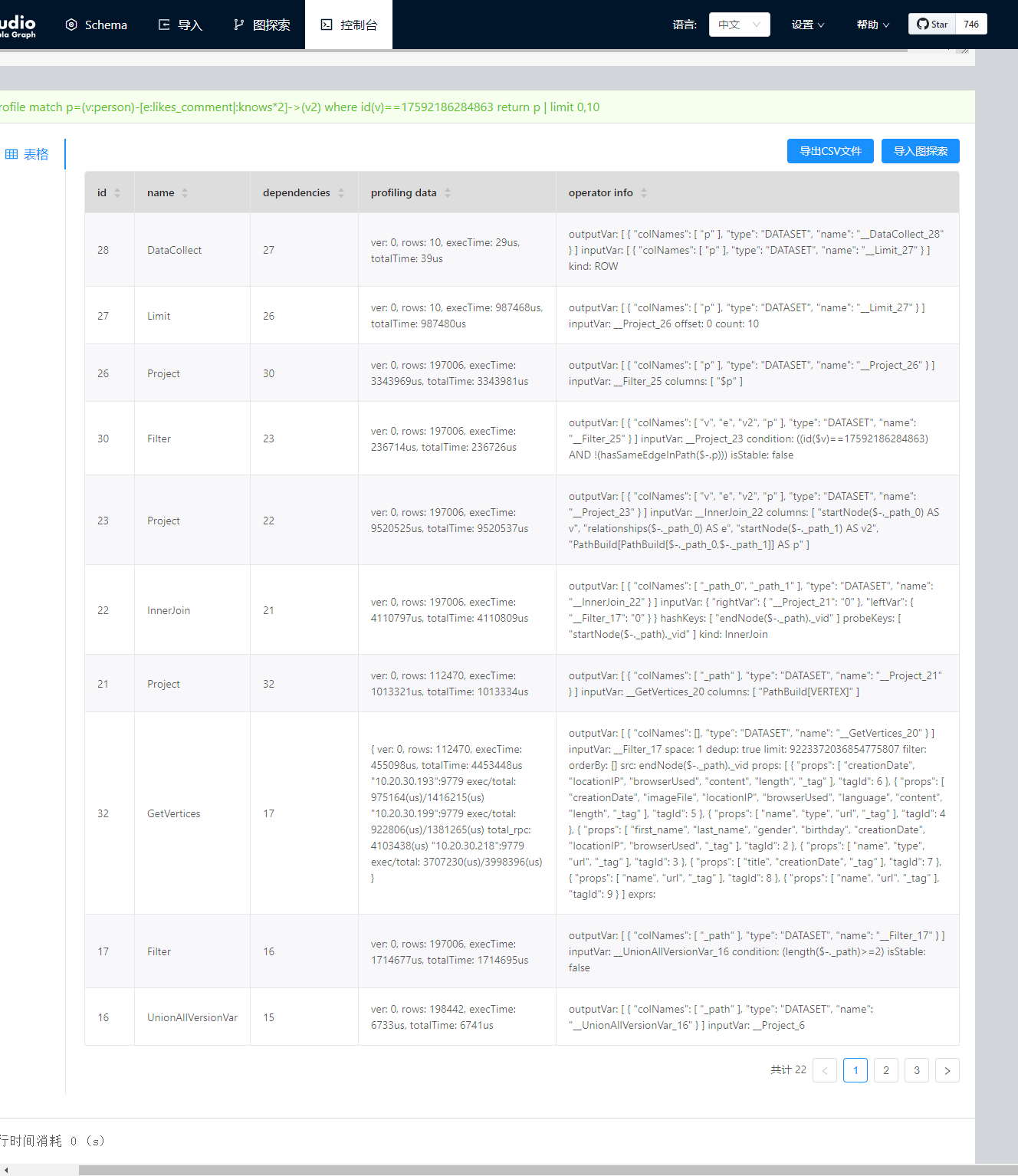
服务器环境配置:
集群部署方式:
机器名称 IP地址 graphd进程数量 storaged进程数量 metad进程数量
A **.**.**.193 1 1 1
B **.**.**.199 1 1 1
C **.**.**.218 1 1 1
A机器配置:
处理器: Intel(R) Xeon(R) Gold 6250 CPU @ 3.90GHz* 32(cores)
内存:376GB
硬盘:959.7 GB SATA
B机器配置:
处理器: Intel(R) Xeon(R) Gold 6250 CPU @ 3.90GHz* 32(cores)
内存:376GB
硬盘:959.7 GB SATA
C机器配置:
处理器: Intel(R) Xeon(R) CPU E7-4850 v2 @ 2.30GHz* 32(cores)
内存:377GB
硬盘:7198.9 GB SATA
客户端环境配置:
处理器: Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz * 8(cores)
内存: 15GB
硬盘:365GB SATA
软件配置:
测试的Nebula Graph版本:V2.5.0
数据集介绍
社交图谱数据集:Linked Data Benchmark Council · GitHub
LDBC_SNB_SF100
实体情况:8类实体,总数282385585
关系情况:25类关系,总数1775511727
分区情况:24 Partitions
副本情况:1Replica Factors

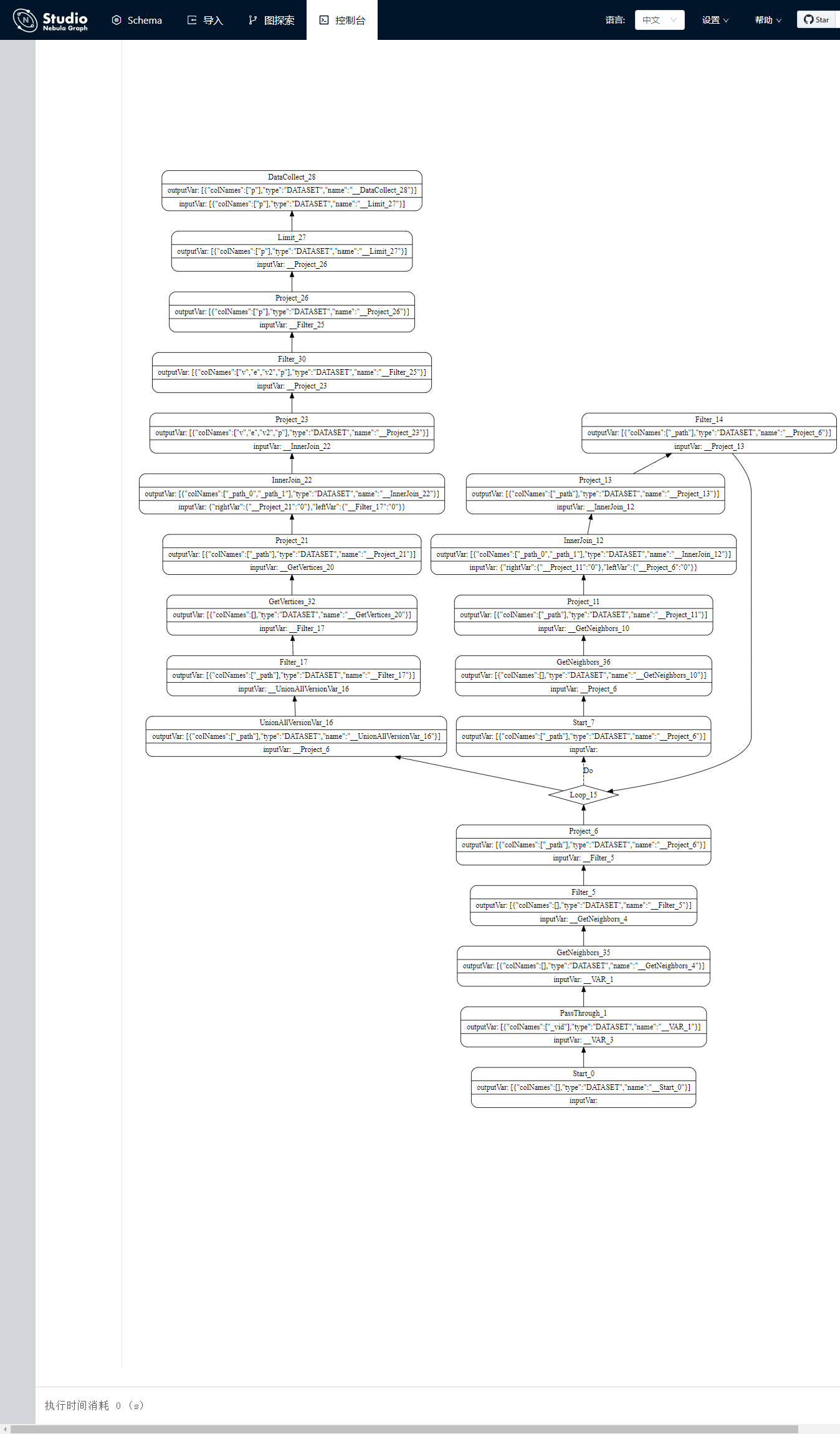
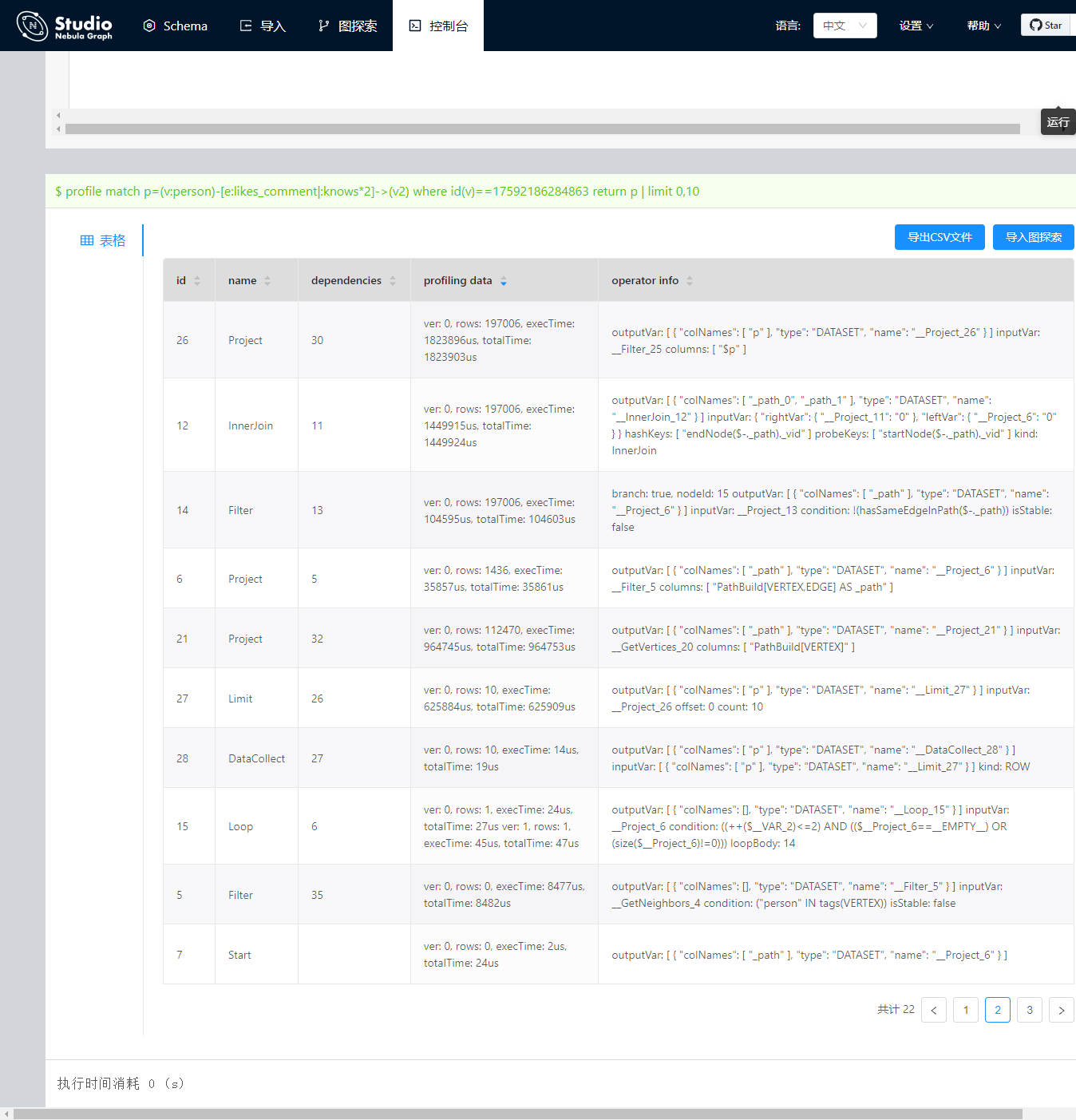
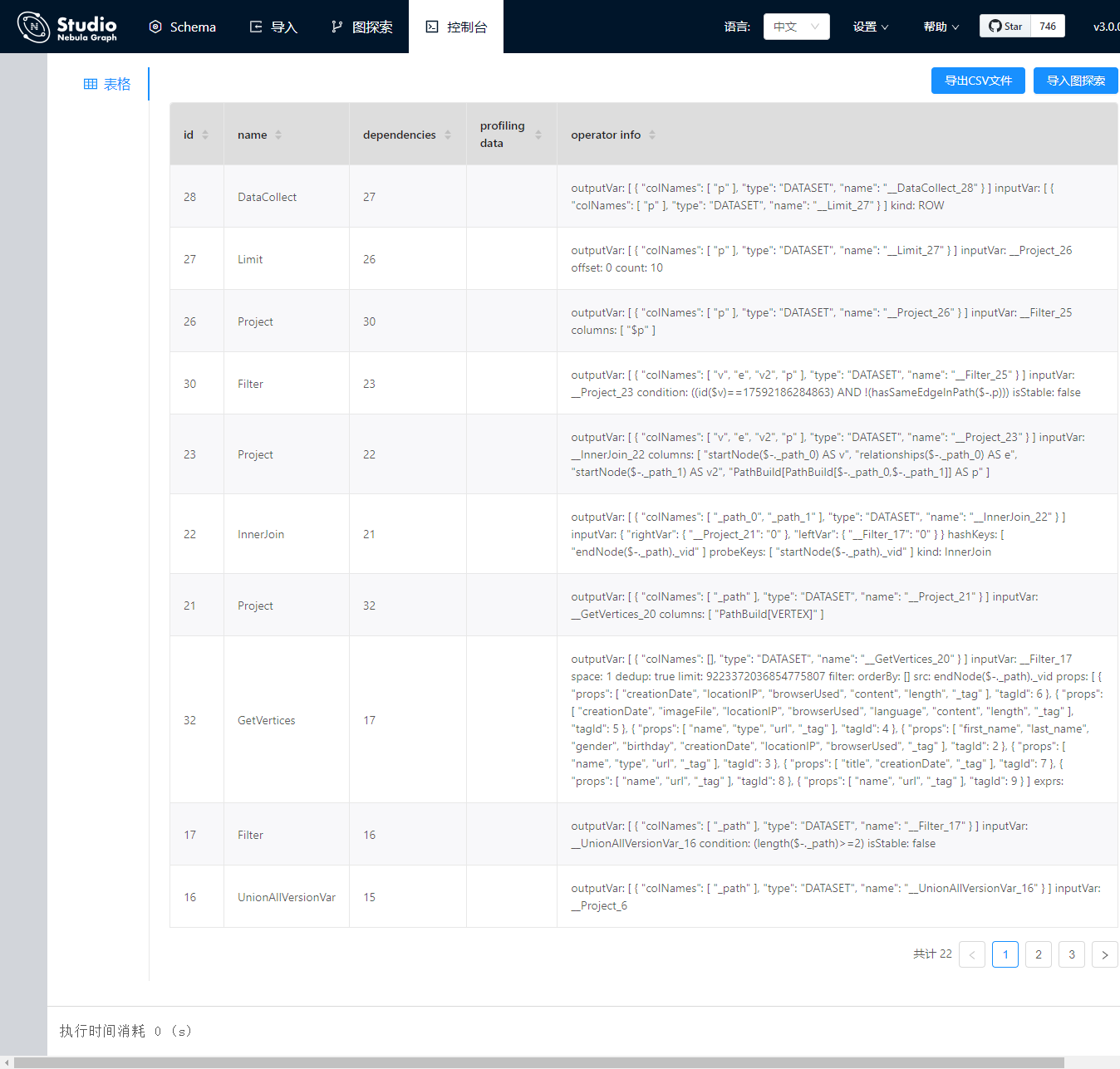
二层子图查询
10、15、20并发下,每个线程进行15分钟测试,此次查询涉及的数据量:261,898,881条
测试脚本
match p=(v:person)-[e:likes_comment|:knows*2]->(v2) where id(v)==tag1 return p | limit 0,10
测试时会随机取peson实体的id来替换上面语句的tag1.
下面以10并发为例,展示相关cpu、内存、网络带宽,磁盘使用情况
A机器:
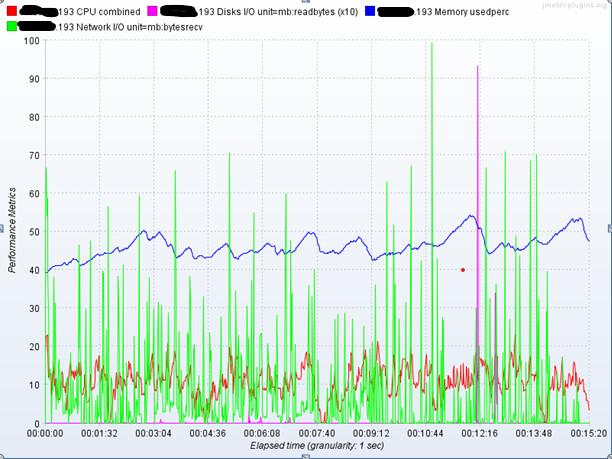
B机器:
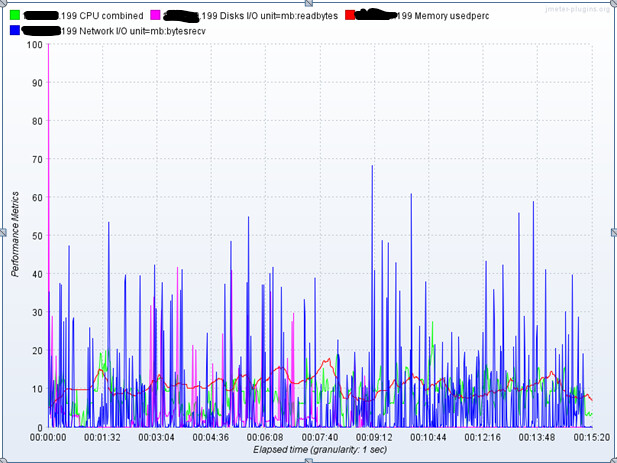
C机器:
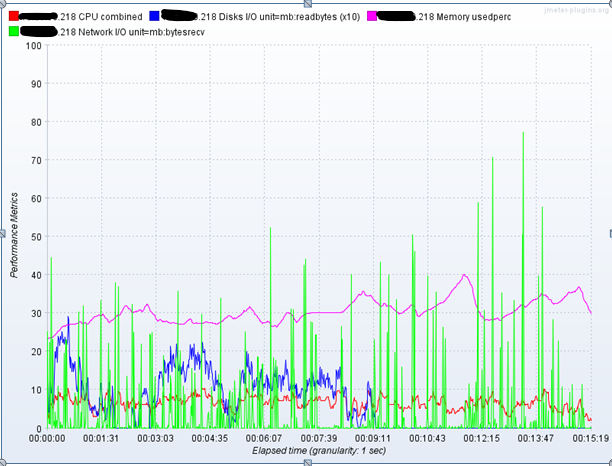
10并发情况下的聚合报告: