- nebula 版本:2.0.1
- 部署方式:分布式 ,三节点三副本
- 安装方式: RPM
- 是否为线上版本:Y
- 硬件信息
- 磁盘 SSD 3T
- 内存300G
- 问题的具体描述
线上的部署了三个节点,graphd进程经常挂掉,目前是因为OOM导致的,有没有办法定位到哪个时间点,哪条执行语句导致的。前期因为match语句很慢,后面关联查询全部改成go了,部署的这个图库,会有大批量的调用,一秒钟可能会有几十个甚至上百个请求调用。
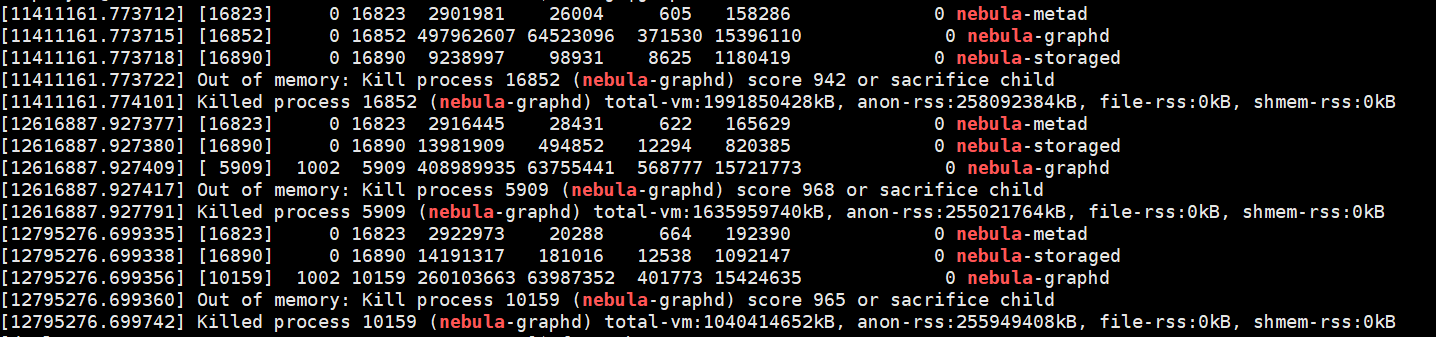
graph的log里应该有挂掉前最后一个query吧?
建议有条件的话升级到v2.6.1啊,2.0.1升级上来没难度,通过设置内存水位可以基本避免Graph OOM。
2 个赞
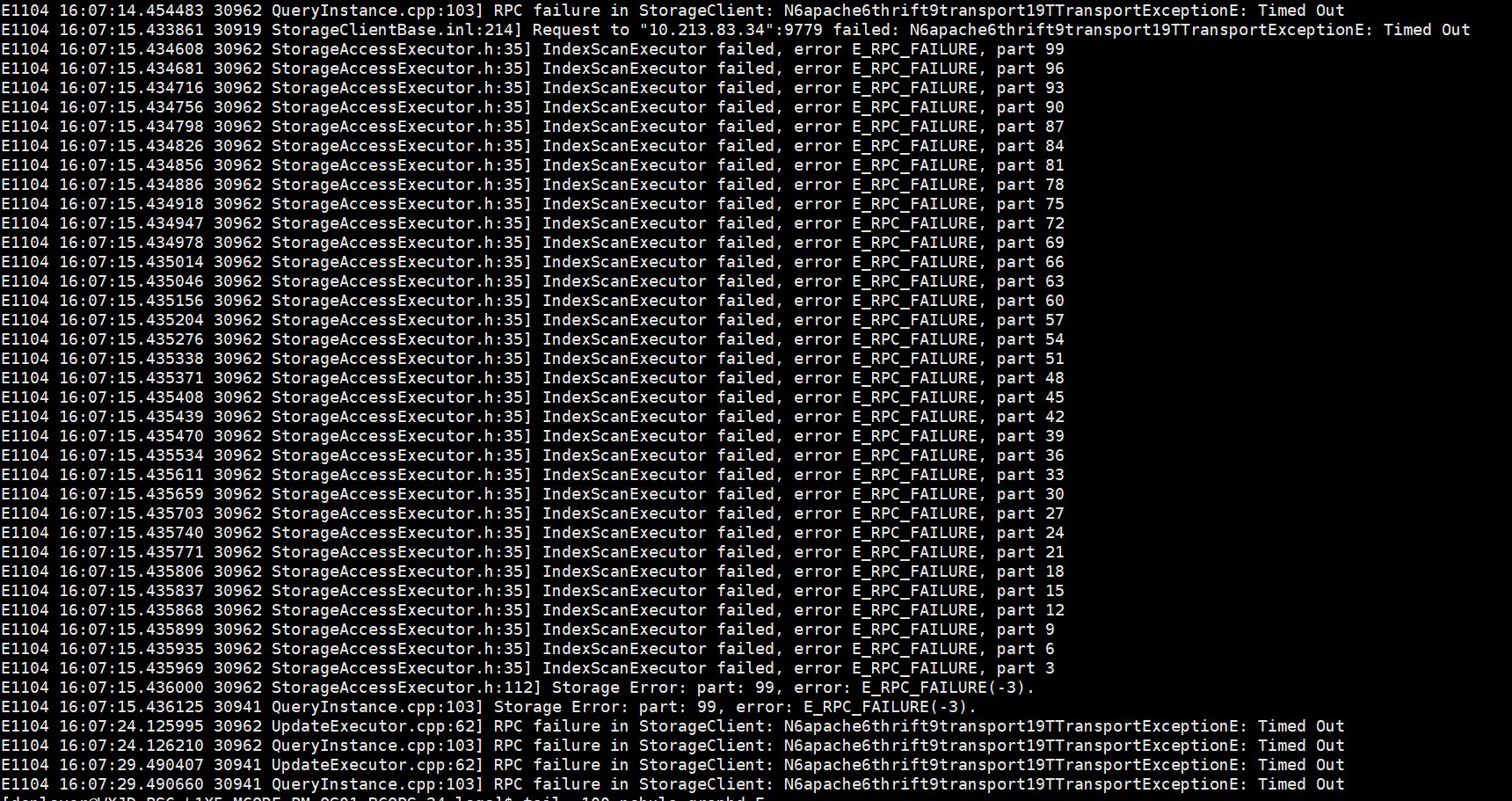
看起来像是执行 match 或者lookup 产生的错误
可以重点关注下,最近执行的match 语句
日志里面会不会记录执行的查询语句呢?关键线上的请求量比较大
前期用match查询,对于跨多层的确实很方便,但是查询速度超级慢,甚至超时。后期全部改成go,基于管道,一层层拼接查询,但是go只能基于确定的点做查询。比如我想查主机的ip为XXX的主机关联的物理网卡,关联的物理端口,关联的网络设备,这种跨多层的。所以我第一层用lookup做条件查询,后面每层用go做拼接。类似的查询语句如下:
$var0 =LOOKUP ON host where host.bk_host_innerip =="*****" yield host.bk_host_innerip as host_bk_host_innerip, host.bk_host_name as host_bk_host_name;
$var1 =go from $var0.VertexID over asst where $$.physical_nic.bk_obj_id == "physical_nic" yield asst._dst as VertexID,$var0.host_bk_host_innerip as host_bk_host_innerip,$var0.host_bk_host_name as host_bk_host_name,$$.physical_nic.bk_inst_id as physical_nic_bk_inst_id;
$var2 =go from $var1.VertexID over asst where $$.ecloud_port.bk_obj_id == "ecloud_port" yield asst._dst as VertexID,$var1.host_bk_host_innerip as host_bk_host_innerip,$var1.host_bk_host_name as host_bk_host_name,$var1.physical_nic_bk_inst_id as physical_nic_bk_inst_id;
$var3 =go from $var2.VertexID over asst REVERSELY where $$.ecloud_net_device.bk_obj_id == "ecloud_net_device" yield asst._dst as VertexID,$var2.host_bk_host_innerip as host_bk_host_innerip,$var2.host_bk_host_name as host_bk_host_name,$var2.physical_nic_bk_inst_id as physical_nic_bk_inst_id,$$.ecloud_net_device.bk_inst_name as ecloud_net_device_bk_inst_name;
yield $var3.host_bk_host_innerip as host_bk_host_innerip,$var3.host_bk_host_name as host_bk_host_name,$var3.physical_nic_bk_inst_id as physical_nic_bk_inst_id,$var3.ecloud_net_device_bk_inst_name as ecloud_net_device_bk_inst_name| order by host_bk_host_innerip| limit 0,10
应该是日志级别的问题,设成INFO,v=1才可以看到,不过你们生产环境够呛。
部署了三个节点,大批量的请求过来,图库是怎么分配这些请求的?三个节点的graphd都挂掉了,我依次恢复,然后发现所有的请求都在一个节点上。我看了一下执行语句,会有很多upsert的操作,还有跨层的查询,没过多长时间这个节点的graphd又挂掉了。
负载均衡这块要看你们前端是如何访问Nebula的,通常来说在建session pool的时候可以把三个graph节点的地址都加上, 这样会有简单的round robin,或者你们可以直接在前端加个自己的load balancer来处理。


代码看上去好像没啥问题,有可能还是版本问题
看到 https://github.com/vesoft-inc/nebula-java/releases/tag/v2.5.0 里有一个feature:
Session supports reconnecting to different graph services
还是考虑升级下吧?
最近发现,执行match where count语句,graphd OOM,数据量不大,才900M,这是什么原因啊
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。