本文整理自 DTCC 主题演讲【开源分布式图数据库的思考和实践】
目录
目录
- 图数据库市场的现状
- 图数据库的优势
- 以 Nebula Graph 为例
- 开源社区
图数据库市场的现状
开篇之前,先回顾下图数据库市场变化,2018 年前市场大概是 $ 650,000,000,根据目前市场的研究报告,图数据库市场将在未来的 4 年以年增长 30%~100% 的速度达到 $ 4,130,000,000~$ 8,000,000,000。

而整个图数据库市场的发展,从公开资料上来看,Graph Database(图数据库) 概念最早是 Gartner 在 2013 年提出的。而当时比较重要的 2 个参与者是——Neo4j 和 TitanDB,后者被收购后诞生了 JanusGraph。一般来说一个事物发展到一定阶段会开始走下坡路,不过图领域目前来说还是处于蓬勃发展阶段,在 2021 年 Gartner 的数据和分析十大趋势中,图还是占有一席之地。Graph relate everything,相比传统数据库,它的拓展范围更大,包括:图计算、图处理、图深度学习、图机器模型等等。

下面这张图是做数据库排名的 DB-Engine 给出的数据库增长趋势,可以见到图数据库是近 10 年来关注度增长最快的数据库。表的数据来源于社交媒体,例如:LinkedIn、Twitter 提及某个技术点的次数,以及 Stack Overflow 上面相关问题数、搜索引擎搜索趋势。

图数据库的优势
一般来说,图相对别的数据库,最明显的优势便是直观。下面是一个权力游戏人物关系的表结构图和图结构图:

(表结构)

(图结构)
还有一个是表达简洁,在同样的数据模型(下图)

实现:找一定的时间范围内,总共发了多少 posts,各自被回复多少次并对结果进行排序,SQL 的编写可能是这样的:
--PostgreSQL
WITH RECURSIVE post_all (psa_threadid
, psa_thread_creatorid, psa_messageid
, psa_creationdate, psa_messagetype
) AS (
SELECT m_messageid AS psa_threadid
, m_creatorid AS psa_thread_creatorid
, m_messageid AS psa_messageid
, m_creationdate, 'Post'
FROM message
WHERE 1=1 AND m_c_replyof IS NULL -- post, not comment
AND m_creationdate BETWEEN :startDate AND :endDate
UNION ALL
SELECT psa.psa_threadid AS psa_threadid
, psa.psa_thread_creatorid AS psa_thread_creatorid
, m_messageid, m_creationdate, 'Comment'
FROM message p, post_all psa
WHERE 1=1 AND p.m_c_replyof = psa.psa_messageid
AND m_creationdate BETWEEN :startDate AND :endDate
)
SELECT p.p_personid AS "person.id"
, p.p_firstname AS "person.firstName"
, p.p_lastname AS "person.lastName"
, count(DISTINCT psa.psa_threadid) AS threadCount
END) AS messageCount
, count(DISTINCT psa.psa_messageid) AS messageCount
FROM person p left join post_all psa on (
1=1 AND p.p_personid = psa.psa_thread_creatorid
AND psa_creationdate BETWEEN :startDate AND :endDate
)
GROUP BY p.p_personid, p.p_firstname, p.p_lastname
ORDER BY messageCount DESC, p.p_personid
LIMIT 100;
用 Cypher(图查询语言)表达的话,仅用下面语句即可:
--Cypher
MATCH (person:Person)<-[:HAS_CREATOR]-(post:Post)<-[:REPLY_OF*0..]-(reply:Message)
WHERE post.creationDate >= $startDate AND post.creationDate <= $endDate
AND reply.creationDate >= $startDate AND reply.creationDate <= $endDate
person. RETURN
id, person.firstName, person.lastName, count(DISTINCT post) AS threadCount,
count(DISTINCT reply) AS messageCount
ORDER BY
messageCount DESC, person.id ASC
LIMIT 100
在查询这块,图查询的表达方式更简洁。
此外,图本身的生态也相当丰富,下面为 2020 年的图技术全景图,而在 2021 年新增的技术点会更多。

以 Nebula Graph 为例
下面以 Nebula 为例,介绍下分布式图数据库 Nebula Graph 特性,以及开发过程中遇到何种技术挑战、研发团队又是如何处理这种技术挑战。
在 19 年 5 月底开源之前,18 年年底开始设计 Nebula Graph 雏形时,研发团队定了 4 个目标:规模、生产、OLTP、开源生态,而这 4 个目标直至今日依旧影响 Nebula Graph 产品规划。
Nebula Graph 设计的第一个要点是:规模,同其他竞品设计初衷不大一样,Nebula Graph 一开始设计时,考虑到数据库未来处理的数据规模一定会很大——摩尔定理总是快不过数据增长,而单机情况并不能很好地应对海量数据以及未来的数据增长,继而转向研究分布式数据库是如何处理数据。所以说,Nebula Graph 的设计是针对生产工业级别的数据量:万亿点边数据量。在数据规模大的情况下,整个图数据分析属性得多,不同于另外一种只做图结构、不做图属性的图数据库设计,Nebula Graph 开始的设计便是:大规模的属性图,支持上百属性,用户可在具体场景上落地 Nebula Graph 实践。
第二点是生产,除了第一点提到的工业级别可用之外,还有查询语言如何设计、可视化、可编程、运维要求。
第三点是 OLTP,当时的设计目标优先考虑 TP 场景,即使到今天也是一样,Nebula Graph 是一个非常关注 TP 场景的图数据库,即:它是一个在线、高并发、低延迟的图数据库。一般来说互联网的业务场景对这块的需求比较多,比如说你的一笔转账交易支付时,系统可能要检测一下是否安全,这个处理时间可能是几十毫秒左右。
最后一点开源,除了构建技术社区、开发者生态之外,主要还考虑了对接其他大数据生态,以及同图计算、训练框架进行结合。

这是目前 Nebula Graph 的生态图,红色为内核部分,分为 meta、graph、storage 三个模块,下文会详细讲解。内核部分上层为查询语言,除了自研的 nGQL 之外,还兼容了 openCypher。再上层为客户端,目前支持 Java、C++、Python、Go 等等语言。而客户端上层为可编程 SDK,最上层为大数据生态支持层,比如常见的 Spark、Flink,图计算 GraphX、Plato,还有其他数据源迁移工具。左侧为云部署、可视化、监控模块,右侧主要侧重数据安全,比如说:数据备份、多机房部署…,还有同工程相关的 Chaos 以及性能压测,最右侧是社区和开发者相关的内容。
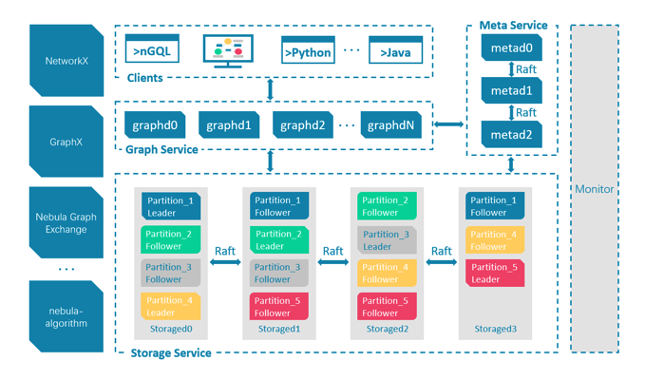
来详细讲述下 Nebula 核心设计,主要包括 meta、graph、storage,右上角的 meta 主要是元数据,中间的 graph 是查询引擎部分,下面的 storage 是存储引擎,这三个模块进程分离,存储计算分离的设计也体现了之前说到的 Nebula Graph 设计之初考虑规模大这一点。
详细地来说,元数据模块(Meta Service)主要用于管理 Schema,Nebula Graph 的 Schema 不是完全 Schema freee 的设计,主要体现为点和边的属性是需要预先定义。此外,space 管理、权限管理、长耗时任务管理、数据清理等等管理都是在 meta 模块进行。在具体使用中,meta 一般部署 3 个节点,这 3 个节点进行强同步。存储引擎层 Storage Service 是多进程系统,多个进程之间做一个强同步。
上文说到 Nebula 支持万亿规模的点边数据量,肯定要对图切片。一般来说图切片分为两种:切点、切边。Nebula Graph 的设计是切边,将点放在 Partition 上,边的出边和入边也放在各自的 Partition 上,然后把这个切成 100 甚至 1000 个 Partition 都可以,Partition 是细粒度模块,服务于每个进程。每个 Partition,比如 Partition 1 可能会有 3 副本,落在不同的机器上,Partition 2 落在不同的 3 台机器上,每个 Partition 内部保持强一致,如果要进行调度,将某个 Partition 移开。
存储引擎上面是查询引擎层,查询引擎是无状态的,即:所有数据 Graph Service 要么从 meta 拉元数据,要么去 storage 拉主数据。查询引擎本身不存在状态,引擎相互之间不存在通信,某个查询过来只会落到某个 graphd 上,而这个 graphd 会落到多个 storaged 上。
以上就是 Nebula Graph 存储计算分离架构讲解。
下面为数据特性,上文说过 Nebula Graph 为属性图,虽然点和边的连接关系弱,但是本身点边自个拥有什么属性是 DDL 预先定义好的,当然你可以设置多版本 Schema。在 Nebula Graph 中称点类型为 Tag,边类型为 EdgeType,点可以连接多条边。用户使用 Nebula Graph 需要预先指定唯一标识,比如 int64 或者定长 string,点通常使二元组来标识,即:string vid 加上点类型 tag。边则用四元组来标识,即:起点、边类型、rank 和终点,所以如果要取 ID 的话,会取出来二元组或者四元组。
在数据类型方面,常见的 Boolean、Int、Double 之类的数据类型,或者是组合类型 List、Set,或者是图常见 Path、Subgraph 类型都支持。在数据属性中可能会存在长文本,一般来说交给 Elasticsearch 进行文本索引处理。
这里对之前的存储引擎进行补充说明,对外对于查询引擎 graphd 而言,存储引擎暴露的对外接口就是分布式图服务,但如果需要的话,也能暴露为一个分布式 KV 服务。在存储引擎中,Partition 采用多数派一致性协议 Raft。在 Nebula Graph 中点边是分区存储,这里讲解下 KV 实现分区存储原理:
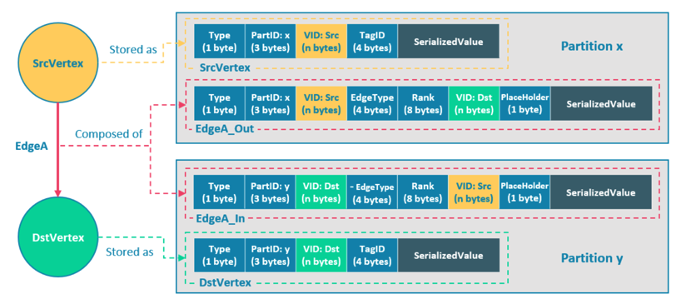
上图是一个简单的图:起点、边、终点,现在用 KV 建模,上面是起点 K 的建模,下面是终点 K 的建模,Value 部分是序列化属性。上面例子将起点和终点做成了 2 个 K,一般来说出现三个图元素(两个点加一条边),数据存储会落在 2 个不同的 Partition 上:出边和起点存储在一块,入边和终点存储在一块。这样设计的好处在于,从起点开始的广度优先遍历找边会非常方便,或者终点开始进行逆向广度遍历找出起点也会非常方便。
所以上面说的就是图切边操作:
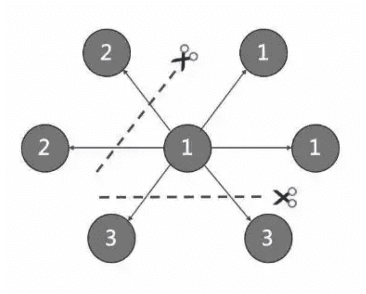
在 Nebula Graph 中一条边存储为 2 份数据,前面提及存储层依赖于 VID,基于 Raft 协议保障强一致性,而 Raft 也可以支持 Listener 角色用来将数据同步到其他进程。
再来讲解下 Nebula 功能,比如:索引功能,目前 Nebula Graph 用 ES 来做全文索引,在 v2.x 版本开始,研发团队对 Nebula 索引的写性能进行了优化。在 v2.5.0 开始也支持了数据过期 TTL 功能和索引功能的组合使用。此外还有 TOSS 功能,在 v2.6.0 版本开始,Nebula 支持了正反向边的最终一致性,插入、修改边时,正反边要么同时写入成功,要么同时写入失败。
在查询引擎和查询语言 nGQL 方面,图数据库查询这块目前是没有统一的标准,目前主要分为 2 个流派:由 Neo4j、TigerGraph、Oracle、Google、LDBC 组织机构正在推进的 Graph Query Language 的国际标准,主要是基于 ISO SQL 标准上的扩展;以及 Tinkerpop 的 Gremlin,这是 Apache 那边的标准,一般云产商和程序员对此比较感兴趣。目前来说,六月份 IOS SQL 组织的草稿文献表明 GQL 标准的语法和语义已经大体确定,主要的几个数据库厂商达成了一致。个人预计明年可以看到公开的文本。
再来说下 Nebula Graph 的整个图查询语言 nGQL 的演变,在 v1.x 版本中,查询语言是完全自研的,类似 GO STEPS 这样风格,多个子句用 PIPE 进行连接,比如下面的例子:
GO N TO M STEPS FROM $ids OVER $edge_type WHERE $filters | FETCH PROP
在 v2.x 开始,nGQL 开始兼容 openCypher。openCypher 是 Neo4j 在 17 年开源了部分的 Cypher 语言,目前 nGQL 支持 openCypher 的 DQL(tranversal、pattern match),在 DDL、DML 这些方面,v2.x 版本还是保留了自己原生的 nGQL 风格。
上文提到 Nebula Graph 的四个设计目的有一个点是:生产可用,在运维这块就得考虑对多图空间进行数据隔离、用户权限鉴定、副本自定义、VID 类型不同…此外,在集群级别可以采用多数派一致性协议实现 CAP 中的 CP 方案,也可以跨机房实施 AP 方案。还有运维部署方面,4 月底发布的 Nebula Operator 支持了 K8s。在运维监控方面,除了 Nebula 研发团队开发的 Nebula Dashboard 之外,社区的用户也在不同程度上对 Grafana、Prometheus 做了支持。数据初始化这块非常丰富,因为 Nebula Graph 底层用了 RocksDB,RocksDB 可以直接在 Spark 集群上将底层数据格式算好,比如说,你在 300 台 Spark 机器中算好数据格式,再导入 Nebula Graph 中,每个小时可以很快地更新一千亿点边数据。
关于性能部分,大多数 Nebula 性能测试都是社区用户,比如美团、微信、360 金融、微众银行之类的技术团队在做性能测试。Nebula Graph 的性能测试报告,一般是自身版本性能对比,基于公开的 LDBC_SNB_SF100 数据集,大概结果可以参考下面这几张图:

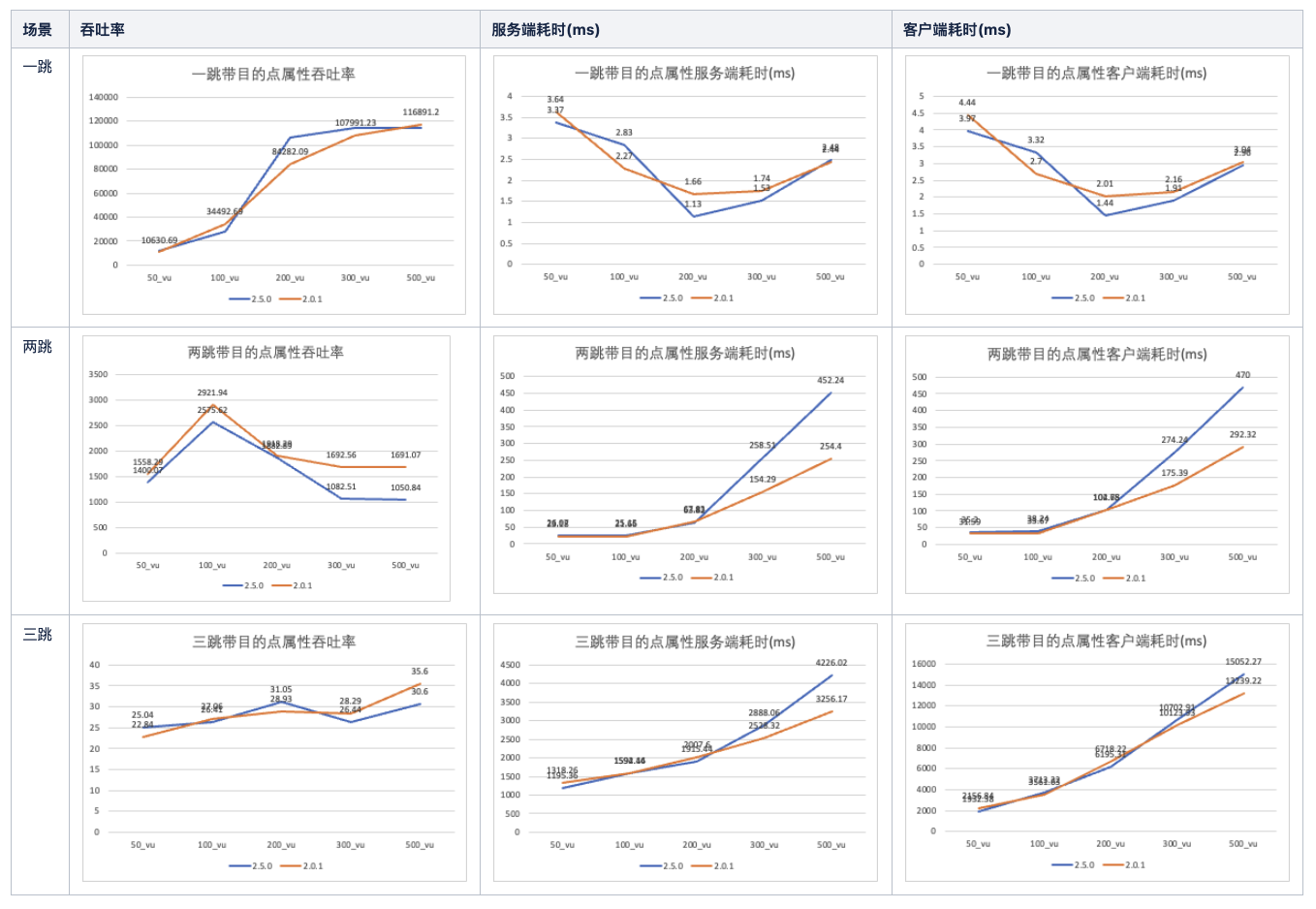
总的来说,深度遍历情况下性能有明显提升。
上文提到 Nebula Graph 的第三个设计目标是 OLTP,那么如何满足用户的 AP 需求呢?在这块 Nebula Graph 对接了 Spark 的 Graph X,以及支持腾讯微信团队图计算引擎 Plato。在 Plato 对接这块,其实是两套引擎的数据打通,需要将 Nebula 内部的数据格式变成 Plato 中内部的数据格式,Partition 做一一映射,相关的文章将在公众号后续发布。
开源社区
最后部分为 Nebula Graph 的社区情况,下图为 Nebula Graph 研发商欧若数网的一个年表:
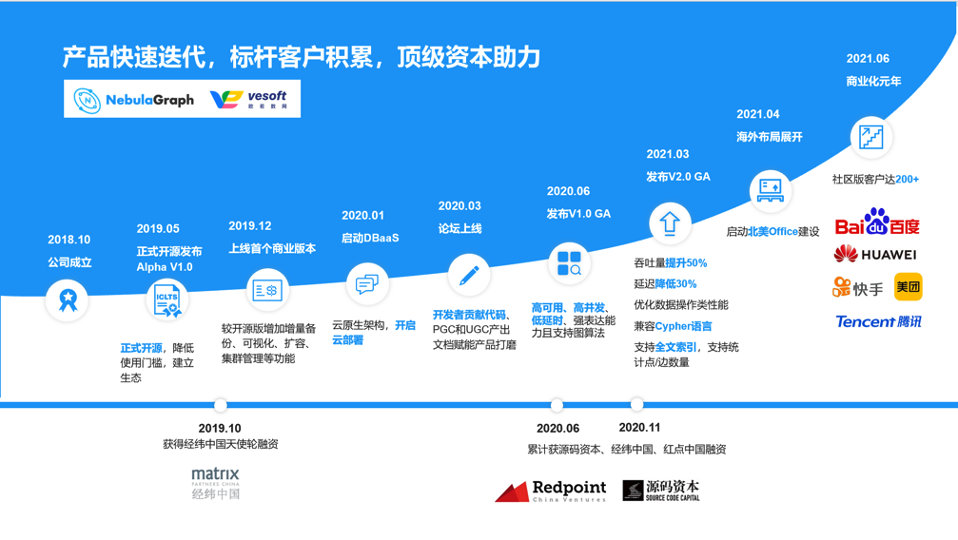
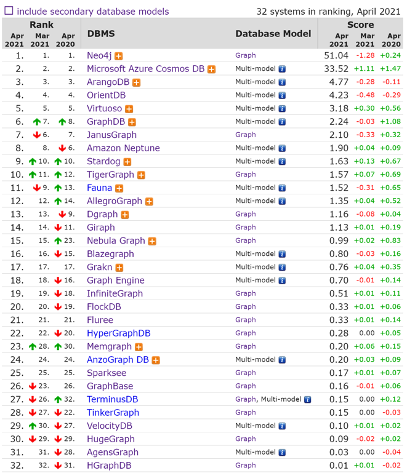
Nebula Graph 项目在 19 年 5 月开源并发布了 Alpha 版本,20 年 6 月发布 1.0 GA 版本,虽然之前已经有些企业用户将 Nebula Graph 应用于生产环境。在今年 3 月发布了第二个大版本 v2.0 GA,对比之前的 1.x 版本最大的区别是支持了 openCypher。上文也提到过 DB-Engines 排名,Nebula Graph 在 19 年 12 月进入榜单,当时是最后一名目前 2 年之后上升到 15 名:
然后是国内的某个大学对国内开源产品进行了个社区热度排名,Nebula Graph 研发商欧若数网(vesoft)排名第八。

最后,讲下对开源的思考:其实在图领域,开源是一件很常见的事,反而闭源并不常见。因为图本身在过去几年是个小领域,只是最近慢慢地火起来。所以,选择开源是一个挺好的 Branding,建立自己技术品牌的方式。再者,开源的方式可以吸引更多的人来用它,同更多的人交流图技术,促进彼此思考。以及,在用户使用过程中,反馈过来的使用建议能迭代、快速完善产品。
QA
下面摘录 DTCC 现场用户提问:
Q:图数据库和多模数据库是冲突的吗?二者的关系是什么?
A:相比来说多模数据库(multi-model),图数据库最大的特点是在于它的全关联,如何实现多跳查询。对应到数据库设计的话,就是考虑底层要做成一个什么样的数据格式,数据和计算怎么放在一起,这个和 multi-model 本身是不冲突的。为了提升性能,各个多模数据库处理方法并不一样:采用不同的存储引擎,或者是同一套存储引擎,数据结构可能会做成不同的样子。
Q:图查询设计的出发点是什么?为什么不考虑一开始基于 Gremlin 开发?
A:对于数据分析的同学,Gremlin 并不是一个低门槛语言,有些不友好。当时 Gremlin 的设计实现要求每个算子发出来之后必进行执行出来结果,举个例子,我现在要做一个 .out 和 .in,我必须得先执行 .out 再进行 .in,这样就不能进行一个全局优化。而 18 年的时候,openCypher 并不完善,小问题有些,表达力不行需要 APOC 进行补充,而 APOC 法律协议并不像 openCypher 那么确定,所以基于此,我们自研了 nGQL。在 19 年开始,GQL(查询语言标准化)运动开始了,GQL、Cypher 和 openCypher 关系比较明显,所以演变成了现在的 nGQL。
本文中如有任何错误或疏漏,欢迎去 GitHub:https://github.com/vesoft-inc/nebula issue 区向我们提 issue 或者前往官方论坛:https://discuss.nebula-graph.com.cn/ 的 建议反馈 分类下提建议 ![]() ;交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
;交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~