- nebula 版本:2021.10.28_nightly
- 部署方式 :单机
- 是否为线上版本:N
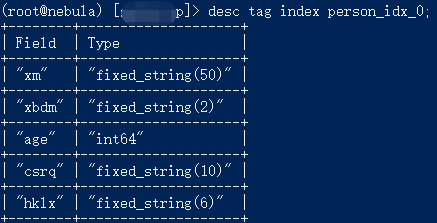
索引如下图所示:
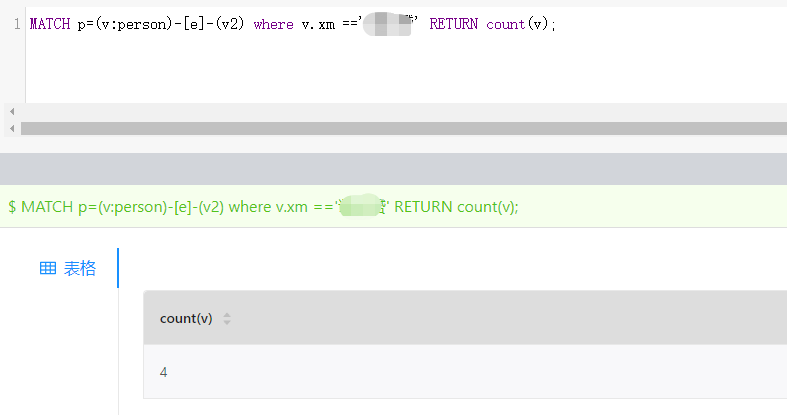
使用索引第一个字段xm,MATCH正常查询,如下图所示:
当使用索引第二字段xbdm,MATCH报IndexNotFound
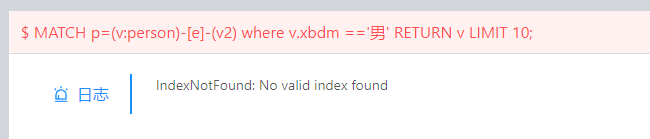
MATCH p=(v:person)-[e]-(v2) where v.xbdm =='男' RETURN v LIMIT 10;
索引如下图所示:
使用索引第一个字段xm,MATCH正常查询,如下图所示:
当使用索引第二字段xbdm,MATCH报IndexNotFound
MATCH p=(v:person)-[e]-(v2) where v.xbdm =='男' RETURN v LIMIT 10;
嗯,v2.6.0 里面是有这个功能,你 Studio 的版本号是 nightly 的吗?可能是版本不匹配导致的。
Studio 是3.1.0的,但是我觉得执行nGQL跟Studio的版本应该没关系。另外console也是一样报错
组合索引现在依然是最左拼配,而且只能是最左匹配。底层使用的是 prefix 的查找。所以如果是组合索引,只有中间的字段的过滤条件是不会选中 index 的。
这版本做的一个优化是,如果只有组合索引,但是过滤条件中使用了最左边的单个属性过滤,是可以选中组合索引,在 2.5.0 之前的版本要求组合索引严格匹配。但原则还是没变,查组合索引还是只能从最左边依次开始。
这种约束导致MATCH查询不够灵活,希望后续版本能够改进。比如,我想基于姓名查询,把姓名作为索引第一个字段,然后当我想基于性别、年龄查询的时候,还得另外再建N个索引…
另外,顺便提一下es索引也是非常多的约束,我们目前是自行维护
索引选择这块的优化目前正在做优化,但是如果要经常根据不同的字段来查询,更建议使用单个属性来建索引。后续会把 es 的部分索引的功能下沉到主库中,比如常见的 ends with,contains,wildcard 等。
在 GitHub 中有相关的 issue 进行跟踪,这个版本迭代中会解决:
https://github.com/orgs/vesoft-inc/projects/29/views/1?filterQuery=index
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。