- nebula 版本:2.5.1
- 部署方式:分布式
- 安装方式:RPM
- 是否为线上版本: N
- 硬件信息
- 磁盘( 推荐使用 SSD)
- CPU、内存信息
- 问题的具体描述
您好 请教一个问题
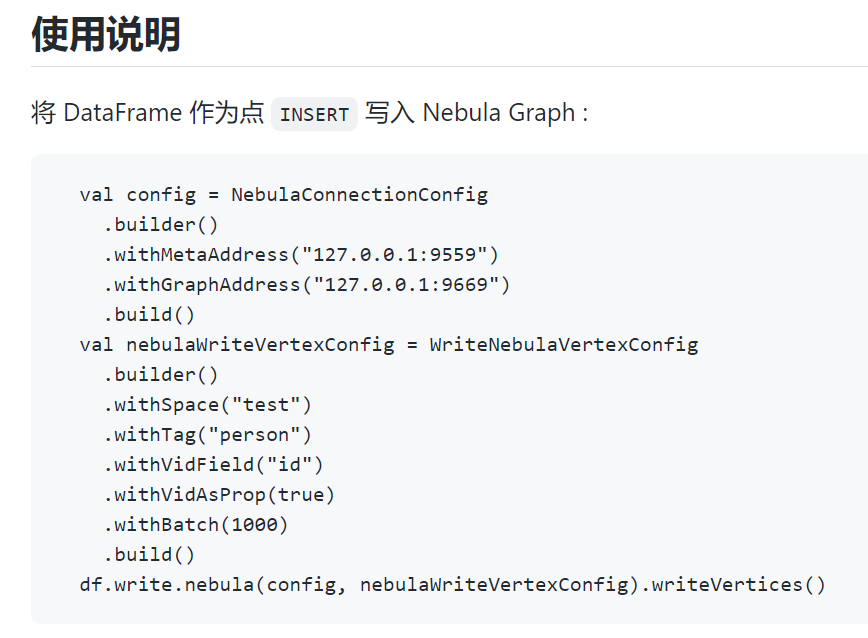
这边使用的Spark Connector相关例子代码入下(Nebula官网给出的):
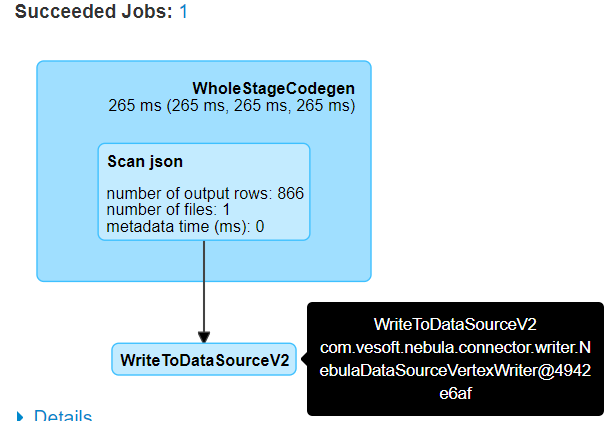
我这边用java实现的方式为:

图中vertexData为Spark读入的DataFrame

我的理解是这段代码是将图中vertexData批量写进Nebula中
但请问这是已经通过Spark分布式的方式写入了嘛?就是你们这个内部已经封装好了吗?
还是说这个writeVertices函数还是只是非分布式写入,如果我要是对vertexData进行分布式写入,我还是需要自己写类似:
vertexData.foreachPartition(图中的insertVertexes函数)
就是把vertexData手动分开并分别执行writeVertices函数呢?
谢谢