21/10/22 18:18:05 INFO Client:
client token: N/A
diagnostics: [星期五 十月 22 18:18:05 +0800 2021] Application is Activated, waiting for resources to be assigned for AM. Last Node which was processed for the application : hdp6509.safe.lycc.qihoo.net:8842 ( Partition : [CentOS7], Total resource : <memory:102400, vCores:40>, Available resource : <memory:48640, vCores:24> ). Details : AM Partition = <DEFAULT_PARTITION> ; Partition Resource = <memory:0, vCores:0> ; Queue's Absolute capacity = Infinity % ; Queue's Absolute used capacity = 0.0 % ; Queue's Absolute max capacity = NaN % ; Queue's capacity (absolute resource) = <memory:31457280, vCores:15500> ; Queue's used capacity (absolute resource) = <memory:0, vCores:0> ; Queue's max capacity (absolute resource) = <memory:0, vCores:0> ;
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: cloud
start time: 1634897884120
final status: UNDEFINED
tracking URL: http://mhdp12.safe.lycc.qihoo.net:8888/proxy/application_1634884768602_8924/
user: hdp-safe-cloud
21/10/22 18:18:06 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:07 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:08 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:09 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:10 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:11 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:12 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:13 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:14 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:15 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:16 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:17 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:18 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:19 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:20 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:21 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:22 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:23 INFO Client: Application report for application_1634884768602_8924 (state: ACCEPTED)
21/10/22 18:18:24 INFO Client: Application report for application_1634884768602_8924 (state: RUNNING)
21/10/22 18:18:24 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 10.160.130.163
ApplicationMaster RPC port: -1
queue: cloud
start time: 1634897884120
final status: UNDEFINED
tracking URL: http://mhdp12.safe.lycc.qihoo.net:8888/proxy/application_1634884768602_8924/
user: hdp-safe-cloud
21/10/22 18:18:35 ERROR LzoCodec: Failed to load/initialize native-lzo library
[Stage 2:> (0 + 7) / 10]21/10/22 18:19:09 ERROR TaskSetManager: Task 9 in stage 2.0 failed 4 times; aborting job
Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 9 in stage 2.0 failed 4 times, most recent failure: Lost task 9.3 in stage 2.0 (TID 15, hdp6495.safe.lycc.qihoo.net, executor 4): java.lang.NoSuchMethodError: com.google.common.base.Stopwatch.createStarted()Lcom/google/common/base/Stopwatch;
at com.google.common.util.concurrent.RateLimiter$SleepingStopwatch$1.<init>(RateLimiter.java:410)
at com.google.common.util.concurrent.RateLimiter$SleepingStopwatch.createFromSystemTimer(RateLimiter.java:409)
at com.google.common.util.concurrent.RateLimiter.create(RateLimiter.java:122)
at com.vesoft.nebula.exchange.writer.NebulaGraphClientWriter.<init>(ServerBaseWriter.scala:138)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.com$vesoft$nebula$exchange$processor$VerticesProcessor$$processEachPartition(VerticesProcessor.scala:68)
at com.vesoft.nebula.exchange.processor.VerticesProcessor$$anonfun$process$4.apply(VerticesProcessor.scala:251)
at com.vesoft.nebula.exchange.processor.VerticesProcessor$$anonfun$process$4.apply(VerticesProcessor.scala:251)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:990)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:990)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2104)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2104)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:415)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1403)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:421)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1891)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1879)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1878)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1878)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:927)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:927)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:927)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2112)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2061)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2050)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:738)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2064)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2085)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2104)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2129)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1.apply(RDD.scala:990)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1.apply(RDD.scala:988)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.RDD.foreachPartition(RDD.scala:988)
at org.apache.spark.sql.Dataset$$anonfun$foreachPartition$1.apply$mcV$sp(Dataset.scala:2741)
at org.apache.spark.sql.Dataset$$anonfun$foreachPartition$1.apply(Dataset.scala:2741)
at org.apache.spark.sql.Dataset$$anonfun$foreachPartition$1.apply(Dataset.scala:2741)
at org.apache.spark.sql.Dataset$$anonfun$withNewRDDExecutionId$1.apply(Dataset.scala:3355)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:79)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:126)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:74)
at org.apache.spark.sql.Dataset.withNewRDDExecutionId(Dataset.scala:3351)
at org.apache.spark.sql.Dataset.foreachPartition(Dataset.scala:2740)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.process(VerticesProcessor.scala:251)
at com.vesoft.nebula.exchange.Exchange$$anonfun$main$2.apply(Exchange.scala:145)
at com.vesoft.nebula.exchange.Exchange$$anonfun$main$2.apply(Exchange.scala:122)
at scala.collection.immutable.List.foreach(List.scala:392)
at com.vesoft.nebula.exchange.Exchange$.main(Exchange.scala:122)
at com.vesoft.nebula.exchange.Exchange.main(Exchange.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:852)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:927)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:936)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.NoSuchMethodError: com.google.common.base.Stopwatch.createStarted()Lcom/google/common/base/Stopwatch;
at com.google.common.util.concurrent.RateLimiter$SleepingStopwatch$1.<init>(RateLimiter.java:410)
at com.google.common.util.concurrent.RateLimiter$SleepingStopwatch.createFromSystemTimer(RateLimiter.java:409)
at com.google.common.util.concurrent.RateLimiter.create(RateLimiter.java:122)
at com.vesoft.nebula.exchange.writer.NebulaGraphClientWriter.<init>(ServerBaseWriter.scala:138)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.com$vesoft$nebula$exchange$processor$VerticesProcessor$$processEachPartition(VerticesProcessor.scala:68)
at com.vesoft.nebula.exchange.processor.VerticesProcessor$$anonfun$process$4.apply(VerticesProcessor.scala:251)
at com.vesoft.nebula.exchange.processor.VerticesProcessor$$anonfun$process$4.apply(VerticesProcessor.scala:251)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:990)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:990)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2104)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2104)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:415)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1403)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:421)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
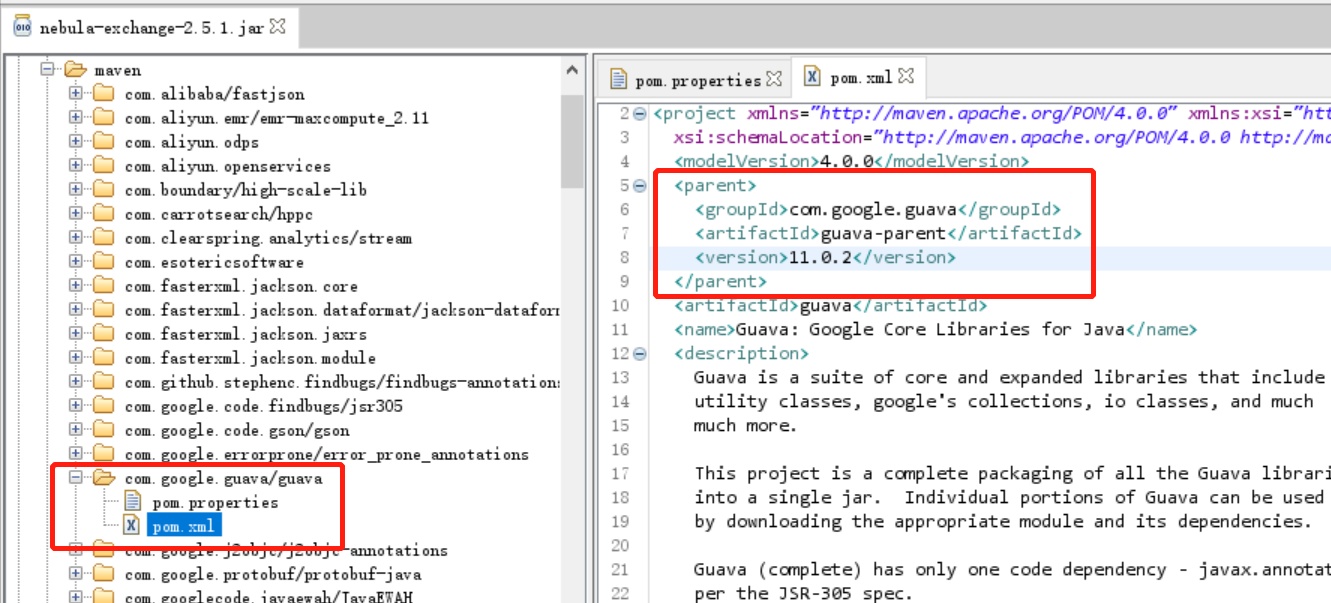
 还有其他处理方式吗?比如:提交spark任务的时候能否通过添加jar包的方式加进去,谢谢
还有其他处理方式吗?比如:提交spark任务的时候能否通过添加jar包的方式加进去,谢谢